BERT:
老大哥模型,模型的两个目标MLM和NSP,采用静态Masking(模型预训练之前已经确定了Masking的位置)
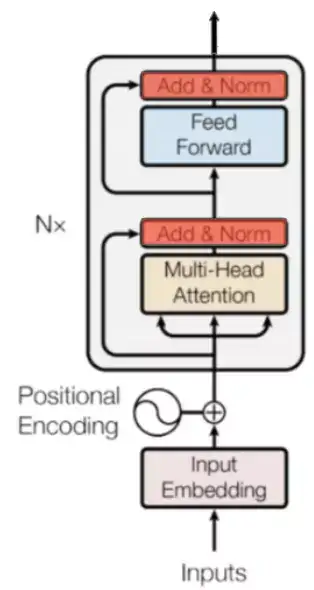
ALBERT:
bert模型的精简版本,参数更少,训练更快,主要有以下改动:
- 矩阵分解。词向量V到encoder全连接M进行分解,bert中参数量:V*M,ALBERT:V*H+M*H=(V+M)*H,H可以比较小,因为词的数目有限的,和下游的语义相比可以有更小的维度
- 贡献权重。encoder权重贡献(当然也可以只共享Multi-head attention或者feed forwa neural network)
- SOP代替NSP。NSP是第二个句子通过采样获得,预测其是不是后面一个句子;SOP,将前后两个句子颠倒,预测句子的顺序
span BERT:
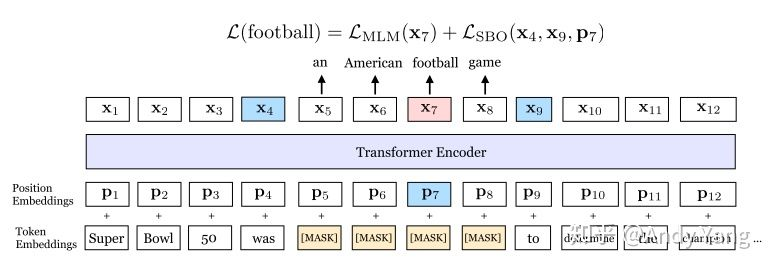
参考https://zhuanlan.zhihu.com/p/75893972
fast BERT:
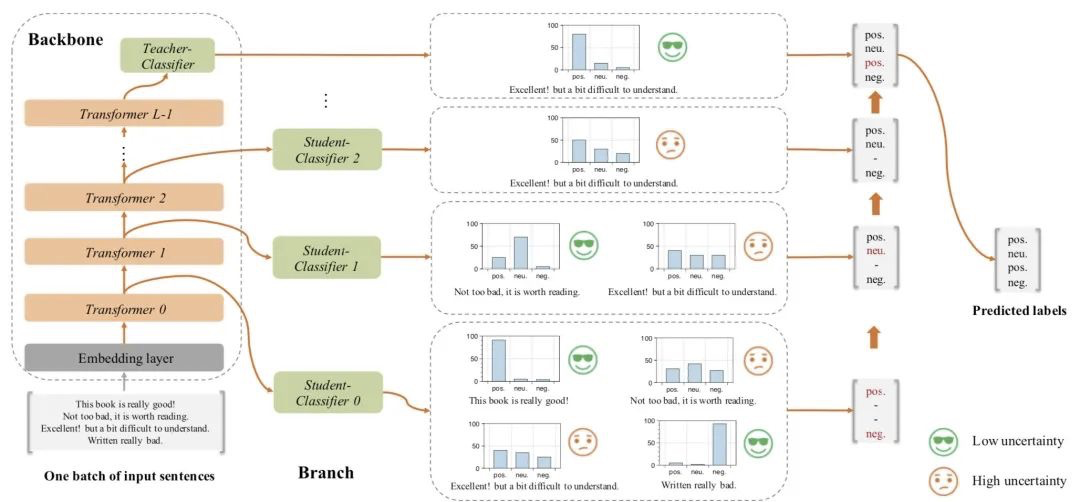
参考链接:https://mp.weixin.qq.com/s/TtpD3EEXWQUkvfB1AVl7ig
其他的以后再写吧。。。。