如果我有100W个小文件,每个接近100K,然后我要放到一个目录里面,NTFS的子目录是否能够承受住单个目录存放100W的文件?如果采用sql server 2008的File Stream功能呢?我们知道SQL Server 2008启用了Filestream的字段的表,是一个字段放到一个子目录,如果我100W条记录都放在一个表里面,对应磁盘上仍然是1个子目录会有100W个文件。那结果会怎样?
在很多流言中,有一些认为一个子目录存放超过10W的文件会产生不稳定的情况,通常在遇到这种场景,都直接建议采用分级目录存放,包括我们在一个表里面插入100W条记录。但是windows ntfs和sql server真的有这么差吗?当然不会,我们知道sql server 2008即使管理100T数据也没有问题。而网上最广泛的流言之一就是Oracle的性能比sql server的性能好,这个流言是在sql server 2000的时候产生的,那个时候是事实,但是sql server 2005已经改变了这一状况,而sql server 2008则彻底颠覆了这种情况,但是,流言,仍然继续的流传了下来(看看最新的TPC-E排名:http://www.tpc.org/tpce/results/tpce_perf_results.asp ,TPC-E可是比TPC-C的更新的基准测试哦)。还有一个著名的流言就是SharePoint列表中不要存放超过2000条记录,否则将引起性能的严重下降,这个流言在SharePoint 2003的时候是属实的,但是在SharePoint 2007里面就已经改善了,流言也仍然传了下来。
首先说一下今天要讨论的场景,既然要在sql server 2008里面存放100W个文件,那么显然这是一个服务端应用,而不是一个客户端应用,因为没有人会手动的从100W个文件中去挑选什么。我的 测试环境如下:
OS: Windows Server 2008 R2
硬盘: SATA 日立 1T 7200转
CPU:双核 2G
数据库: SQL Server 2008 Enterprise(MSDN license)
可用内存:足够大(不会出产生内存不足而导致的额外硬盘交换,占用IO的情况)
测试文件大小:90K,也即将插入90K的文件100W份,相当于将这个文件复制了100W份。
真正的服务器一般采用SCSI高速硬盘,所以IO状态会比我的测试机器好很多,而这台机器是我的开发用机,在1T的硬盘上还有3个虚机在同时运行,所以相对而言IO是比较差的。如果在我这台机器上能够承受的住,我相信在真正的服务器上都不会有任何问题。
测试代码:
 代码
代码

2 {
3 SqlConnection conn = new SqlConnection("Data Source=.;Initial Catalog=NorthPole;Integrated Security=SSPI;");
4 conn.Open();
5 SqlCommand cmd = new SqlCommand();
6 cmd.Connection = conn;
7 cmd.CommandText = "AddFile";
8 cmd.CommandType = System.Data.CommandType.StoredProcedure;
9
10 DateTime begin = DateTime.Now;
11 for (int i = 1; i < 100001; i++)
12 {
13 cmd.ExecuteNonQuery();
14 Console.WriteLine("{0} rows are inserted!", i);
15 }
16 DateTime end = DateTime.Now;
17 conn.Close();
18
19 TimeSpan t = end - begin;
20 Console.WriteLine("{0} Days, {1} Hours, {2} Minutes, {3} Seconds", t.Days, t.Hours, t.Minutes, t.Seconds);
21 Console.ReadLine();
22 }
23
里面的AddFile是存储过程:
代码
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
DECLARE @img AS VARBINARY(MAX)
-- Load the image data
SELECT @img = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'D:\temp\test.jpg',
SINGLE_BLOB ) AS x
-- Insert the data to the table
INSERT INTO Items (ItemID, ItemImage)
SELECT NEWID(), @img
END
我首先插入了10W条记录到数据库中,执行结果如下:

由于我担心Console.WriteLine和i++这两句代码耗费时间过多,所以做了一下时间补偿,将cmd.ExecuteNonQuery()注释掉,然后做10W次空循环,结果如下:

基本不会对结果产生什么影响。
效率:总共:3757秒,0.03757秒/条
然后我将循环改成了90W次,往数据库插入90W条记录,执行结果如下:

时间补偿:
![]()
效率:总共:52674秒, 0.0585秒/条。
随着记录数的增多,显然速度会变慢,不过这点效率损失基本还能够忍受。
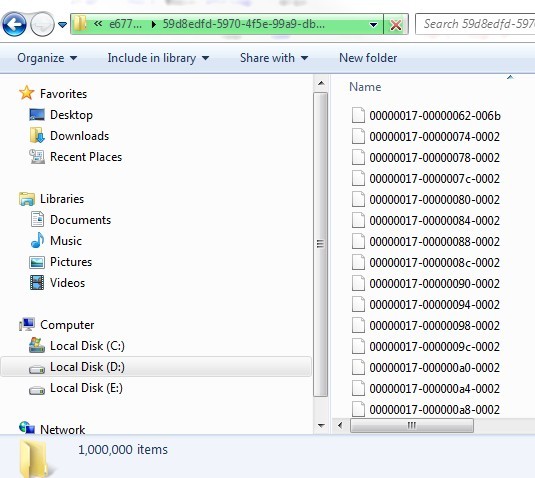
虽然对应的目录里面存放了100W的记录,但是目录还是能够打开,不过windows文件管理器的响应速度会变慢,当然这个主要原因应该是widnows文件管理器的原因,毕竟100W条数据不是一个小数字。我们能够看到这个目录有100W项目。

通过sql语句:
SELECT TOP 1000 [ItemID]
,[ItemImage]
FROM [NorthPole].[dbo].[Items]
取前1000行记录,大约用时16秒。

很明显,sql server 具有很好的缓存功能,当我再次执行这条语句的时候,仅仅用时6秒。
![]()
随后我执行了几次,基本都维持在6、7秒的样子。
在取任何一条记录的时候,时间都是0秒。我这里感觉不到速度的差异。
关于如何使用SQL Server File Stream功能,这里有一篇blog写的非常详细:http://www.simple-talk.com/sql/learn-sql-server/an-introduction-to-sql-server-filestream/
从我个人的感觉来说,基本没有什么问题,而且如果换成专门的服务器,采用快速的SCSI硬盘,效率应该比我现在的测试结果要好上很多。
当然上述结果仅供参考,如果你需要采用的话,建议在你的真实环境里面再实际测试一遍。毕竟不同的环境,可能得到的结果不相同。
附加,额外的: