分组数据,为了能汇总表内容的子集,主要使用 GROUP BY(分组) 子句、HAVING(过滤组) 子句和ORDER BY(排序) 子句
之前所有的计算都是在表中所有的数据或匹配特定的where 子句的数据上进行的,针对的只是单独的某一个或某一类,而分组函数允许把数据分成多个逻辑组,然后再对每个逻辑组进行聚集函数计算,这样的使用场景更广,更直观精细
1、简单使用
-- 求出 以order_num 为分组的行数 select order_num,count(*)as sumOrder from orderitems group by order_num;
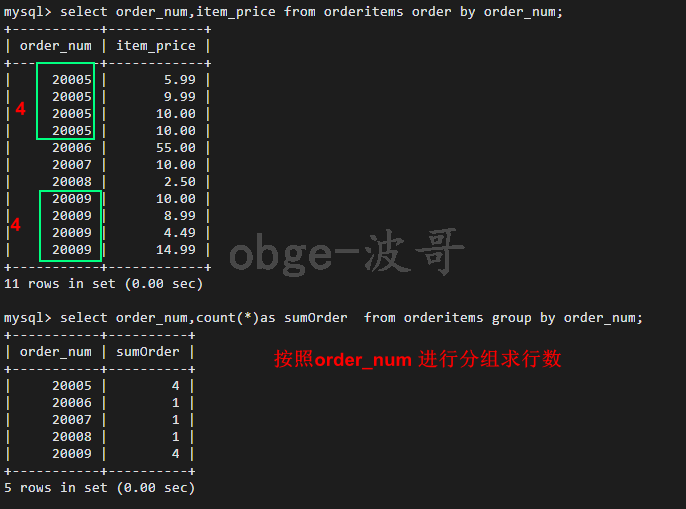
group by 子句指示mysql 按照order_num 排序并分组,导致count() 对每个分组的order_num 计算,而不是对整个表进行计算。
注意:
1、group by 子句可以包含任意数目的列,使得能对分组进行嵌套,为数据分组提供更细致的控制
2、如果在group by 子句中嵌套了分组,数据将在最后规定的分组上进行汇总。在建立分组时,指定的所有列都一起计算,所以不能从个别的列取回数据
3、group by 子句中列出的每个列都必须是检索列或有效的表达式,但不能是聚集函数,如果在select 中使用表达式,则必须在group by 子句中指定相同的表达式,不能使用别名。
4、除聚集计算的语句外,select 语句中的每个列都必须在group by 子句中给出
5、如果分组列中具有 null 值,则null 作为一个分组返回,如果列中有多行null 值,将分成一组
6、group by 子句必须在where 子句的后面,order by 子句的前面。
7、可以使用WITH ROLLUP 对每个分组进行汇总,得到总行数

2、过滤分组(Having) :规定包括哪些分组,排除哪些分组
一看你是不是想到了,where 子句,但是不行的哦,where 子句针对的是行,而不是组,所以这个时候 HAVING 来了,用于过滤分组。
-- 将三个以下的过滤掉,获取 大于等于三的单子
select order_num,count(*)as sumOrder from orderitems group by order_num having count(*)>=3;

可以发现,是先分组,在根据分组的情况进行过滤
注意: where 子句与Having子句
1、where 子句用于过滤行,having 子句用于过滤组
2、与where子句的用法基本一致,where 子句的条件(通配符、操作符等) having 也适用
3、过滤的先后顺序不一样,where 在数据分组前过滤,Having 在数据分组后过滤
验证: where 排除的行,会不会影响到having 分组
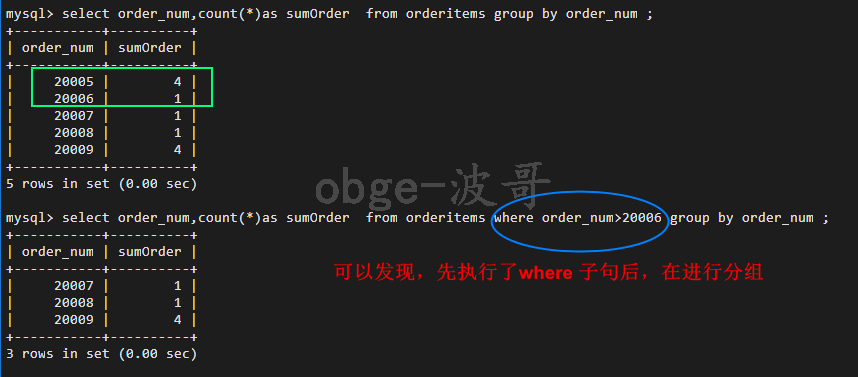
发现,书写的先后顺序是有道理的。
3、分组和排序
虽然group by 和 order by 经常完成相同的工作,但是他们是非常不同的
注意: group by 与 order by 的差别
1、group by 分组的数据,虽然是以分组的顺序分组的,但是情况并不总是这样的,因为不是SQL规范要求的,而且用户也可能会要求不同的分组顺序进行排序,所以不要仅依赖group by 的排序,也要给出group by 子句。
2、group by只能使用选择的列或表达式列(而且必须使用每个选择的表达式),order by 任意列都可以使用(甚至非选择的列也可以使用)
3、group by 如果与聚集函数一起使用列(或表达式),则必须使用,order by 不一定需要
-- 求出总价格按照order_num 进行分组,找出总价格大于100 的检索出,顺变按照总价格排个序 select order_num,sum(quantity*item_price) as sumTotalPrice from orderitems group by order_num having sum(quantity*item_price)>100 order by sumTotalPrice ;
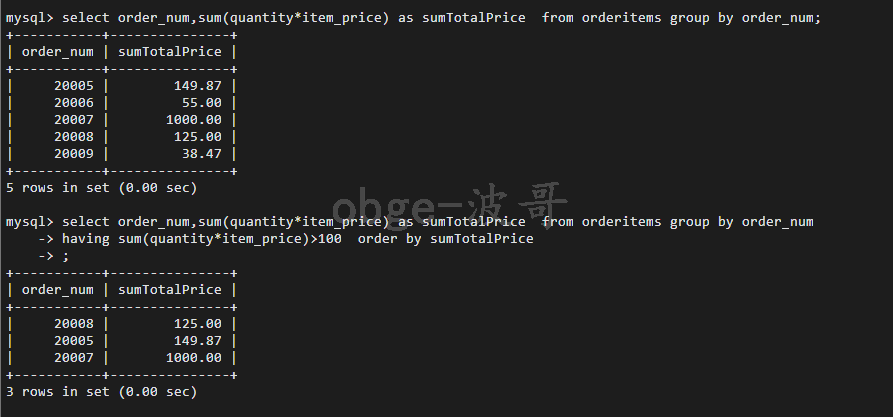
4、select 子句顺序
