前言
ArrayList 作为 Java 集合框架中最常用的类,在一般情况下,用它存储集合数据最适合不过。知其然知其所以然,为了能更好地认识和使用 ArrayList,本文将从下面几方面深入理解 ArrayList:
- 为什么不用数组,用 ArrayList
- ArrayList 特性的源码分析
- Java 8 后 的 ArrayList
- 正确的 ArrayList 使用姿势
为什么不用数组,用 ArrayList。
在 Java 语言中,由于普通数组受到长度限制,初始化时就需要限定数组长度,无法根据元素个数动态扩容,并且 Java 数组供开发者调用方法有限,只有取元素,获取数组长度和添加元素一些简单操作。后台在 Java 1.2 引入了强大丰富的 Collection 框架,其中用 ArrayList 来作为可动态扩容数组的列表实现来代替 Array 在日常开发的使用,ArrayList 实现所有列表的操作方法,方便开发者操作列表集合。这里我们先列举下 ArrayList 的主要特点,在后文进行一一阐述:
-
有序存储元素
-
允许元素重复,允许存储
null值 -
支持动态扩容
-
非线程安全
为了更好地认识 ArrayList,我们首先来看下从 ArrayList 的UML类图: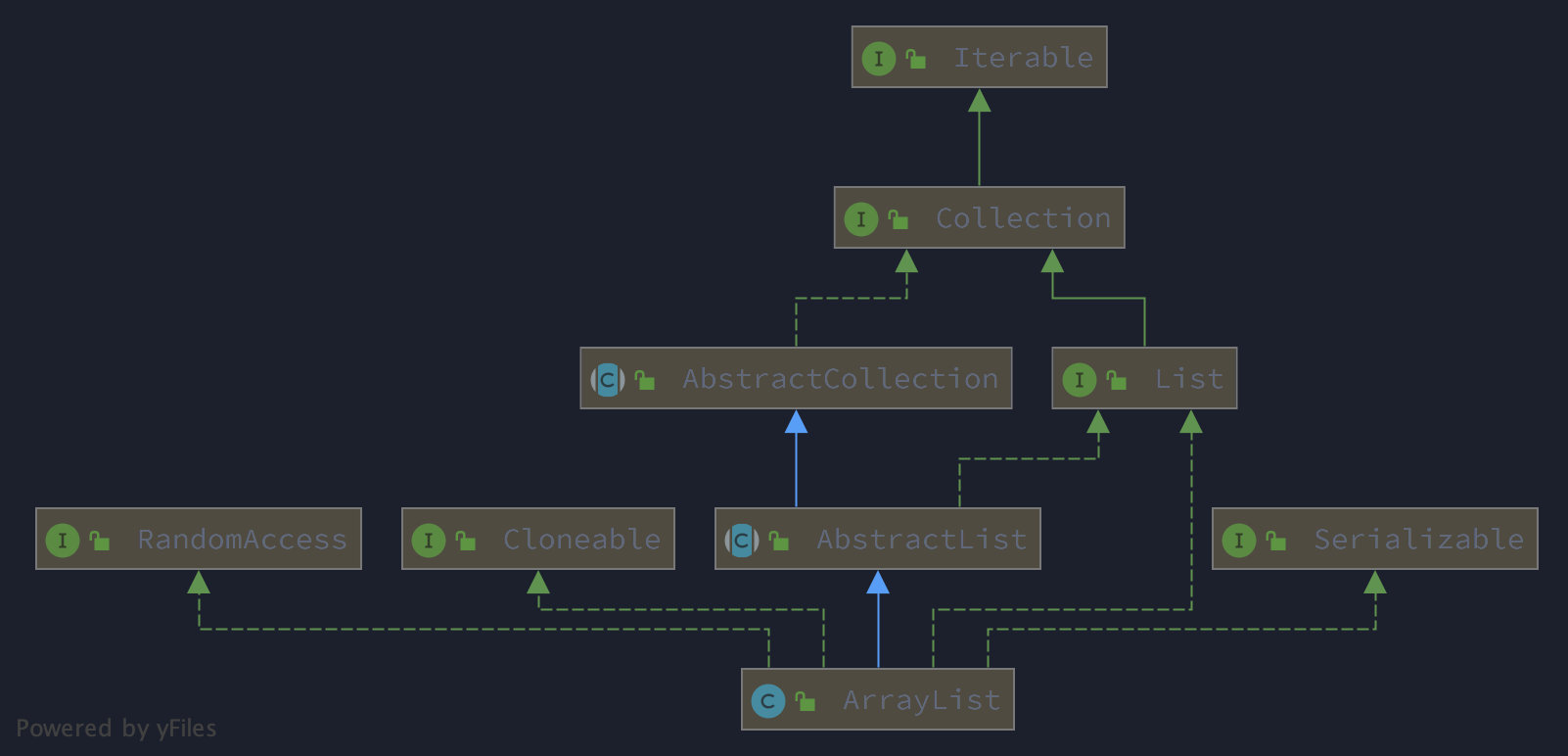
从上图可以看出 ArrayList 继承了 AbstractList, 直接实现了 Cloneable, Serializable,RandomAccess 类型标志接口。
- AbstractList 作为列表的抽象实现,将元素的增删改查都交给了具体的子类去实现,在元素的迭代遍历的操作上提供了默认实现。
- Cloneable 接口的实现,表示了 ArrayList 支持调用 Object 的
clone方法,实现 ArrayList 的拷贝。 - Serializable 接口实现,说明了 ArrayList 还支持序列化和反序列操作,具有固定的
serialVersionUID属性值。 - RandomAccess 接口实现,表示 ArrayList 里的元素可以被高效效率的随机访问,以下标数字的方式获取元素。实现 RandomAccess 接口的列表上在遍历时可直接使用普通的
for循环方式,并且执行效率上给迭代器方式更高。
ArrayList 源码分析
进入 ArrayList 源代码,从类的结构里很快就能看到 ArrayList 的两个重要成员变量:elementData 和 size。

elementData是一个 Object 数组,存放的元素,正是外部需要存放到 ArrayList 的元素,即 ArrayList 对象维护着这个对象数组 Object[],对外提供的增删改查以及遍历都是与这个数组有关,也因此添加到 ArrayList 的元素都是有序地存储在数组对象elementData中。size字段表示着当前添加到 ArrayList 的元素个数,需要注意的是它必定小于等于数组对象elementData的长度。一旦当size与elementData长度相同,并且还在往列表里添加元素时,ArrayList 就会执行扩容操作,用一个更长的数组对象存储先前的元素。
由于底层维护的是一个对象数组,所以向 ArrayList 集合添加的元素自然是可以重复的,允许为 null 的,并且它们的索引位置各不一样。
如何扩容
了解完 ArrayList 为何有序存储元素和元素可以重复,我们再来看下作为动态数组列表,底层扩容是如何实现的。
首先,要确定下扩容的时机会是在哪里,就如上面描述 size 字段时提到的,当 size 与 elementData 长度相同,此刻再添加一个元素到集合就会出现容量不够的情况,需要进行扩容,也就是说 ArrayList 的扩容操作发生在添加方法中,并且满足一定条件时才会发生。
现在我们再来看下 ArrayList 类的代码结构,可以看到有四个添加元素的方法,分为两类:添加单个元素和添加另一个集合内的所有元素。
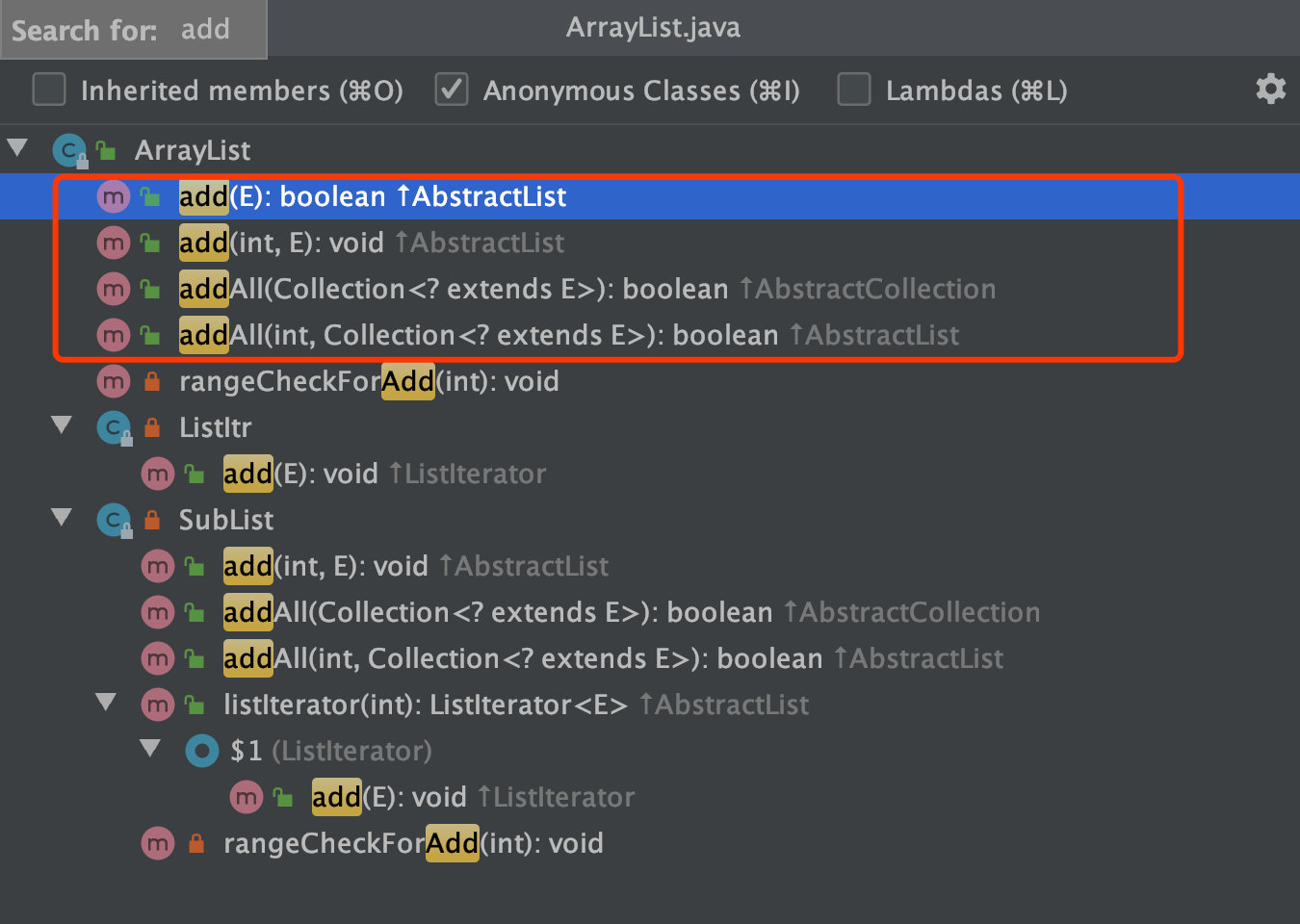
先从简单的方法下手分析,查看 add(E):boolean 方法实现:
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
从上面可以看出第三行代码是简单地添加单个元素,并让 size 递增加 1;那么扩容实现就在 ensureCapacityInternal 方法中,这里传入参数为 size+1,就是要在真正添加元素前判断添加后的元素个数,也就是集合所需要的最小容量是否会超过原数组的长度。再看下这个 ensureCapacityInternal 方法实现
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData,minCapacity));
}
其内部仍有两个方法调用,首先看下比较简单的 calculateCapacity 方法:
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
当 elementData 与 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 相等,也就是空数组时,返回一个可添加元素的默认最小容量值 DEFAULT_CAPACITY 对应的10 ,否则按照传入的 size +1 为最小容量值;执行完之后接着看 ensureExplicitCapacity 方法:
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
从代码中可以看到扩容实现在 grow 方法之中,并且只有当数组长度小于所需要的最小容量时执行:当数组存储元素已满,无法再存储将新加入的元素。
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
进一步跳转到 grow 方法的实现,可以看到第8行利用工具类方法 java.util.Arrays#copyOf(T[], int) ,对原有数组进行拷贝,将内部所有的元素存放到长度为 newCapacity 的新数组中,并将对应新数组的引用赋值给 elementData。此刻 ArrayList 内部引用的对象就是更新长度了的新数组,实现效果就如下图一样:
现在我们再来关注下代表数组新容量的 newCapacity 被调整为多少。首先 newCapacity 通过 oldCapacity + (oldCapacity >> 1) 计算获得,使用位运算将原容量值 oldCapacity 通过右移一位,获得其一半的值(向下取整), 然后加上原来的容量值,那么就是原容量值 oldCapacity 的1.5倍。
>>右位运算符,会将左操作数进行右移,相当于除以2,并且向下取整,比如表达式(7 >> 1) == 3结果为真。
当计算得到的 newCapacity 仍然小于传入最小容量值时,说明当前数组个数为空,采用默认的 DEFAULT_CAPACITY作为容量值分配数组。
额外需要注意的是还有最大数组个数的判断,MAX_ARRAY_SIZE 在文件对应的代码定义如下:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
ArrayList 存储元素个数有最大限制,如果超过限制就会导致 JVM 抛出 OutOfMemoryError 异常。
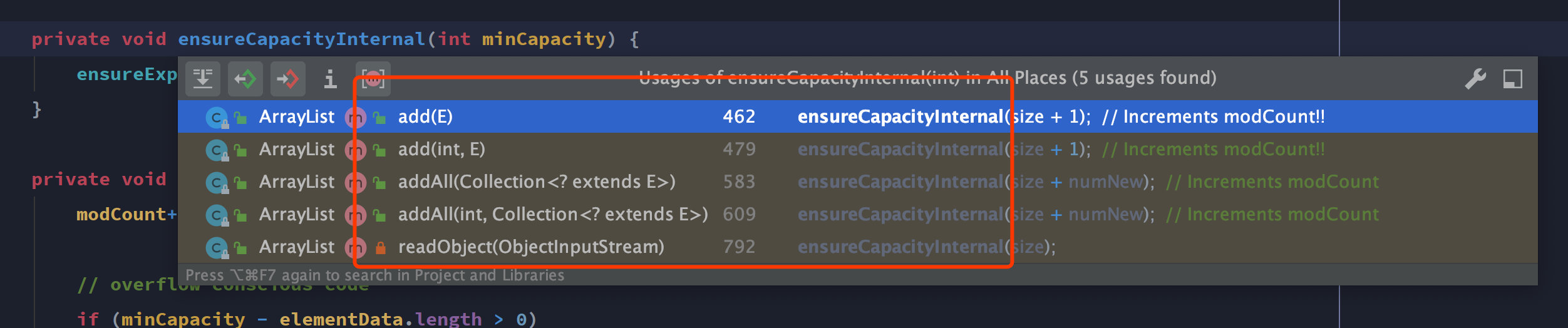
到这里 java.util.ArrayList#add(E) 方法的扩容逻辑就分析结束了。类似的,在其他添加元素的方法里实现内我们都可以看到 ensureCapacityInternal 方法的调用,在真正操作底层数组前都会进行容量的确认,容量不够则进行动态扩容。
序列化与反序列化
transient Object[] elementData;
在 ArrayList 源码看到的 elementData 带有关键字 transient,而通常 transient 关键字修饰了字段则表示该字段不会被序列化,但是 ArrayList 实现了序列化接口,并且提供的序列化方法 writeObject 与反序列化方法 readObject 的实现, 这是如何做到的呢?

我们首先来看下 ArrayList 进行序列化的代码:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
int expectedModCount = modCount;
s.defaultWriteObject();
s.writeInt(size);
for (int i = 0; i < size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
第4行代码首先将当前对象的非 static 修饰,非 transient 修饰的字段写出到流中;第6行将写出元素的个数作为容量。
接下来就是通过循环将包含的所有元素写出到流,在这一步可以看出 ArrayList 在自己实现的序列化方法中没有将无存储数据的内存空间进行序列化,节省了空间和时间。
同样地,在反序列化中根据读进来的流数据中获取 size 属性,然后进行数组的扩容,最后将流数据中读到的所有元素数据存放到持有的对象数组中。
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
s.defaultReadObject();
s.readInt(); // ignored
if (size > 0) {
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
for (int i = 0; i < size; i++) {
a[i] = s.readObject();
}
}
}
关于拷贝
针对列表元素的拷贝,ArrayList 提供自定义的 clone 实现如下:
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
从上述代码可以清楚看出执行的 copyOf 操作是一次浅拷贝操作,原 ArrayList 对象的元素不会被拷贝一份存到新的 ArrayList 对象然后返回,它们各自的字段 elementData 里各位置存放的都是一样元素的引用,一旦哪个列表修改了数组中的某个元素,另一个列表也将受到影响。
JDK 1.8 后的 ArrayList
从源码角度分析完 ArrayList 的特性之后,我们再来看下 JDK 1.8 之后在 ArrayList 类上有什么新的变化。
新增 removeIf 方法
removeIf 是 Collection 接口新增的接口方法,ArrayList 由于父类实现该接口,所以也有这个方法。removeIf 方法用于进行指定条件的从数组中删除元素。
public boolean removeIf(Predicate<? super E> filter){...}
传入一个代表条件的函数式接口参数 Predicate,也就是Lambda 表达式进行条件匹配,如果条件为 true, 则将该元素从数组中删除,例如下方代码示例:
List<Integer> numbers = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
numbers.removeIf(i -> i % 2 == 0);
System.out.println(numbers); // [1, 3, 5, 7, 9]
新增 spliterator 方法
这个方法也是来自于 Collection 接口,ArrayList 对此方法进行了重写。该方法会返回 ListSpliterator 实例,该实例用于遍历和分离容器所存储的元素。
@Override
public Spliterator<E> spliterator() {
return new ArrayListSpliterator<>(this, 0, -1, 0);
}
在 ArrayList 的实现中,该方法返回一个内部静态类对象 ArrayListSpliterator,通过它可以就可以集合元素进行操作。
它的主要操作方法有下面三种:
tryAdvance迭代单个元素,类似于iterator.next()forEachRemaining迭代剩余元素trySplit将元素切分成两部分并行处理,但需要注意的 Spliterator 并不是线程安全的。
虽然这个三个方法不常用,还是有必要了解,可以简单看下方法的使用方式
ArrayList<Integer> numbers = new ArrayList<>(Arrays.asList(1,2,3,4,5,6));
Spliterator<Integer> numbers = numbers.spliterator();
numbers.tryAdvance( e -> System.out.println( e ) ); // 1
numbers.forEachRemaining( e -> System.out.println( e ) ); // 2 3 4 5 6
Spliterator<Integer> numbers2 = numbers.trySplit();
numbers.forEachRemaining( e -> System.out.println( 3 ) ); //4 5 6
numbers2.forEachRemaining( e -> System.out.println( 3 ) ); //1 2 3
必会的使用姿势
接触了 ArrayList 源码和新API 之后,我们最后学习如何在平常开发中高效地使用 ArrayList。
高效的初始化
ArrayList 实现了三个构造函数, 默认创建时会分配到空数组对象 EMPTY_ELEMENTDATA;第二个是传入一个集合类型数据进行初始化;第三个允许传入集合长度的初始化值,也就是数组长度。由于每次数组长度不够会导致扩容,重新申请更长的内存空间,并进行复制。而让我们初始化 ArrayList 指定数组初始大小,可以减少数组的扩容次数,提供性能。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
this.elementData = EMPTY_ELEMENTDATA;
}
}
元素遍历
JDK 1.8前,ArrayList 只支持3种遍历方式:迭代器遍历,普通 for 循环,for-each 增强,在 JDK1.8 引入了 Stream API 之后,同属于 Collection 集合的 ArrayList,可以使用 stream.foreach() 方法一个个地获取元素:
ArrayList<String> names = new ArrayList<String>(Arrays.asList( "alex", "brian", "charles"));
names.forEach(name -> System.out.println(name)); // alex brian charles
转换 Array
ArrayList 提供两个方法用于列表向数组的转换
public Object[] toArray();
public <T> T[] toArray(T[] a);
- 第一个方法直接返回 Object 类型数组
- 在第二个方法中,返回数组的类型为所传入的指定数组的类型。 并且如果列表的长度符合传入的数组,将元素拷贝后数组后,则在其中返回数组。 否则,将根据传入数组的类型和列表的大小重新分配一个新数组,拷贝完成后再返回。
从上述描述可以看出使用第二个方法更加合适,能保留原先类型:
ArrayList<String> list = new ArrayList<>(4);
list.add("A");
list.add("B");
list.add("C");
list.add("D");
String[] array = list.toArray(new String[list.size()]);
System.out.println(Arrays.toString(array)); // [A, B, C, D]
应对多线程
在这里需要说明的是 ArrayList 本身是非线程安全的,如果需要使用线程安全的列表通常采用的方式是 java.util.Collections#synchronizedList(java.util.List<T>) 或者 使用 Vector 类代替。还有一种方式是使用并发容器类 CopyOnWriteArrayList 在多线程中使用,它底层通过创建原数组的副本来实现更新,添加等原本需同步的操作,不仅线程安全,减少了对线程的同步操作。
应对头部结点的增删
ArrayList是数组实现的,使用的是连续的内存空间,当有在数组头部将元素添加或者删除的时候,需要对头部以后的数据进行复制并重新排序,效率很低。针对有大量类似操作的场景,出于性能考虑,我们应该使用 LinkedList 代替。由于LinkedList 是基于链表实现,当需要操作的元素位置位于List 前半段时,就从头开始遍历,马上找到后将把元素在相应的位置进行插入或者删除操作。
结语
到这里我们学习总结 ArrayList 的实现和常见使用,作为基础容器集合,越是多些了解,对我们日常使用越顺手。由于上文提到了另一个列表集合 LinkedList,它与 ArrayList 实现方式不同,使用场景也不同,将作为下一篇文章分析的集合登场,感兴趣的小伙伴欢迎关注我的微信公众号,期待更新。
