1.准备测试用的client端机器、被测机
- client端测试机:
- 可以是其他的kafka集群
- 最好是云主机安装kafka
2.测试命令
$ cd kafka_2.11-1.0.1/bin/
#创建topic
./kafka-topics.sh --create --topic test --zookeeper node-zk-XXXXX:2181,node-zk-XXXXX:2181 --partitions 3 --replication-factor 3
#设置kafka消息保存时间
./kafka-configs.sh --zookeeper node-zk-XXXXX:2181,node-zk-XXXXX:2181 --entity-type topics --entity-name topic_36 --alter --add-config retention.ms=300000
#发送压测命令
./kafka-producer-perf-test.sh --topic xxx --num-records 10000000000 --record-size 1000 --throughput -1 --producer-props bootstrap.servers=xxx,xxx acks=xxx
#后台运行
nohup ./kafka-producer-perf-test.sh --num-records 50000000 --topic test_p30 --record-size 1000 --throughput -1 --producer-props bootstrap.servers=xxx,xxx acks=-1 >myout2 2>&1 &
- 可以输入ps -ef |grep producer,查看进程号,可以通过此方式kill 进程
- $KAFKA_HOME/bin/kafka-producer-perf-test.sh 该脚本被设计用于测试Kafka Producer的性能,主要输出4项指标,总共发送消息量(以MB为单位),每秒发送消息量(MB/second),发送消息总数,每秒发送消息数(records/second)。
3.批量启停kafka压测脚本
- sh XXXX.sh start 3
- sh XXXX.sh stop
#!/bin/bash
case $1 in
"start"){
for ((i=1;i<=$2;i++));
do
logfile=myout${i}
echo "********$logfile********"
./kafka-producer-perf-test.sh --num-records 50000000 --topic topic_12 --record-size 1000 --throughput -1 --producer-props bootstrap.servers=XXXXX:9092,XXXXX:9092 acks=-1 >${logfile} 2>&1 &
done
};;
"stop"){
producer_id=`ps -ef | grep producer | grep -v "grep" | awk '{print $2}'`
echo ${producer_id}
for id in ${producer_id}
do
kill $id
echo "killed $id"
done
};;
esac
4.查看被测机器磁盘消耗
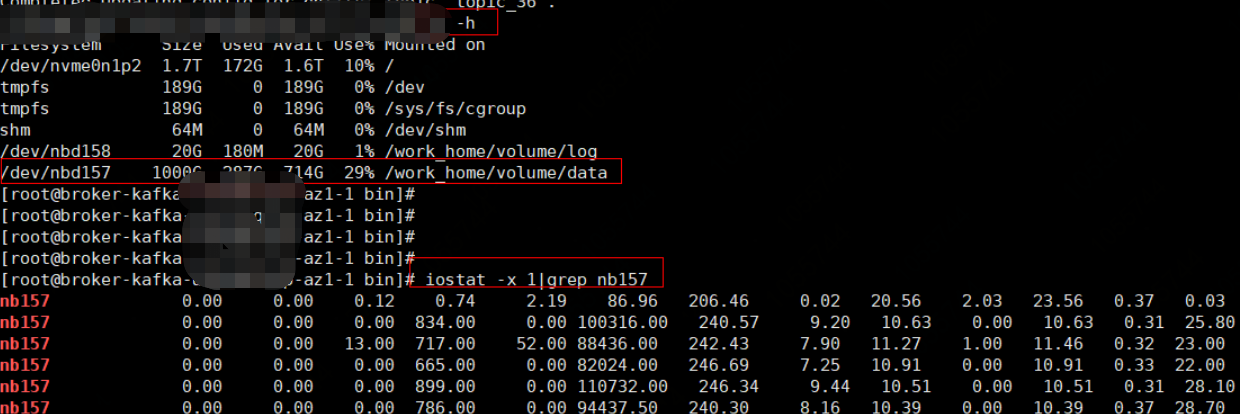
- df -h
- iostat -x 1|grep XXX ,若返回结果最后一列%util接近100%,表明I/O请求太多,I/O系统已经满负荷,磁盘可能存在瓶颈,一般%util大于70%,I/O压力就比较大,读取速度有较多的wait
可以参考https://blog.csdn.net/sinat_29581293/article/details/79085124
5.环境清理
- 清理topic信息:./kafka-topics.sh --delete --topic xxx --zookeeper xxx,xxx
6.找压测瓶颈测试思路
- 逐步加每个主机上的benchmark
- 发压机出现瓶颈,可以增多主机
- 增加分区数等