部署规划
三台centos7虚拟机
172.17.9.27 Master
172.17.9.28 Slave1
172.17.9.29 Slave2
步骤:
一、添加用户
# 创建新用户hadoop
useradd -m hadoop -s /bin/bash
设置密码
passwd hadoop
添加管理员权限
visudo
二、centos默认安装了ssh
三、安装jdk
解压安装包:tar -zxvf openjdk-7u75-b13-linux-x64-18_dec_2014.tar.gz
mv -r java-se-7u75-ri/ /usr/java/
配置
vim /etc/profile
把以下代码添加到profile文件的done行下面:
export JAVA_HOME= /usr/java/
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
让修改的文件生效:source /etc/profile
查看Java安装结果
java -version
四、修改host
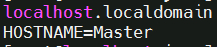
vim /etc/hostname
添加:HOSTNAME=Master
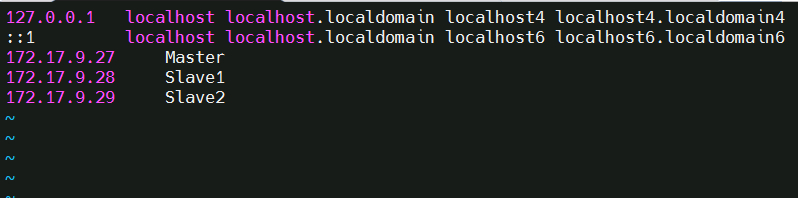
五、修改IP映射
vim /etc/hosts
六、ssh无密码登录节点
Master 节点可以无密码 SSH 登陆到各个 Slave 节点上
首先生成 Master 节点的公匙,在 Master 节点的终端中执行
# 如果没有该目录,先执行一次ssh localhost
cd ~/.ssh
# 删除之前生成的公匙(如果有)
rm ./id_rsa*
# 一直按回车就可以
ssh-keygen -t rsa
在Master节点上运行
cat ./id_rsa.pub >> ./authorized_keys
完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到 全部的Slave 节点:
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
七、配置slave节点
在其他 Slave 节点上配置 hadoop 用户、设置sudo权限,安装 Java 环境,设置映射
接着在 SlaveX 节点上,将 ssh 公匙加入授权:
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
八、安装Hadoop
解压安装好的
tar -xzvf hadoop-2.7.2.tar.gz
mv hadoop-2.7.1 /usr/hadoop
# 修改文件权限
sudo chown -R hadoop:hadoop ./hadoop
检查Hadoop是否可用,以下截图为成功截图,输出了版本
./bin/hadoop version
将 Hadoop 安装目录加入 PATH 变量中,这样就可以在任意目录中直接使用 hadoo、hdfs 等命令了,如果还没有配置的,需要在 Master 节点上进行配置。首先执行 vim ~/.bashrc,加入一行:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
保存后执行 source ~/.bashrc 使配置生效。
九、配置集群分布式环境
集群/分布式模式需要修改 /usr/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1, 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
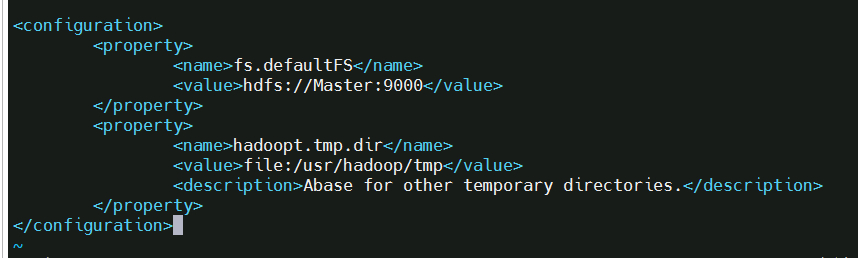
2, 文件 core-site.xml 改为下面的配置:
3, 文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有两个 Slave 节点,所以 dfs.replication 的值还是设为 2:
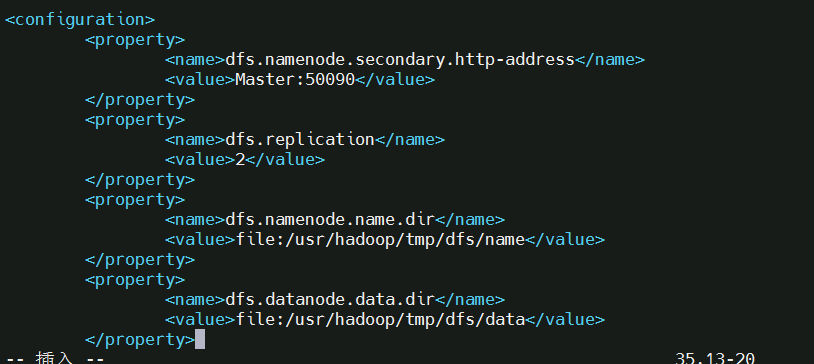
4, 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
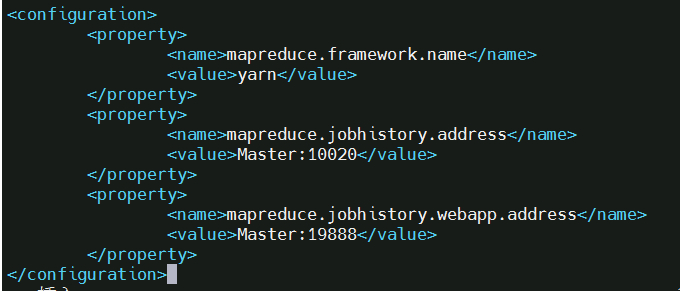
5, 文件 yarn-site.xml:
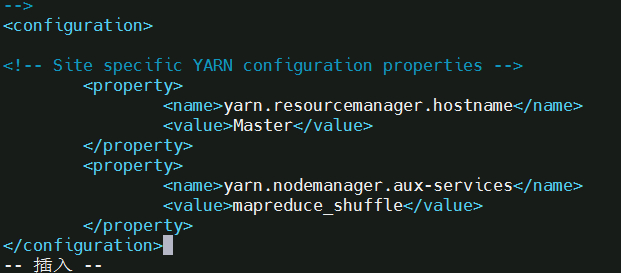
配置好后,将 Master 上的 /usr/hadoop 文件夹复制到各个节点上
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
在 Slave1 节点上执行:注意上面最后一行的Slave1,其他节点可改为Slave2,3,4等,同样下面也要在不同的节点允许

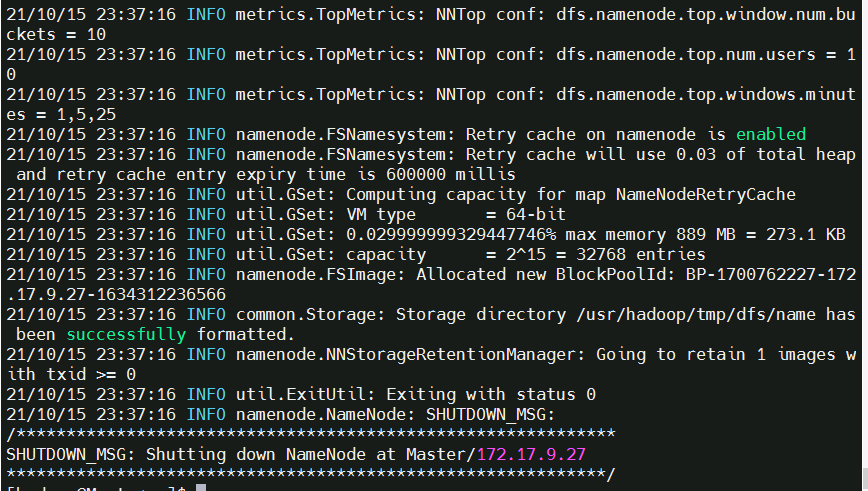
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
关闭防火墙centos7
systemctl stop firewalld.service # 关闭firewall systemctl disable firewalld.service # 禁止firewall开机启动
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
start-dfs.sh
出错了 Slave1 Error:JAVA_HOME is not set and could not be findz
修改hadoop路径下etc/hadoop/hadoop-env.sh文件,将默认JAVA_HOME=$JAVA_HOME改成JAVA平台的实际安装目录,
例如:export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386
start-yarn.sh
设置ssh密钥的时候需要用Hadoop账号,不然会出错。
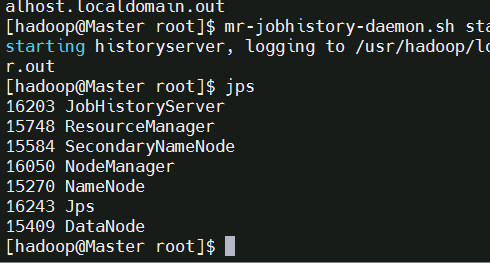
mr-jobhistory-daemon.sh start historyserver
通过命令
jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
hdfs dfsadmin -report命令,查看HDFS试用情况

关闭:把stop-dfs.sh 改成 stop-all.sh