字符串编码
1、编码历史
- 计算机只能处理数字0和1,文本转换为数字才能处理。计算机中8个位(
bit)作为一个字节(byte),所以一个字节能表示最大的十进制数字就是255。 - 计算机是美国人发明的,一个字节就可以表示所有字符了,所以
ASCII(一个字节)编码就成为美国人的标准编码。 - 但是
ASCII处理中文明显是不够的,汉字成千上万可不止255个,所以中国制定了GB2312编码,用两个字节表示一个汉字。GB2312还把ASCII包含进去了。但是,其他国家的文字为了解决这个问题也都发展了一通自己的编码,标准越来越多,如果要同时显示多种语言就一定会出现乱码。 - Unicode`的出现,将所有语言统一到一套编码里。
- 乱码问题解决了,但是如果内容全是英文,
Unicode编码比ASCII需要多一倍的存储空间,如果传输这些英文则需要多一倍的存储空间。 - 所以出现了可变长的编码——
utf-8,英文还是一个字节,汉字3个字节,特别生僻的文字变长为4-6个字节;此时若传输大量的英文,utf8(utf-8一样)作用就很明显了。
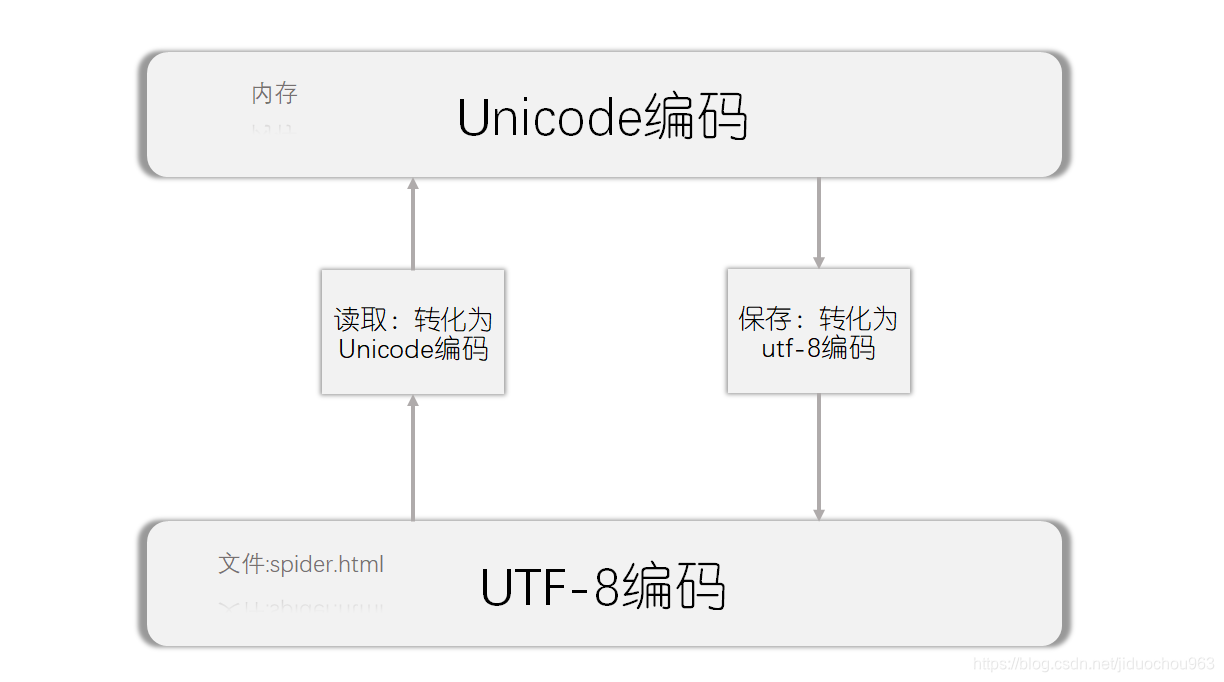
读文件(从磁盘读到内存)时指定文件的编码,然后Python会自动将编码转换为Unicode编码到内存;保存(从内存写回磁盘)的时候也指明编码格式一下要保存的编码格式。
2、Python2.x和Python3.x的编码
在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
在Python3.x中,字符串的编码使用str和bytes两种类型。
- str字符串(默认):使用Unicod编码
- bytes字符串:使用Unicode转换成的某种类型的编码,如UTF-8、GBK
在Python3.x中,字符串默认的编码为Unicode,即str字符串;Python2.x相对Python3.x来说由于字符串默认使用将Unicode转换成的某种类型的编码,可以采用的编码比较多,因此使用过程中经常遇到编码问题,为我们带来很多的烦恼。
这些默认的str字符串怎么才能转化为bytes字符串呢?这就要用到encode和decode了:
encode的作用是将Unicode编码转换成其他编码的字符串;decode的作用是将其他编码的字符串转换成Unicode编码。
Python2.x
Windows环境
Python 2.7.15 (v2.7.15:ca079a3ea3, Apr 30 2018, 16:30:26) [MSC v.1500 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> s = "abc"
>>> su = u"abc"
>>> s.encode("utf8")
'abc'
>>> su.encode("utf8")
'abc'
>>>
>>> s = "Py2编码"
>>> su = u"Py2编码"
>>> su.encode("utf8")
'Py2xe7xbcx96xe7xa0x81'
>>> s.encode("utf8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xb1 in position 3: ordinal not in range(128)
>>>
>>>> s.decode("gb2312").encode("utf8") # Windows环境采用gb2312编码
'Py2xe7xbcx96xe7xa0x81'
>>>
做encode时候要保证为Unicode编码的字符串。Python在内存中是采用Unicode来进行编码的,s是从操作系统内存传过来的值,在Windows下是gb2312的编码,Linux下是utf8的编码,并不是Unicode的编码。在调用encode方法时一定要将字符串的编码变成Unicode,所以要将字符串编码(encode)成utf8,需要先将字符串先解码(decode)成Unicode。decode的作用是将其他编码的字符串(在decode的参数中指定)变成Unicode的字符串,但是在decode的时候一定要将字符串decode成gb2312(Windows环境)再encode。
Linux环境
即使Linux是采用utf8编码的,用encode编码成utf8格式时也要保证被编码的字符串是Unicode编码的。所以先要指定编码格式将其解码(decode)成Unicode,再编码(encode)成utf8。
[root@localhost ~]# python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> s = "Py2编码"
>>> s.encode("utf8") # utf8 和utf-8 是同一个意思
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 3: ordinal not in range(128)
>>> s.decode("gb2312").encode("utf-8") # Windows环境采用gb2312编码
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'gb2312' codec can't decode bytes in position 5-6: illegal multibyte sequence
>>> s.decode("utf-8").encode("utf8") # Linux环境采用utf-8编码
'Py2xe7xbcx96xe7xa0x81'
>>>
Python3.x:全部使用Unicode编码
Windows环境
(ve_test_1) C:Usersxxx>python
Python 3.7.1 (v3.7.1:260ec2c36a, Oct 20 2018, 14:57:15) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> s = "Py3编码"
>>> s.encode("utf8")
b'Py3xe7xbcx96xe7xa0x81'
>>>
Linux环境
Python 3.7.2 (default, Jan 29 2019, 16:33:33)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> s = "Py3编程"
>>> s.encode("utf-8")
b'Py3xe7xbcx96xe7xa8x8b'
>>>
默认编码格式:Python2.x默认使用
ascii编码,Python3.x默认使用utf-8编码,这与平台无关。
这一点可以在Windows或者Linux上通过sys.getdefaultencoding()查到,下面以Linux为例:
root@xxx:~# python
Python 2.7.15rc1 (default, Nov 12 2018, 14:31:15)
[GCC 7.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'ascii' # Python2.x默认使用ascii编码
>>> exit()
root@xxx:~# python3
Python 3.6.7 (default, Oct 22 2018, 11:32:17)
[GCC 8.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'utf-8' # Python3.x默认使用utf-8编码
>>> exit()
root@xxx:~#
为使Python2.x的解释器通过Python源文件来读取代码的时候能够识别中文,要在头部添加声明:
# -*- coding: utf-8 -*-。
Python3.x可以添加此声明来兼容Python2.x,当然也可以不写,在Python3.x环境下运行不会出现任何问题。
Linux和Windows跨平台编码时统一编码格式方法
参考:https://blog.csdn.net/zhuzitop/article/details/80390100