
今天下午花时间学习了python爬虫的中国大学排名实例,颇有心得,于是在博客园与各位分享
首先直接搬代码:
import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def fillUnivList(ulist, html): soup = BeautifulSoup(html,"html.parser") for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag): tds = tr.find_all('td') ulist.append([tds[0].string,tds[1].string,tds[3].string]) def printUnivList(ulist,num): tplt = "{0:^10} {1:{3}^10} {2:^10}" print(tplt.format("排名","学校","总分",chr(12288))) for i in range(num): u = ulist[i] print(tplt.format(u[0],u[1],u[2],chr(12288))) def main(): uinfo = [] url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo,20) main()
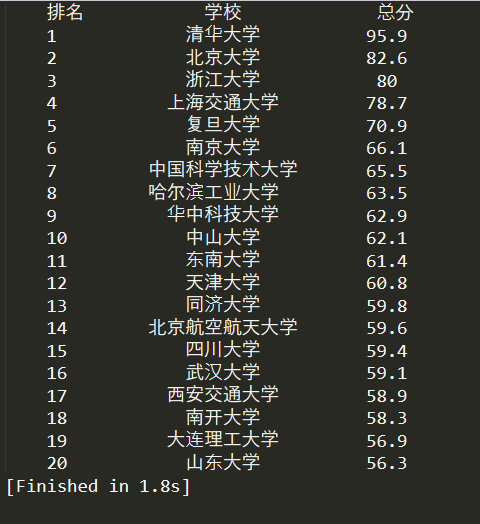
再附上大学排名截图:
那么,现在开始代码心得讲解:
首先开始分析网页结构:
打开http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
打开chrome网页分析工具:
可以发现大学排名,学校名称,省市,总分等都处在tbody标签内
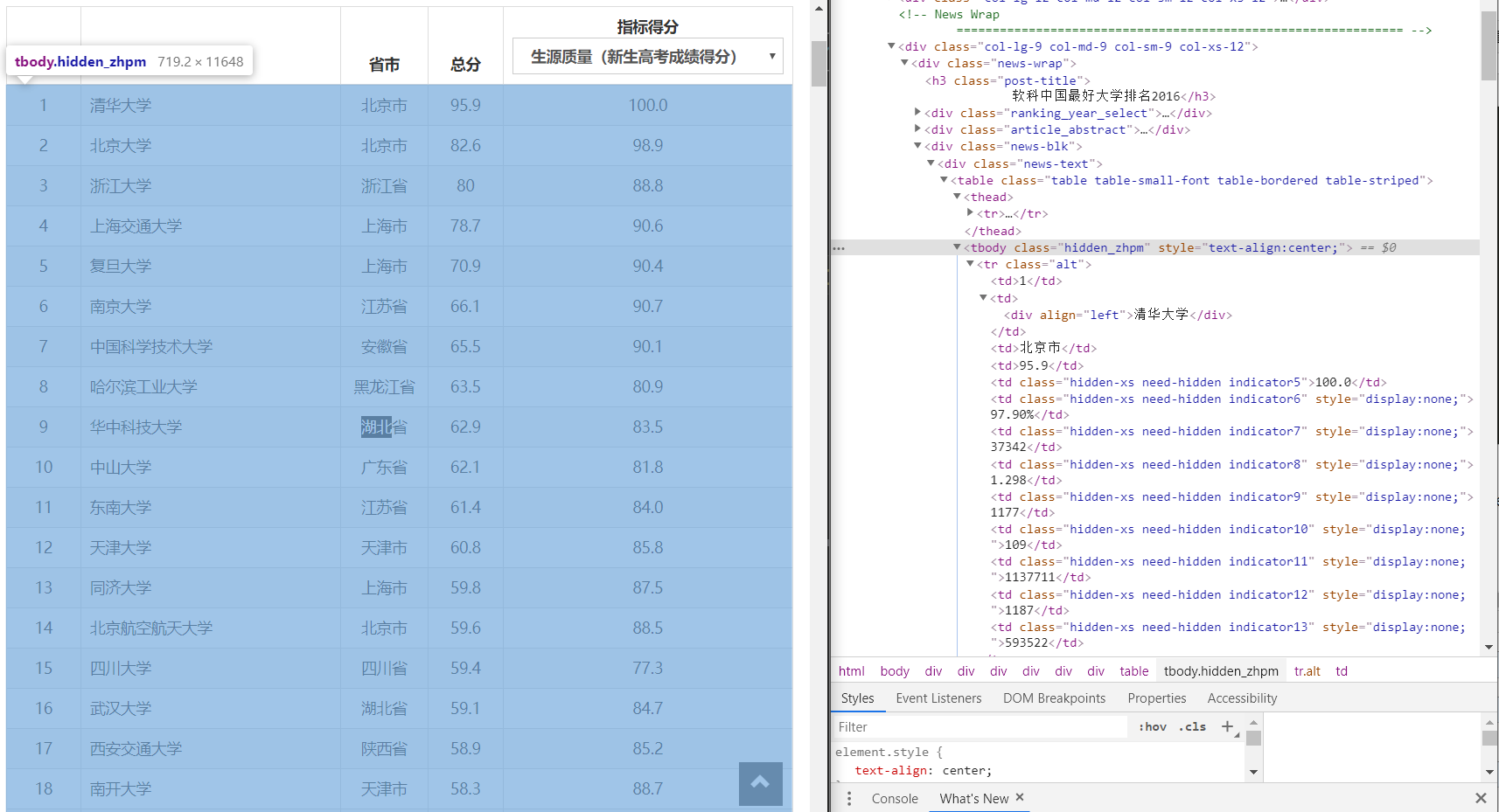
而大学名称、省市等,都处于tr标签内的td中

好,分析完成,开始构建函数架构:

主要思想为:获取网页html文本,得到需求数据,并将需求数据转化为列表,最后将列表输出
下一步:开始补充getHTMLText()部分的代码:

这里我用try except形式编写代码:
首先获取网页url,时限为30s,j接着运用 r.raise_for_status()(如果 HTTP 请求返回了不成功的状态码, r.raise_for_status() 会抛出一个 HTTPError异常)
然后将网页转码为r.apparent_encoding
返回一个r.text
这里代码运行中如果出现错误,则会return "",返回一个空字符串
接下来开始编写fillUnivList()部分代码

我们先做一锅汤,定义为soup,然后在这锅汤中遍历tr的孩子,这里每一个tr都对应一所大学的信息
而且我们需要滤掉非标签类型的其他信息,所以运用isinstance对函数类型做一个判断
if isinstance(tr,bs4.element.Tag):
这行代码就是检测标签类型,如果标签不是bs4库定义的类型,将过滤掉,同时为了运用这个方法,我们也就需要引入bs4库
由于tr标签已经被解析出来,接下来就需要对tr标签中的td标签做查询
if isinstance(tr,bs4.element.Tag): tds = tr.find_all('td')
这里把查询到的td标签存入tds列表中
再然后在ulist表中增加:排名,大学名和总分的对应字段
ulist.append([tds[0].string,tds[1].string,tds[3].string])
接着来编写printUnivList()函数
注意:这里的{:^10}表示取10位居中对齐,^是居中对齐, 是横向制表符。
