HBase的数据写入操作,会先记录到HLog中,再真正写入到MemStore中。
前者是对写入友好的格式,后者是对查询友好的格式。所以前者吞吐量更高,写入成功率大,提高了系统的可靠性,“基本”可以实现宕机后继续没有完成的数据更新操作。
API
WAL interface提供了对外的WAL API。
其中最常用的方法是append()。
long append(HRegionInfo info, WALKey key, WALEdit edits, boolean inMemstore) throws IOException;
它追加写入一系列WALEdit。
API的调用方
每一个HBase region有一个单独的WAL interface的实例:

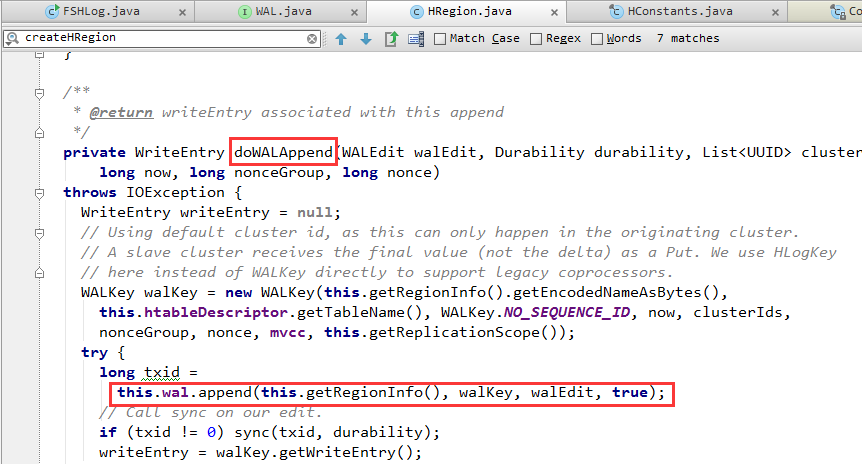
HBase客户端 == Protobuf协议 ==> HRegionServer.execRegionServerService() => MultiRowMutationProtos.callMethod() => MultiRowMutationProtos.mutateRows()=> MultiRowMutationEndpoint.mutateRows() => HRegion.processRowsWithLocks() =>HRegion.doWALAppend()会写入WAL。
HRegion.processRowsWithLocks()是HRegion更新操作的总控方法——驱动了 获取所、写入WAL、写入MemStore 这一流程。
原子性
为了实现HBase写入一行里的多个列时的原子性,对一行上所有列(即所有KeyValue)的更新操作,都包含在同一个WALEdit对象中:

所以WALEdit中最主要的成员变量,是一系列KeyValue(也就是Cell)的集合:

AbstractFSWAL —— 为基于文件系统的WAL实现,提供通用支持
AbstractFSWAL.findRegionsToForceFlush() - 返回当前WAL实例中最老的文件所包含的、还完全被Flush掉的Region
所谓Flush应该是指将这个Region的业务数据从MemStore写入Store。
如果一个Region被Flush了,那么其业务数据已经落地到了HFile中。则这个Region的WAL日志(数据操作记录)就没有必要存在了,可以删除,以腾出磁盘空间。
AbstractFSWAL.findRegionsToForceFlush() 用于找到已经被Flush的、相应WAL日志可以被删除的Region。
1. 从AbstractFWSAL.byWalRegionSequenceIds找到第一个文件。
ConcurrentNavigableMap<Path, Map<byte[], Long>> byWalRegionSequenceIds 维护了当前WAL的所有文件,以及每个文件所涉及的Region (包括Region的byte[]名称和这个Region中最后一次append操作的sequence id)
即 Path (WAL文件名) => (byte[] Region名称, Long sequence id)

2. 从第一个文件,找到它的所有Region中,哪些还没有被Flush
ConcurrentMap<byte[], ConcurrentMap<byte[], Long>> AbstractFWSAL.SequenceIdAccounting.lowestUnflushedSequenceIds 维护了byte[] Region名称 + byte[] family名称 到第一个(即最小的)没有被Flush的sequence id的映射,称为lowestUnflushedSequenceId。这里,每一次append操作对应一个自增的sequence id。所有大于等于lowestUnflushedSequenceId的sequence id,其对应的append操作都没有被Flush。
因此对于第一步得到的第一个WAL日志文件所涉及的所有Region, 和每个Region的最大sequence id,如果这个最大的sequece id大于这个Region的lowestUnflushedSequenceId,说明这个Region有WAL日志还没有被Flush。那么这个Region就会被包含在findRegionsToForceFlush()的结果中。