处理流程:
- 变长特征分割成变长数组
- 变长数据填充成规则数组,组成n * m的矩阵 (keras.preprocessing.sequence.pad_sequences)
- 每一行数据进行embedding,结果可以按权重求平均、直接求平均、求最大值 得到 n*1结果矩阵
第3步求平均可以用tf.nn.lookup_embedding_sparse 来做,也可以在Embedding之后再加一层MaxPooling2D或者AVGPooling2D。
参考:
# Define the Keras model
model = Sequential()
model.add(Embedding(num_distinct_words, embedding_output_dims, input_length=max_sequence_length))
model.add(Dropout(0.50))
model.add(Conv1D(filters=32, kernel_size=2, padding='same', activation='relu'))
model.add(Dropout(0.50))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dropout(0.50))
model.add(Dense(1, activation='sigmoid'))
-
https://zhuanlan.zhihu.com/p/141443615
知乎的这个使用了lookup_embedding_sparse,自带根据权重求平均。 -
https://zhuanlan.zhihu.com/p/94212544
lookup_sparse 计算方法
处理变长特征代码实现参考
# -*- encoding: utf-8 -*-
import pandas as pd
from sklearn import preprocessing
from tensorflow import keras
from tensorflow.keras.models import Model, save_model
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Input
import tensorflow as tf
class VarLenColumnEmbedding(tf.keras.layers.Embedding):
"""
变长列做Embedding
"""
def __init__(self, pooling_strategy='max', dropout_rate=0., **kwargs):
if pooling_strategy not in ['mean', 'max']:
raise ValueError("Param strategy should is one of mean, max")
self.pooling_strategy = pooling_strategy
self.dropout_rate = dropout_rate # 支持dropout
super(VarLenColumnEmbedding, self).__init__(**kwargs)
def build(self, input_shape):
super(VarLenColumnEmbedding, self).build(input_shape) # Be sure to call this somewhere!
height = input_shape[1]
if self.pooling_strategy == "mean":
self._pooling_layer = tf.keras.layers.AveragePooling2D(pool_size=(height, 1))
else:
self._pooling_layer = tf.keras.layers.MaxPooling2D(pool_size=(height, 1))
if self.dropout_rate > 0:
self._dropout = tf.keras.layers.SpatialDropout1D(self.dropout_rate)
else:
self._dropout = None
self.built = True
def call(self, inputs):
# 1. do embedding
embedding_output = super(VarLenColumnEmbedding, self).call(inputs)
# 2. add dropout
if self._dropout is not None:
dropout_output = self._dropout(embedding_output)
else:
dropout_output = embedding_output
# 3. expand dim for polling
inputs_4d = tf.expand_dims(dropout_output, 3) # add channels dim
# 4. polling
tensor_pooling = self._pooling_layer(inputs_4d)
# 5. format output
return tf.squeeze(tensor_pooling, 3)
def compute_mask(self, inputs, mask):
return None
def get_config(self, ):
config = {'pooling_strategy': self.pooling_strategy}
base_config = super(VarLenColumnEmbedding, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
data = pd.read_csv("movielens_sample.txt")
series_genres = data.pop('genres').map(lambda _: _.split("|"))
gs_list = []
gs_max_len = 0
for gs in series_genres:
if len(gs) > gs_max_len:
gs_max_len = len(gs)
gs_list.extend(gs)
gs_list = list(set(gs_list))
gs_n_unique = len(gs_list)
lb = preprocessing.LabelEncoder()
lb.fit(gs_list)
y = data['rating'].values
data_geners = pad_sequences(series_genres.map(lambda _: lb.transform(_).tolist()), maxlen=gs_max_len, padding='post', )
feature_names = ['user_id', 'movie_id', 'timestamp', 'title', 'gender', 'age', 'occupation', 'zip']
for col in feature_names:
data[col] = preprocessing.LabelEncoder().fit_transform(data[col])
movie_id_uniques = len(set(data['movie_id'].tolist()))
input_movie_genres = Input(shape=(gs_max_len,), name='movie_genres_input')
layer_embedding_genres = VarLenColumnEmbedding(pooling_strategy='max', input_dim=gs_n_unique, output_dim=4)(input_movie_genres)
dense1 = keras.layers.Dense(512, activation='relu')(layer_embedding_genres)
output = keras.layers.Dense(6, activation='softmax')(dense1)
model = Model(inputs=[input_movie_genres], outputs=output)
model.run_eagerly = True
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
model.fit(data_geners, y, epochs=10)
网络结构:
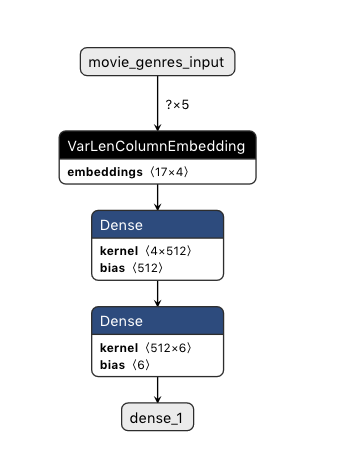
使用到的数据:
movielens_sample.zip