Introduction
本文的贡献:提出了基于视频的行人重识别模型:Appearance and Motion Enhancement Model(AMEM)。该模型对两类信息进行提取:提出了Appearance Enhancement Module(AME),采用行人属性学习提取行人的样貌特征;提出了Motion Enhancement Module(MEM),提取行人的步态特征,并对其行走进行预测。
在预测阶段仅使用提出模型的主干网络和两个特征提取模块。
Approach
(1)整体框架:
输入视频序列,通过backbone网络提取出特征,然后通过AEM和MEM模块加强了特征中的外貌和动作信息,最终只使用主干网络和两个模块进行特征距离评估。

一些关键的参数定义:
S = {I1, I2, ..., IT} 表示输入的视频序列,每个视频序列含有 T 帧;
y 表示行人的身份标签;
BF = Ø(S, θB) 表示通过backbone网络的特征提取函数(BF为 T' * C * H * W 维),其中 θB 表示网络中的参数;
(2)Appearance Enhancement Module(AME)模块:
① 生成伪属性标签(pseudo attribute labels):
在ResNet-50上对PETA数据集进行训练。使用ResNet-50的Conv5_x模块的输出作为最后的特征映射 fA^(规格:2048*16*8)。由于属性识别模型的预定义属性数量 N = 105,过于庞大,对属性进行分组。在属性分组前,加上全局平均池化层和全连接层。分组的数量为 M,每组有一个属性特征量 am(规格:256),每组含有 Nm 个属性,各组的属性如下表。


第 m 组的属性损失函数为(采用了Binary Cross-Entropy loss):
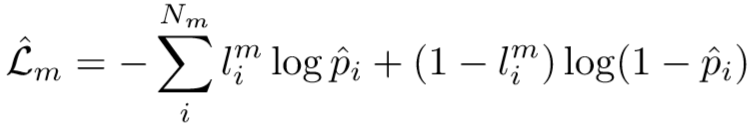
其中 pi^ 表示第 i 属性通过全连接层和Sigmoid层后在第 m 组为真的概率值,lim 表示第 i 个属性在第 m 组是否为真。
Attribute Recognition Model(ARM)的总损失函数为:
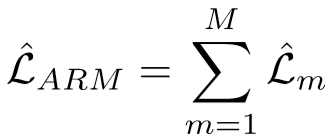
将视频的每一帧都输入ARM中,获取图像的属性特征,对于每个特征,采用时间平均池化,对最终的平均预测进行判断,超过0.5设置为true,即 li^ = 1,最终得到 l1^, l2^, ..., lN^.
② 外貌增强(appearance enhancement):
将第 ① 步得到的标签作为 AEM 模块的监督。
将获得的 BF 输入到 appearance branch,生成特征map为 fA(规格:C * H * W),appearance branch采用2017年提出的 I3D inception block,具体如下:

每一个卷积层都跟着batch正则化层和ReLU激活层。之后采用第 ① 步的标签作为监督,采用类似第 ① 步的做法提取出 M 个属性特征量和 N 个属性预测值,损失函数为:

【个人理解:先用别人的数据集,训练一个行人属性模型,再把作者所用的数据集输入该模型,得到属性label,把属性label作为监督,应用在appearance branch module的训练上。】
(3)Motion Enhancement Module(MEM)模块:
MEM模块预测出未来帧,再跟实际的帧比较,若成功预测,则说明该模型捕获了行人的步行模式。
① 图像自动编码器(Texture AutoEncoder):
TAE是由2006年被提出,用于编码行人图片,输出的结果 ftex 规格为 C * H * W。Encoder采用了ResNet-18模型,Decoder采用了4个反卷积模块,每一个模块都有一个带有3*3规格kernel的反卷积层和batch正则化层组成,除了最后的反卷积模块,其它再添加ReLU层,最后通过sigmoid层输出。

TAE采用Market-1501训练,损失函数采用Mean Squared Error(MSE)loss,并添加一项DTAE用于判断生成的图片是否为真,总损失函数为:

其中 I^ 为输入的图片,I~ 为输出的重构结果;G、D、f 分别为表示TAE的反编码、DTAE和ftex;pI^ 和 pf 分别表示在图片和特征空间的样本分布。DTAE 在最大化 Ladv 时,TAE在最小化。
【注:该损失函数还没有看懂,参考文献待阅读 2017:Unsupervised representation learning with deep convolutional neural network for remote sensing images】
② 动作提取:
选取输入序列的一帧 It(0 < t < T - c),预测下一帧 It+1。将 It+1 视为通过 ftext+1 反编码得到。 ftext+1 被分为两个部分:当前帧的texture特征 ftext 和动作特征 fM(表示两个连续帧的运动)。通过TAE提取出了 ftext,通过主干网络 Ø(S, θB) 获得动作特征 fM。motion branch采用了和appearance branch相同的结构,仅仅参数不同。然后将这两个特征concat,并输入texture嵌入模块获得 ftext+1,该模块由两个分别带有3*3和1*1kernel的卷积层、两个batch正则化层和一个ReLU层构成。 ftext+1 通过反编码获得预测的下一阵 It+1~。
将上述获得的 It+1~ 作为新的当前帧,同理获得 It+2~ ,依次获得到 It+c~。MEM损失函数如下:

(4)优化:
对 fA、fM、fB进行concat,生成最终的特征map F,通过全局平均池化和全连接层,最终的特征表示为 fs。最终的总损失函数为(Lid为softmax损失,Ltri为三元组损失):

其中L表示batch中样本的数量,K表示batch中三元组的数量,[*]+ = max(*, 0),dip 和 din 表示正负样本对的特征距离。
Experiment
(1)实验设置:
主干模型在Kinetics上预训练;
采用Adam优化;
采用MARS、iLIDS-VID、PRID-2011作为评测数据集;
learning rate = 1e-3,每60epoch,下降0.2倍;
weight decay = 5e-4;
输入序列长度 T = 8;
输入帧的规格:256 * 128;
特征map规格:H = 16,W = 8,C = 1024,T’ = 3;
最终特征 fs 的维度:512;
其它参数:k = 0.2,λA = 0.1,λM = 10;
(2)实验结果:
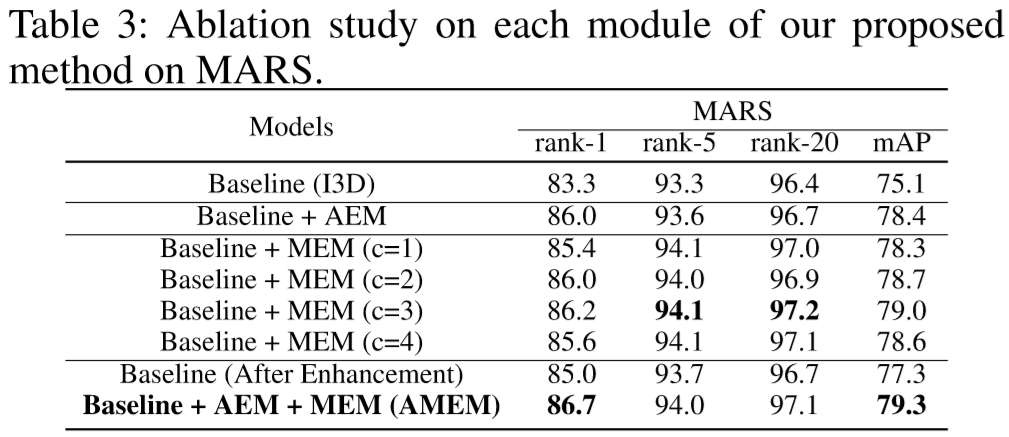
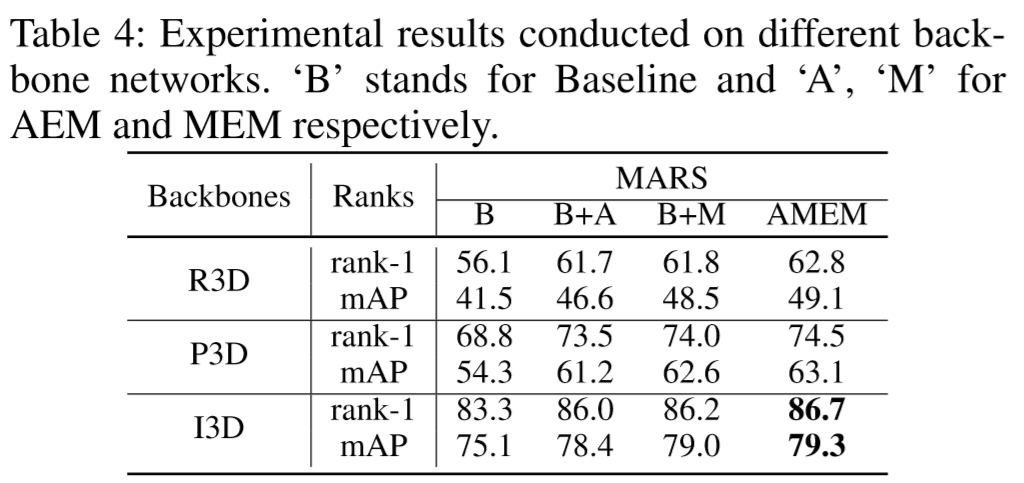
(Table 4中的R3D[3D-ResNet]、P3D[Pseudo 3D]、I3D分别是3D卷积模型的变形)
