一、Downloader Middleware 的用法
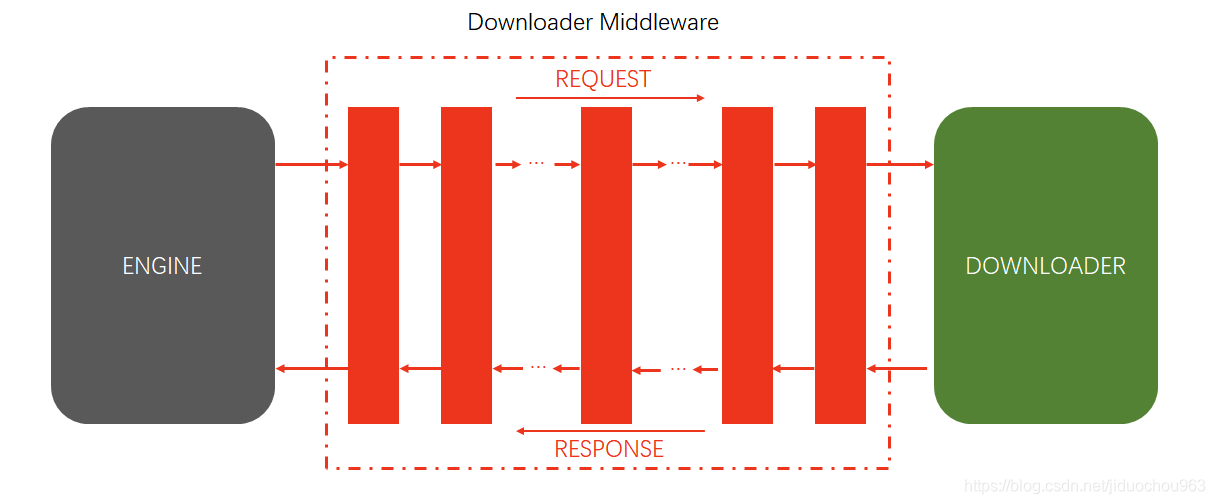
Downloader Middleware即下载中间件,它是处于Scrapy的Request和Response之间的处理模块。
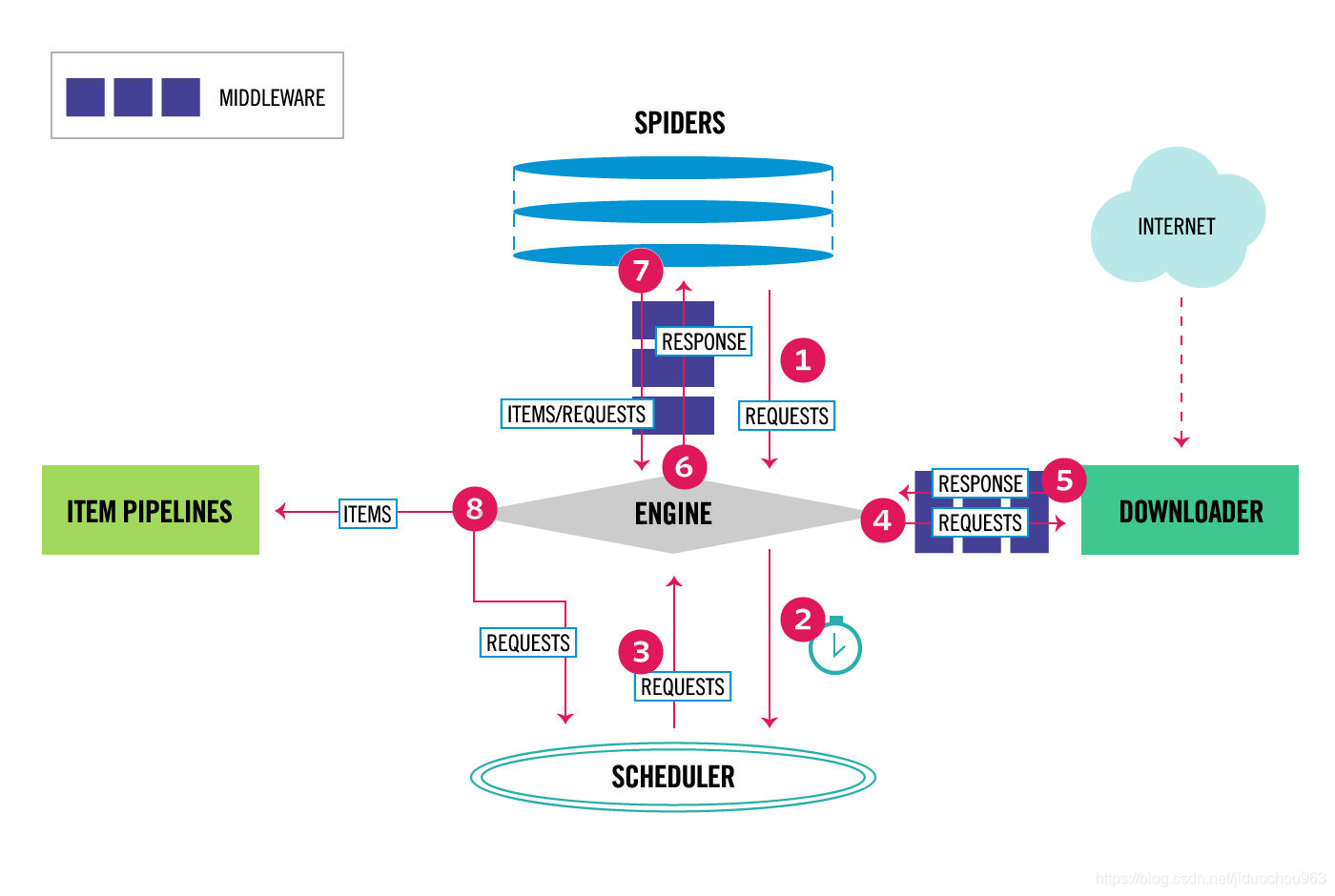
Scheduler从队列中拿出一个Request发送给Downloader执行下载,这个过程会经过Downloader Middleware的处理。另外,当Downloader将Request下载完成得到Response返回给Spider时会再次经过Downloader Middleware处理。
也就是说,Downloader Middleware在整个架构中起作用的位置是以下两个:
- 在Scheduler调度出队列的Request发送给Doanloader下载之前,也就是我们可以在Request执行下载之前对其进行修改。
- 在下载后生成的Response发送给Spider之前,也就是我们可以在生成Resposne被Spider解析之前对其进行修改。
Downloader Middleware的功能十分强大,修改User-Agent、处理重定向、设置代理、失败重试、设置Cookies等功能都需要借助它来实现。下面我们来了解一下Downloader Middleware的详细用法。
1. 使用说明
需要说明的是,Scrapy其实已经提供了许多Downloader Middleware,比如负责失败重试、自动重定向等功能的Middleware,它们被DOWNLOADER_MIDDLEWARES_BASE变量所定义。
DOWNLOADER_MIDDLEWARES_BASE变量的内容如下所示:
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
这是一个字典格式,字典的键名是Scrapy内置的Downloader Middleware的名称,键值代表了调用的优先级,优先级是一个数字,数字越小代表越靠近Scrapy引擎,数字越大代表越靠近Downloader,数字小的Downloader Middleware会被优先调用。
如果向己定义Downloader Middleware要添加到项目里,DOWNLOADER_MIDDLEWARES_BASE变量不能直接修改。Scrapy提供了另外一个设置变量DOWNLOADER_MIDDLEWARES,我们直接修改这个变盘就可以添加向己定义的Downloader Middleware,以及禁用DOWNLOADER_MIDDLEWARES_BASE里面定义的Downloader Middleware。下面我们具体来看看Downloader Middleware的使用方法。
2 . 核心方法
Scrapy内置的Downloader Middleware为Scrapy提供了基础的功能,但在项目实战中我们往往需要单独定义Downloader Middleware。不用担心,这个过程非常简单,我们只需要实现某几个方法即可。每个Downloader Middleware都定义了一个或多个方法的类,核心的方法有如下三个。
process_request(request, spider)。process_response(request, response, spider)。process_exception(request, exception, spider)。
我们只需要实现至少一个方法,就可以定义一个Downloader Middleware。下面我们来看看这三个方法的详细用法:
process_request(request, spider)
Request被Scrapy引擎调度给Downloader之前,process_request()方法就会被调用,也就是在Request从队列里调度出来到Downloader下载执行之前,我们都可以用processrequest()方法对Request进行处理。方法的返回值必须为None、Response对象、Request对象之一,或者抛出IgnoreRequest异常。
process_request()方法的参数有如下两个:
- request,是Request对象,即被处理的Request。
- spider,是Spdier对象,即此Request对应的Spider。
返回类型不同,产生的效果也不同。下面归纳一下不同的返回情况:
- 当返回是None时,Scrapy将继续处理该Request,接着执行其他Downloader Middleware的process_request()方法,一直到Downloader把Request执行后得到Response才结束。这个过程其实就是修改Request的过程,不同的Downloader Middleware按照设置的优先级顺序依次对Request进行修改,最后送至Downloader执行。(如果返回None,Scrapy将继续处理该request,执行其他中间件中的相应方法,直到合适的下载器处理函数被调用。)
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_request()和process_exception()方法就不会被继续调用,每个Downloader Middleware的process_response()方法转而被依次调用。调用完毕之后,直接将Response对象发送给Spider来处理。(Scrapy将不会调用任何其他的process_request方法,将直接返回这个response对象。已经激活的中间件的process_response()方法将会在每个response返回时被调用。)
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_request()方法会停止执行。这个Request会重新放到调度队列里,其实它就是一个全新的Request,等待被调度。如果被Scheduler调度了,那么所有的Downloader Middleware的process_request()方法会被重新按照顺序执行。(不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回数据,接着执行其他下载器处理函数。)
- 如果IgnoreRequest异常抛出,则所有的Downloader Middleware的process_exception()方法会依次执行。如果没有一个方法处理这个异常,那么Request的errorback()方法就会回调。如果该异常还没有被处理,那么它便会被忽略。(如果这个方法中抛出了异常,则会调用process_exception方法。)
process_response(request, response, spider)
Downloader执行Request下载之后,会得到对应的Response。Scrapy引擎便会将Response发送给Spider进行解析。在发送之前,我们都可以用process_response()方法来对Response进行处理。方法的返回值必须为Request对象、Response对象之一,或者抛出IgnoreRequest异常。
process_response()方法的参数有如下三个:
- request,是Request对象,即此Response对应的Request。
- response,是Response对象,即此被处理的Response。
- spider,是Spider对象,即此Response对应的Spider。
下面归纳一下不同的返回情况:
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_response()方法不会继续调用。该Request对象会重新放到调度队列里等待被调度,它相当于一个全新的Request。然后,该Request会被process_request()方法顺次处理。
- 当返回为Respons巳对象时,更低优先级的Downloader Middleware的process_response()方法会继续调用,继续对该Response对象进行处理。
- 如果 gnoreRequest异常抛向,则Request的errorback()方法会回调。如果该异常还没有被处理,那么它便会被忽略。
process_exception(request, exception, spider)
当Downloader或process_request()方法抛出异常时,例如抛出IgnoreRequest异常,process_exception()方法就会被调用。方法的返回值必须为None、Response对象、Request对象之一。
process_exception()方法的参数有如下三个。
- request,是Request对象,即产生异常的Request。
- exception,是Exception对象,即抛出的异常。
- spdier,是Spider对象,即Request对应的Spider。
下面归纳一下不同的返回值:
- 当返回为None时,更低优先级的Downloader Middleware的process_exception()会被继续顺次调用,直到所有的方法都被调度完毕。()
- 当返回为Response对象时,更低优先级的Downloader Middleware的process_exception()方法不再被继续调用,每个Downloader Middleware的process_response()方法转而被依次调用。(会将这个新的response对象传给其他中间件,最终传给爬虫。)
- 当返回为Request对象时,更低优先级的Downloader Middleware的process_exception()也不再被继续调用,该Request对象会重新放到调度队列里面等待被调度,它相当于一个全新的Request。然后,该Request 又会被 process_request()方法顺次处理。
(下载器链接切断,返回的request会重新被下载器调度下载。) - 如果抛出一个异常,那么调用request的errback方法,如果没有指定这个方法,那么会抛出一个异常。
以上内容便是这三个方法的详细使用逻辑。在使用它们之前,请先对这三个方法的返回值的处理情况有一个清晰的认识。在自定义 Downloader Middleware的时候,也一定要注意每个方法的返回类型。
二、Spider Middleware 的用法
Spider Middleware是介入到Scrapy的Spider处理机制的钩子框架。
当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过Spider Middleware处理,当Spider处理生成Item和Request之后,Item和Request还会经过Spider Middleware的处理。
Spider Middleware有如下三个作用:
- 我们可以在Downloader生成的Response发送给Spider之前,也就是在Response发送给Spider之前对Response进行处理。
- 我们可以在Spider生成的Request发送给Scheduler之前,也就是在Request发送给Scheduler之前对Request进行处理。
- 我们可以在Spider生成的Item发送给Item Pipeline之前,也就是在Item发送给Item Pipeline之前对Item进行处理。
1. 使用说明
需要说明的是,Scrapy其实已经提供了许多Spider Middleware,它们被SPIDER_MIDDLEWARES_BASE这个变量所定义。
SPIDER_MIDDLEWARES_BASE变量的内容如下:
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrllengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
和Downloader Middleware一样,Spider Middleware首先加入到SPIDER_MIDDLEWARES设置中,该设置会和Scrapy中SPIDER_MIDDLEWARES_BASE定义的Spider Middleware合并。然后根据键值的数字优先级排序,得到一个有序列表。第一个Middleware是最靠近引擎的,最后一个Middleware是最靠近Spider的。
2. 核心方法
Scrapy内置的Spider Middleware为Scrapy提供了基础的功能。如果我们想要扩展其功能,只需要实现某几个方法即可。
每个Spider Middleware都定义了以下一个或多个方法的类,核心方法有如下4个:
process_spider_input(response, spider)。process_spider_output(response, result, spider)。process_spider_exception(response, exception, spider)。process_start_requests(start_requests, spider)。
只需要实现其巾一个方法就可以定义一个Spider Middleware。下面我们来看看这4个方法的详细用法:
process_spider_input(response, spider)
当Response被Spider Middleware处理时·,process_spider_input()方法被调用。
process_spider_input()方法的参数有如下两个:
- response,是Response对象,即被处理的Response。
- spider,是Spider对象,即该Response对应的Spider。
process_spider_input()应该返回None或者抛出一个异常。
- 如果它返回None,Scrapy将会继续处理该Response,调用所有其他的Spider Middleware,直到Spider处理该Response。
- 如果它抛出一个异常,Scrapy将不会调用任何其他Spider Middleware的process_spider_input()方法,而调用Request的errback()方法。errback的输出将会被重新输入到中间件中,使用process_spider_output()方法来处理,当其抛出异常时则调用process_spider_exception()来处理。
process_spider_output(response, result, spider)
当Spider处理Response返回结果时,process_spider_output()方法被调用。
process_spider_output()方法的参数有如下三个:
- response,是Response对象,即生成该输出的Response。
- result,包含Request或Item对象的可迭代对象,即Spider返回的结果。
- spider,是Spider对象,即其结果对应的Spider。
process_spider_output()必须返回包含Request或Item对象的可迭代对象。
process_spider_exception(response, exception, spider)
当Spider或Spider Middleware的process_spider_input()方法抛出异常时,process_spider_exception()方法被调用。
process_spider_exception()方法的参数有如下三个:
- response,是Response对象,即异常被抛出时被处理的Response。
- exception,是Exception对象,即被抛出的异常。
- spider,是Spider对象,即抛出该异常的Spider。
process_spider_exception()必须要么返回None,要么返回一个包含Response或Item对象的可迭代对象。
- 如果它返问None,Scrapy将继续处理该异常,调用其他Spider Middleware中的process_spider_exception()方法,直到所有Spider Middleware都被调用。
- 如果它返回一个可迭代对象,则其他Spider Middleware的process_spider_output()方法被调用,其他的process_spider_exception()不会被调用。
process_start_requests(start_requests, spider)
process_start_requests()方法以Spider启动的Request为参数被调用,执行的过程类似于process_spider_output(),只不过它没有相关联的Response,并且必须返回Request。
process_start_requests()方法的参数有如下两个:
- start_requests,是包含Request的可迭代对象,即Start Requests。
- spider,是Spider对象,即Start Requests所属的Spider。
process_start_requests()必须返回另一个包含Request对象的可迭代对象。
3 . 结语
本节介绍了Spider Middleware的基本原理和自定义Spider Middleware的方法。Spider Middleware使用的频率不如Downloader Middleware的高,在必要的情况下它可以用来方便数据的处理。