作业描述
| 所属课程 | 软件工程1916|W(福州大学) |
|---|---|
| 作业要求 | 团队作业第六次—团队Github实战训练 |
| 团队名称 | 待就业六人组 |
| 作业目标 | 搭建一个相对公平公正的抽奖系统,根据QQ聊天记录,完成从统计参与抽奖人员颁布抽奖结果的基本流程。 |
| 项目文档 | 项目在线文档 |
| 在线抽奖 | 项目在线展示 |
| 项目地址 | Github |
服务器最近不稳定,如果出现异常情况,请联系待就业六人组小组成员
一、组员职责分工&组员贡献比例
| 成员 | 职责 | 贡献比例 |
|---|---|---|
| XRK | Web前端、博客编写 | 22% |
| Yellye | Web前端 | 16% |
| 黎焕明 | 聊天记录处理、聊天记录分析 | 15% |
| Litm | 提取用户表 | 17% |
| oirving | 提取奖项表、奖项条件表 | 16% |
| supermingjun | 过滤&中奖算法、程序整合、接口&数据字典文档编写,服务器部署,博客撰写 | 14% |
二、GitHub提交日志截图
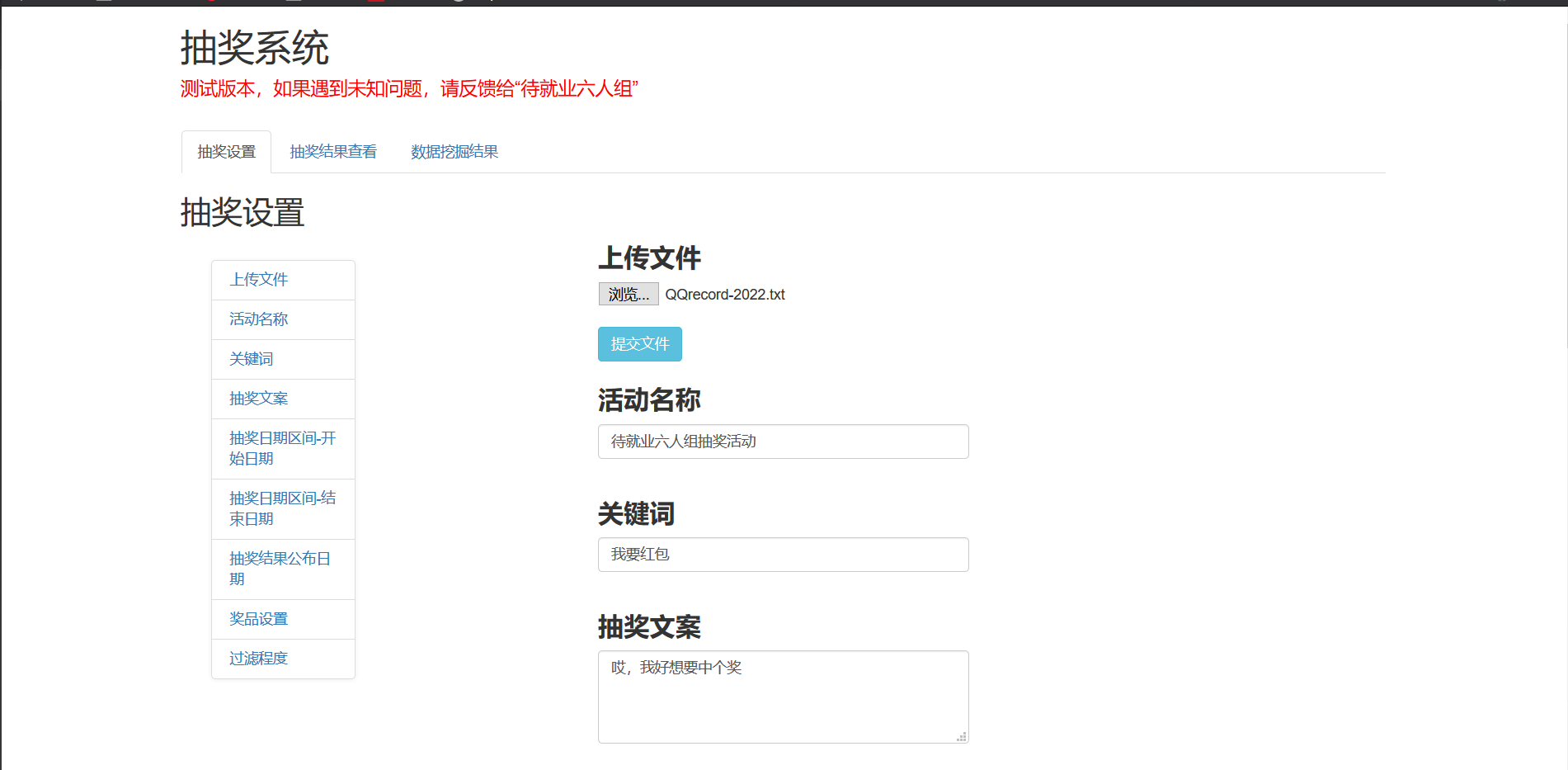
三、程序运行截图
- 设置抽奖事件、文案、规则


- 输入校验

- 查看抽奖结果

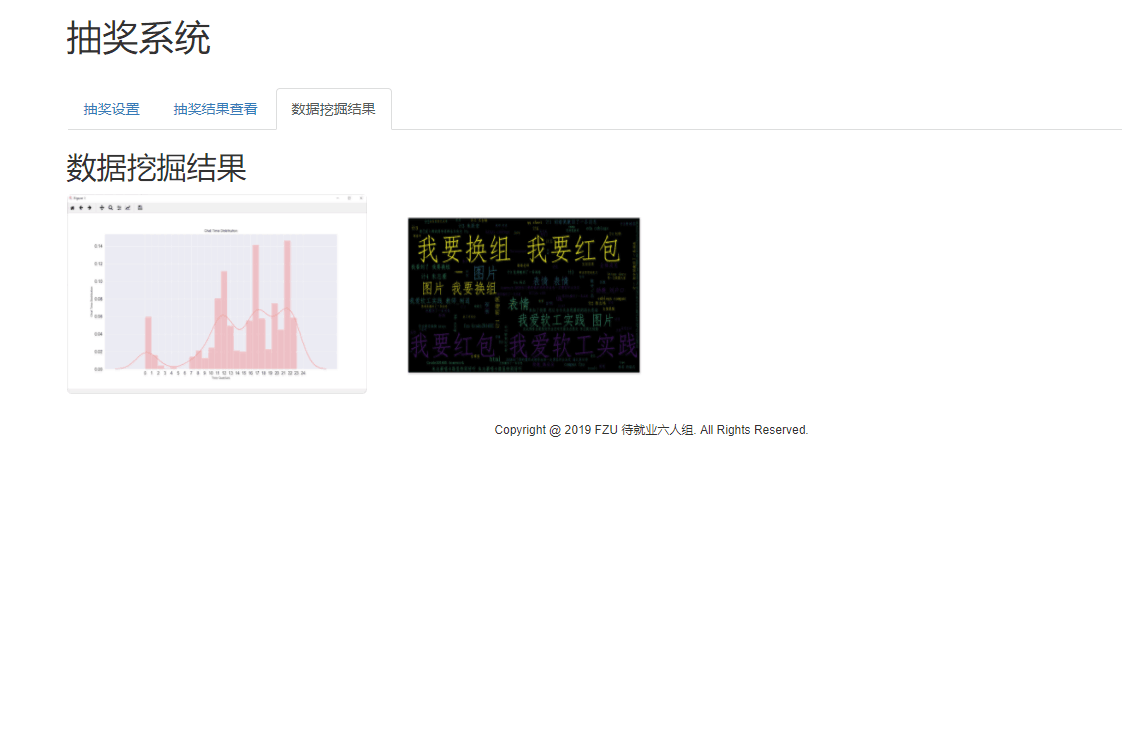
- 聊天记录分析
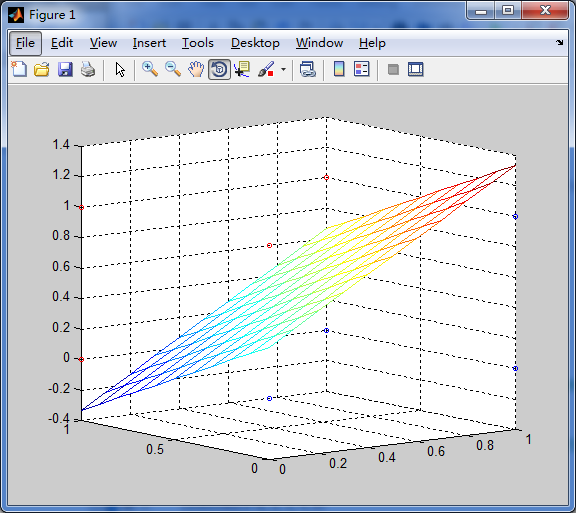
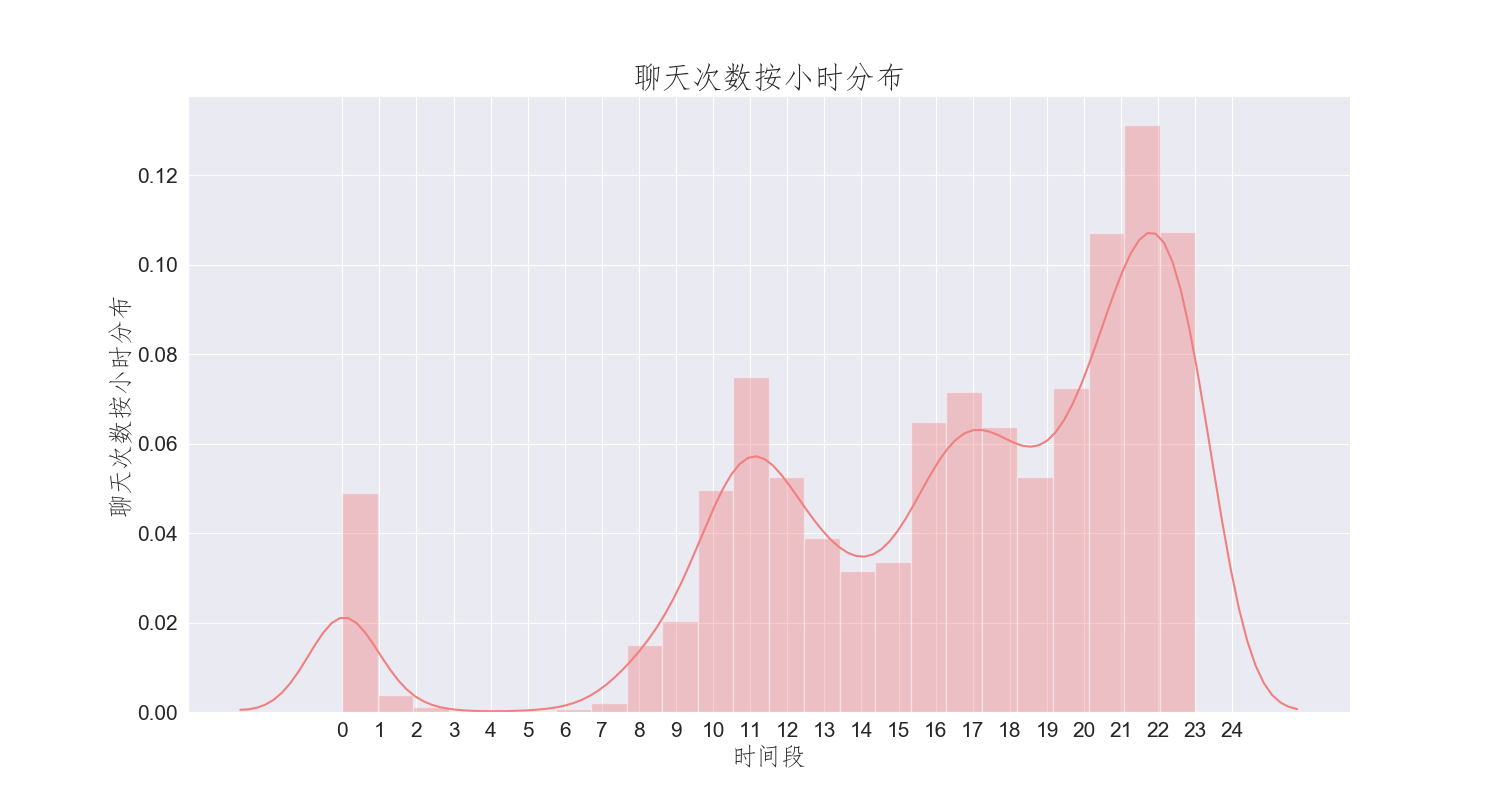
使用Anaconda中的绘图工具可分别统计得到按小时和日的活跃发言统计图以及高频词汇图,具体可视化图如下:
四、程序运行环境
- 编程语言
- 前端:HTML、JavaScript
- 后端:Java、python3.5
- Apache Tomcat 8.0
- MySQL 5.5
- 浏览器
- Google Chrome 版本73.0.3683.103(正式版本) (64位)
- Firefox Quantum 66.0.3(64位)
- IDE
- intellij idea
- eclipse
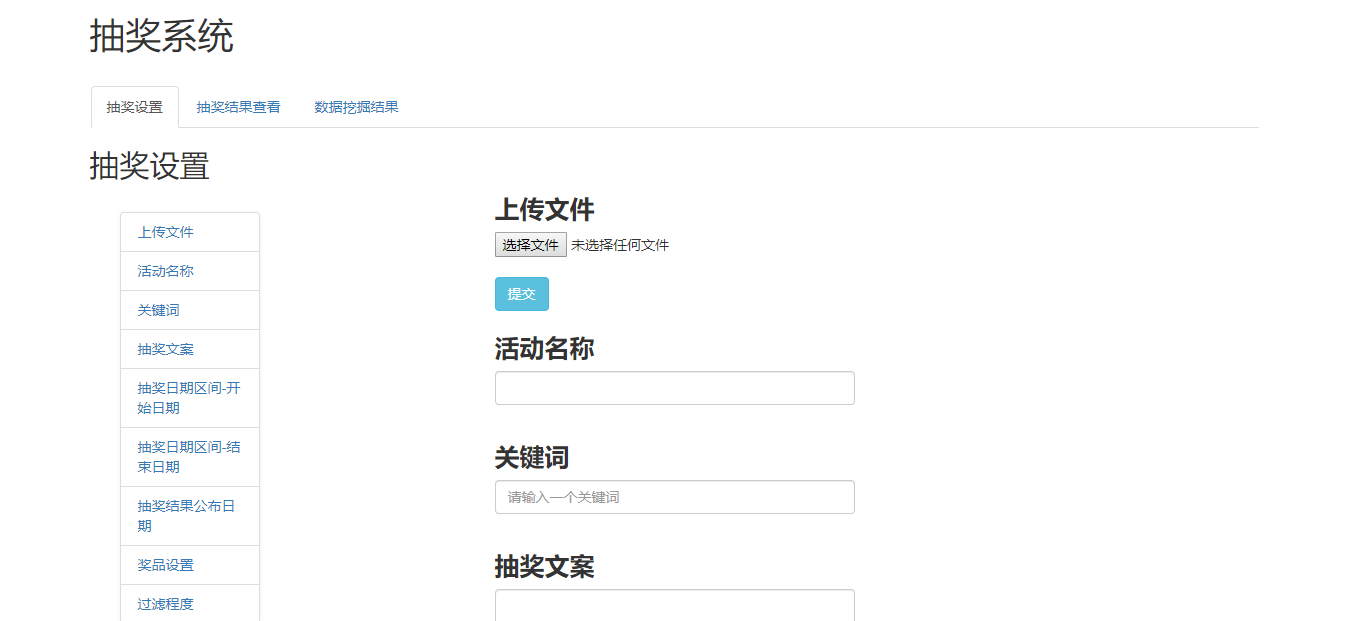
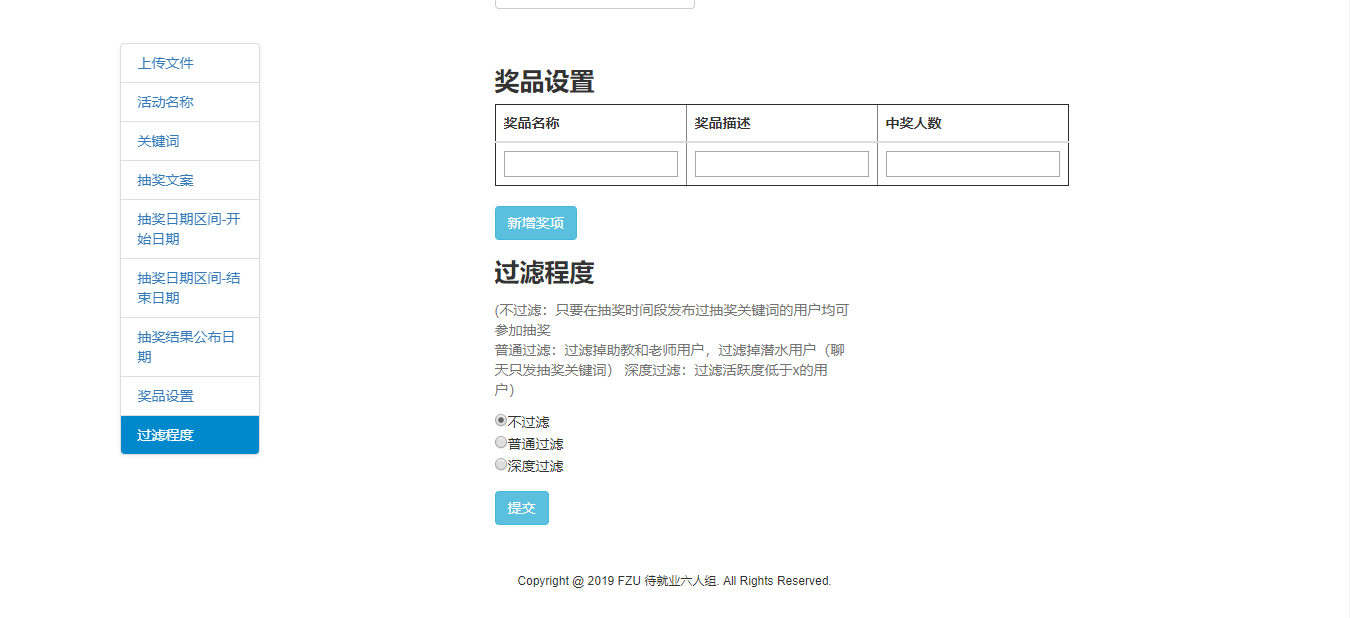
五、GUI界面
- 抽奖设置

- 抽奖结果查看
- 数据挖掘结果
六、基础功能实现
-
实现完整GUI界面——JSP代码
-
设置抽奖事件、文案、规则
-
导出抽奖结果(抽奖话题、中奖人员、对应奖项),有bug,暂未实现
-
抽奖算法设计思路
- 筛选活跃用户
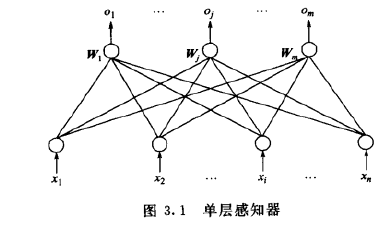
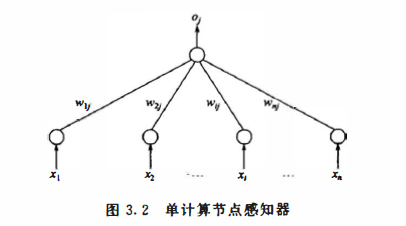
采用算法:perception感知器算法
单层感知器是指只有一层处理单元的感知器。其拓扑结构如图所示,其中输入层也称感知层,有n个神经节点,这些节点只负责引入外部信息,每一个节点接收一个输入信号,n个输入信号构成输入列向量X。输出层也称为处理层,有m个神经元节点,每个节点均有信息处理能力,m个节点向外部输出信息,构成输出列向量O。两层之间的连接权值用权值列向量Wj表示,m个权向量构成单层感知器的权值矩阵W。
- 筛选活跃用户
perception感知器是单输出感知器,不难看出,单节点感知器实际上就是一个M-P神经元模型,采用符号转移函数。
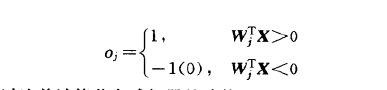
设输入向量X=(x1,x2,x3)T,则3个输入分量在几何上构成一个三维空间。节点j 的输出为:
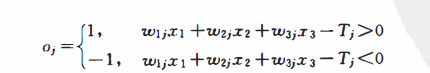
由以下方程确定的平面成为三维输人样本空间上的一个分界平面:
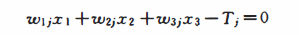
平面上方的样本neti>0,从而使输出为1;平面下方的样本netj<0,从而使输出为一1。同样,由感知器权值和阔值确定的平面方程规定了分界平面在样本空间的方向与位置,从而也确定了如何将输入样本分为两类。假如分界平面的初始位置不能将两类样本正确分开,改变权值和阔值即改变了分界平面的方向与位置,因此总可以将其调整到正确分类的位置。
基于perception算法,我们用粗糙的数据集训练了一个粗糙的模型,对用户活跃度进行判定。算法输入输出如下:
input:用户的总活跃天数、最大连续活跃天数、有效发言数
output:1(活跃用户)、-1(不活跃用户)
-
Fisher–Yates随机置换算法抽奖
Fisher–Yates随机置乱算法也被称做高纳德置乱算法,通俗说就是生成一个有限集合的随机排列。Fisher-Yates随机置乱算法是无偏的,所以每个排列都是等可能的,使用的Fisher-Yates随机置乱算法是相当有效的,需要的时间正比于要随机置乱的数,不需要额为的存储空间开销。
算法流程:
- 根据过滤条件,从数据库抽取有抽奖资格的用户:
(1)不过滤:只要在抽奖时间段发布过抽奖关键词的用户均可参加抽奖
(2)普通过滤:过滤掉助教和老师用户,过滤掉潜水用户(聊天只发抽奖关键词)
(3)深度过滤:过滤活跃度低于x的用户
2.由perception算法将有抽奖资格的用户分成活跃和非活跃两类,给与不同的权重,例如活跃权重为2,非活跃为1,设置一个String数组a,存储抽奖资格用户的用户id,每个用户在这个数组的元素个数等于权重数:
例如一个id为666的活跃用户,他在a数组中有两个元素a[x]="666",a[y]="666";
调用Fisher–Yates随机置换算法,将a数组置乱。
for i 从n-1到1
j <—随机整数(0 =< j <= i)
交换a[i]和a[j]
end
3.根据奖项数量为k,就取前k个元素,按奖项顺序得奖,若出现已经获奖的用户,则顺延至k+1的用户获奖,以此类推。
七、附加功能实现
- 支持对聊天记录进行分析与挖掘
活跃期:从图中分析可以得到,大部分同学发言都喜欢在晚上22点,这时候正是同学们思维活跃期,活跃日期主要是3号,可能这一天发生着某些特别的事。
高频词汇:二手群非常喜欢喜欢发图片以及“带价出”、“xx价格出”等,任务群大多交流一些和计算机知识相关的内容,例如网站开发、java作业等。
PlusA

PlusB



八、遇到的困难以及解决办法
-
XRK
- 遇到的问题:在本次实训中,我负责的是把前端表单转换成json格式,利用post请求把数据发送到后台,以及通过异步回调,将后台的数据展现到前端界面中。虽然之前学过HTML和JavaScript,但是并不怎么涉及到异步传输的问题,所以在这上面卡了很久。
- 解决的办法:最终完成了这样功能,离不开互联网的帮助。通过网上查询相关的例子和其他人的博文讲解来学习。
-
Yellye
- 遇到的问题:此次作业我负责的是前端,主要是界面显示。在设置奖项方面,开始的设想是像微博一样固定只能设置三个奖项,但后来还是决定给用户自己设置奖项数目的自由,所以在动态增删表格并获取输入的数据这边花了一些时间。虽然学过JavaScript但是很久没练习太生疏了,说明技术还是得多练。
- 解决方法:感谢科技,感谢互联网,感谢乐于分享自己学习成果的大牛们!
-
黎焕明
- 遇到的问题:1. emoj不能存进数据库. 2. 读取文件编码错误(不同ide造成).
- 解决办法:1. 设置表结构可存emoji. 2. 更改编码.
-
Litm
- 遇到的问题:前端的请求参数是json,后端处理接收数据的时候格式变掉了,修改了好长时间。但是还是没有找到原因。还有编码问题,第一次这样协同合作,问题还是很多的。
- 解决的办法:参数问题,就是百度查找,修改尝试。编码问题,不断修改尝试。经过这一次学习到了很多,第一次这样协同编码出问题是很正常的,希望之后会越来越好。
-
oirving
-
遇到的问题:我本次做的是把聊天记录表转换成的用户表,提取其中的信息并汇总,都是涉及一些数据的操作,没有特别难的点;最影响我进度的就是各成员的软件版本没有统一,我用的又是MacBook跟大家的系统不太一样,所以很多东西从GitHub上pull下来后不能直接使用,需要调试很久,非常影响进度。
-
解决办法:首先这个问题是每人电脑的差异,客观存在的问题,要把每个成员的软件版本都统一太麻烦了,所以我选择了用他们的电脑pull下来在他们的电脑写代码,实在是花费了太多时间去配置参数,拖不起啊。自己能力也需要加强,意识到了工程能力的差距。
-
-
supermingjun
- 遇到的问题:在创建仓库的时候,没有把基本的DAO层和POJO层的代码统一,时间又比较紧,导致后面队友集中pull的时候merge出现了很多的冲突。
- 解决办法:查看冲突的位置,解决冲突。吸取教训,以后一定要实现规划好。
九、PSP表格(六合一)
| PSP2.1 | Personal Software Process Stages | XRK (预估耗时(分钟)/实际耗时(分钟) | Yellye (预估耗时(分钟)/实际耗时(分钟) | 黎焕明 (预估耗时(分钟)/实际耗时(分钟) | Litm (预估耗时(分钟)/实际耗时(分钟) | oirving (预估耗时(分钟)/实际耗时(分钟) | supermingjun (预估耗时(分钟)/实际耗时(分钟) |
|---|---|---|---|---|---|---|---|
| Planning | 计划 | ||||||
| • Estimate | • 估计这个任务需要多少时间 | 30/30 | 30/30 | 40/40 | 80/80 | 30/30 | 50/50 |
| Development | 开发 | ||||||
| • Analysis | • 需求分析 (包括学习新技术) | 240/360 | 60/90 | 50/70 | 30/40 | 60/100 | 80/60 |
| • Design Spec | • 生成设计文档 | 40/60 | |||||
| • Design Review | • 设计复审 | ||||||
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 40/30 | |||||
| • Design | • 具体设计 | 120/180 | 120/130 | 70/80 | 90/110 | 100/120 | 120/80 |
| • Coding | • 具体编码 | 360/540 | 240/450 | 260/560 | 200/550 | 240/500 | 360/480 |
| • Code Review | • 代码复审 | 120/180 | 150/200 | 60/80 | 60/120 | 100/120 | 40/90 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 160/180 | 60/100 | 50/80 | 60/150 | 60/80 | 50/80 |
| Reporting | 报告 | ||||||
| • Test Report | • 测试报告 | ||||||
| • Size Measurement | • 计算工作量 | ||||||
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | ||||||
| 合计 | 1030/1470 | 660/1000 | 530/910 | 520/1150 | 520/980 | 780/930 |