什么是大数据
关于大数据的定义目前有很多种,其实“大数据”就是收集各种数据,经过分析后用来做有意义的事,其中包括对数据进行采集、管理、存储、搜索、共享、分析和可视化。
大数据的特点
大数据的特点可以用“4v”来表示,分别为volume、variety、velocity和value。
·海量性(volume):大数据的数据量很大,每天我们的行为都会产生大批量数据。
·多样性(variety):大数据的类型多种多样,比如视频、音频和图片都属于数据。
·高速性(velocity):大数据要求处理速度快,比如淘宝“双十一”需要实时显示交易数据。
·价值性(value):大数据产生的价值密度低,意思是说大部分数据没有参考意义,少部分数据会形成高价值,比如私家汽车安装的摄像头,大部分情况下是用不到的,但是一旦出现“碰瓷”等现象就会很有价值。
大数据时代的思维变革
从维克多·迈尔·舍恩伯格所著的《大数据时代》中,可以看到大数据时代的思维变革。
(1)不是随机样本,而是全体数据。
统计学家们证明:采样分析的精确性随着采样随机性的增加而大幅提高,但与样本数量的增加关系不大。随机采样取得了巨大的成功,成为现代社会、现代测量领域的主心骨。但这只是一条捷径,是在不可收集和分析全部数据的情况下的选择,它本身存在许多固有的缺陷。大数据是指不用随机分析法这样的捷径,而采用所有数据的方法。
(2)不是精确性,而是混杂性。
数据多比少好,更多数据比算法系统更智能还要重要。社会从“大数据”中所能得到的益处,并非来自运行更快的芯片或更好的算法,而是来自更多的数据。大数据的简单算法比小数据的复杂算法更有效。大数据不仅让我们不再期待精确性,也让我们无法实现精确性。那些精确的系统试图让我们接受一个贫乏而规整的惨象——假装世间万物都是整齐地排列的。而事实上,现实是纷繁复杂的,天地间存在的事物也远远多于系统所设想的。要想获得大规模数据带来的好处,混乱应该是一种标准途径,而不应该是竭力避免的。
(3)不是因果关系,而是相关关系。
在大数据时代,我们不必非得知道现象背后的原因,而是要让数据自己“发声”。通过给我们找到一个现象的良好关联物,相关关系可以帮助我们捕捉现在和预测未来。在小数据世界中,相关关系也是有用的,但在大数据的背景下,相关关系大放异彩。通过应用相关关系,我们可以比以前更容易、更快捷、更清楚地分析事物。大数据的相关关系分析法更准确、更快,而且不易受偏见的影响。建立在相关关系分析法基础上的预测是大数据的核心。
大数据技术框架
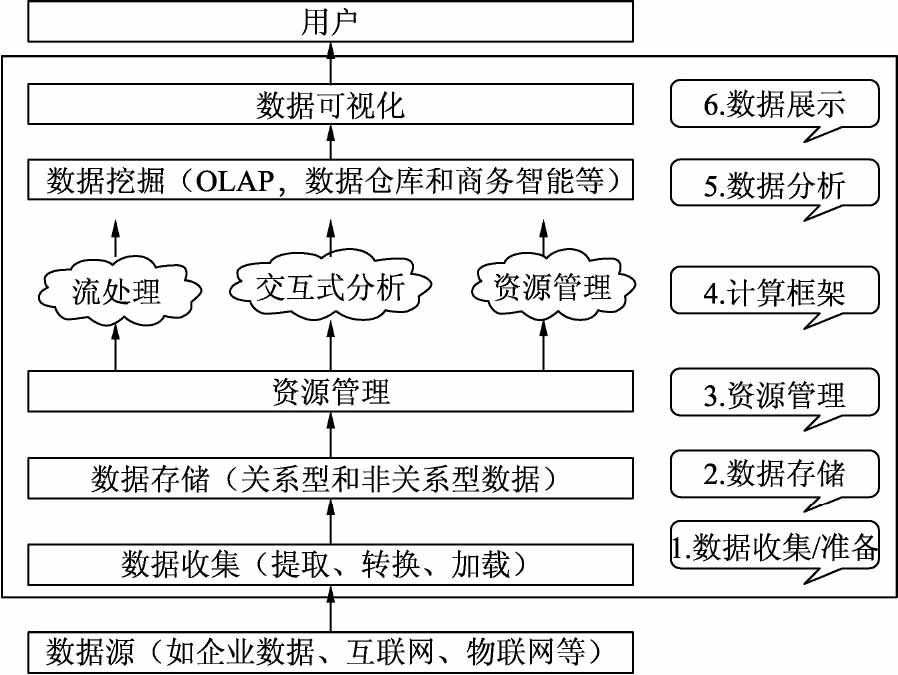
大数据技术框架主要包含6个部分,分别是数据收集、数据存储、资源管理、计算框架、数据分析和数据展示,每部分包括的具体技术如图所示
大数据的技术转型
关系数据库技术,可扩展性是这种计算模式的一大缺陷。当数据容量更大、并发处理性能需求更高时,唯有提高服务器性能指标和可靠性,这是典型的向上扩展模式(Scale Up)。即使可采用并行数据库集群,最多也只能管理有限数量的服务器,而且这种并行数据库也同样要求高配置的服务器才可以运转,其成本之高可以想象。
随着信息技术的进步,相比较而言,软件的重要性将下降,数据的重要性将上升。
尽管随着时间的推移,商用计算机硬件变得越来越便宜,但是,从历史和经济的角度来看,持续不断地升级到更高配置的服务器硬件是不可行的。花费数倍的价钱升级一个大型机器,可能无法提供同样倍数的性能。相比之下,性能一般的小型服务器仍然很便宜。一般情况下,从经济的角度来看,水平扩展更有意义。换句话说,应该简单地为系统增加更多便宜的机器,而不是试图将一个关系型数据库放到一台昂贵的大型服务器上。
以关系数据库技术,不可能支撑今天大数据的应用场景。对于很多应用场景,尤其是互联网相关应用来说,并不像银行业务等对数据的一致性有很高的要求,而更看重数据的高可用性以及架构的可扩展性等技术因素。因此,NoSQL数据库应运而生,作为适应不同应用场景要求的新型数据存储与处理架构,它与传统数据库有很强的互补作用,而且应用场景更加广泛。
数据分片
在大数据环境下,数据量已经由GB级别跨越到PB级别,依靠单台计算机已经无法存储与处理如此规模的数据,唯一的出路,是采用大规模集群来对这些数据进行存储和处理,所以,系统的可扩展性成为衡量系统优劣的关键因素。
传统关系数据库系统为了支持更多的数据,采用纵向扩展(Scale Up)的方式,即不增加机器数量,而是通过改善单机硬件资源配置,来解决问题。如今这种方式已经行不通了。
目前主流的大数据存储与计算系统通常采用横向扩展(Scale Out)的方式支持系统可扩展性,即通过增加机器数目来获得水平扩展能力。与此对应,对于待存储处理的海量数据,需要通过数据分片(Shard/Partition)来对数据进行切分并分配到各个机器中去,通过数据分片实现系统的水平扩展。
数据复制,通过数据复制来保证数据的高可用性。数据复制是将同一份数据复制存储在多台计算机中,以保证数据在故障常发环境下仍然可用。从数据复制还可以获得另一个好处,即可以增加读操作的效率,客户端可以从多个备份数据中选择物理距离较近的进行读取,既增加了读操作的并发性,又可以提高单次的读取效率。
可以将数据分片的通用模型看作是一个二级映射关系。第一级映射是key-partition映射,即把数据记录映射到数据分片空间,通常,一个数据分片包含多条记录数据;第二级映射是partition-machine映射,把数据分片映射到物理机器中,即一台物理机器通常可以容纳多个数据分片。
数据一致性
在大数据系统中,为了获得系统可用性,需要为同一数据分片存储多份副本,业界的常规做法是一个数据分片同时保存三个副本。将数据复制成多份除了能增加存储系统的可用性,同时还能增加读操作的并发性,但引发了数据一致性问题,即同一数据分片存在多个副本。在并发的写请求下,如何保持数据一致性尤为重要,即在存储系统外部的使用者看来,即使存在多个副本数据,它与单份数据也应该是一样的。CAP、BASE、ACID等基本原则是分布式环境下数据一致性方案设计重要的指导原则。
关系数据库系统采纳ACID原则,获得高可靠性和强一致性。而大多数分布式环境下的云存储系统和NoSQL系统则采纳BASE原则。
BASE原则与ACID原则有很大的差异。BASE通过牺牲强一致性来获得高可用性。尽管现在大多数的NoSQL系统采纳了BASE原则,但是有一点值得注意:NoSQL系统与云存储系统的发展过程正在向逐步提供局部ACID特性发展,即从全局而言,符合BASE原则,但局部上支持ACID原则,这样,就可以吸取两者各自的好处,在两者之间建立平衡。
ACID强调数据的一致性,这是传统数据库设计的思路。而BASE更强调可用性,弱化数据强一致性的概念,这是互联网时代对于大规模分布式数据系统的一种需求,尤其是其中的软状态和最终一致性。可以说,ACID和BASE原则是在明确提出CAP理论之前关于如何对待可用性和强一致性的两种完全不同的设计思路。
主流大数据技术
主流的大数据技术可以分为两大类。
一类面向非实时批处理业务场景,着重用于处理传统数据处理技术在有限的时空环境里无法胜任的TB级、PB级海量数据存储、加工、分析、应用等。一些典型的业务场景如:用户行为分析、订单防欺诈分析、用户流失分析、数据仓库等,这类业务场景的特点,是非实时响应,通常,一些单位在晚上交易结束时,抽取各类数据进入大数据分析平台,在数小时内获得计算结果,并用于第二天的业务。比较主流的支撑技术为HDFS、MapReduce、Hive等。
另一类面向实时处理业务场景,如微博应用、实时社交、实时订单处理等,这类业务场景,特点是强实时响应,用户发出一条业务请求,在数秒钟之内要给予响应,并且确保数据完整性。比较主流的支撑技术为HBase、Kafka、Storm等。
大数据计算模式
常见的大数据计算模式分为4类
·批处理计算
又称为离线计算,是针对大规模历史数据的批量处理,如MapReduce。
·流计算
是针对流数据的实时计算,可以实时处理产生的数据。商业版的有IBM InfoSphere Streams和IBM StreamBase,开源的有Storm和S4(Simple Scalable Streaming System),还有一部分是企业根据自身需求而定制的,如Dstream(百度)。
·图计算
是针对大规模图结构数据的处理,常用于社交网络,如Pregel、GraphX、Giraph(FaceBook)、PowerGraph和Hama等。
·查询分析计算
是针对大规模数据的存储管理和查询分析,如Hive、Cassandra和Impala等。
大数据与云计算、物联网的关系
大数据、云计算和物联网三者息息相关,是互相关联、相互作用的。
物联网是大数据的来源(设备数据),大数据技术为物联网数据的分析提供了强有力的支撑;
物联网还为云计算提供了广阔的应用空间,而云计算为物联网提供了海量数据存储能力;
云计算还为大数据提供了技术基础,而大数据能为云计算所产生的运营数据提供分析和决策依据。
三者的关系如图所示。

参考:
大数据:从基础理论到最佳实践 - 大数据存储篇
从零开始学Hadoop大数据分析 1.1 大数据初探