java并发编程实践
11.1ArrayBlockingQueue的使用
有关logback异步日志打印中的ArrayBlockingQueue的使用
1、异步日志打印模型概述
在高并发、高流量并且响应时间要求比较小的系统中同步打印日志在性能上已经满足不了了,这是以因为打印本身是需要写磁盘的,写磁盘操作会暂时阻塞调用打印日志的业务系统,这会造成调用线程的响应时间增加。
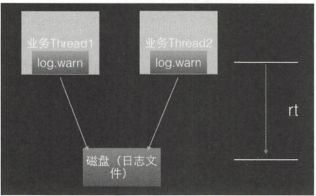 ----- 》》》
----- 》》》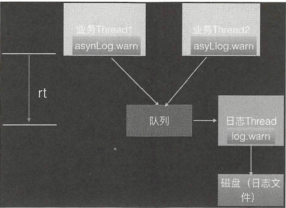
异步日志打印,是将打印日志任务放入一个队列后就返回,然后使用一个线程专门从队列中获取日志任务,并将其写入磁盘。
2、异步日志实现
一般情况下的同步日志logback.xml配置如下:(pattern会特殊定制)
<configuration> <appender name="FILE" class="ch.qos.logback.core.FileAppender"> <file>myapp.log</file> <encoder> <pattern>%logger{35} - %msg%n</pattern> </encoder> </appender> <root level="DEBUG"> <appender-ref ref="FILE" /> </root> </configuration>
而异步日志的logback.xml配置如下:多了个AsyncAppender配置,该类就是实现异步日志的关键类
<configuration> <appender name="FILE" class="ch.qos.logback.core.FileAppender"> <file>myapp.log</file> <encoder> <pattern>%logger{35} - %msg%n</pattern> </encoder> </appender> <appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender"> <appender-ref ref="FILE" /> </appender> <root level="DEBUG"> <appender-ref ref="ASYNC" /> </root> </configuration>
3、异步日志
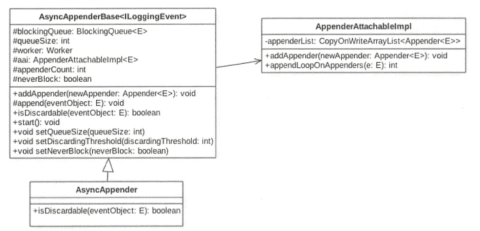
类图:
由类图可以看出,AsyncAppender继承AsyncAppenderBase类,实现AppenderAttachable接口,而关键实现异步方法的是AsyncAppenderBase类,其中blockingQueue是有界的阻塞队列,queueSize表示有界队列的元素个数,worker则是工作线程,也就是也不打印日志的消费者线程,aai则是一个appender的装饰器,里边存放的同步日志的appender,其中appenderCount记录aai里边附加的同步appender的个数(这个和配置文件相对应,一个异步的appender对应一个同步的appender),neverBlock用来指示当同步队列已满时是否阻塞打印日志线程,discardingThreshold是一个阈值,当日志队列里边的空闲元素个数小于该值时,新来的某些级别的日志就会直接被丢弃。
4、AsyncAppenderBase类
何时创建日志队列?
public void start() { if (isStarted()) return; if (appenderCount == 0) { addError("No attached appenders found."); return; } if (queueSize < 1) { addError("Invalid queue size [" + queueSize + "]"); return; } // 创建一个ArrayBlockingQueue阻塞队列,queueSize默认为256,创建阻塞队列的原因是:防止生产者过多,造成队列中元素过多,产生OOM异常 blockingQueue = new ArrayBlockingQueue<E>(queueSize); // 如果discardingThreshold未定义的话,默认为queueSize的1/5 if (discardingThreshold == UNDEFINED) discardingThreshold = queueSize / 5; addInfo("Setting discardingThreshold to " + discardingThreshold); // 将工作线程设置为守护线程,即当jvm停止时,即使队列中有未处理的元素,也不会在进行处理 worker.setDaemon(true); // 为线程设置name便于调试 worker.setName("AsyncAppender-Worker-" + getName()); // make sure this instance is marked as "started" before staring the worker Thread // 启动线程 super.start(); worker.start(); }
当队列已满时,是丢弃老的日志还是阻塞日志打印线程直到队列有空余元素时? 这个问题需要关注append方法
@Override protected void append(E eventObject) { // 判断队列中的元素数量是否小于discardingThreshold,如果小于的话,并且日志等级小于info的话,则直接丢弃这些日志任务 if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { return; } preprocess(eventObject); // 日志入队 put(eventObject); } private boolean isQueueBelowDiscardingThreshold() { return (blockingQueue.remainingCapacity() < discardingThreshold); } // 子类重写的方法 判断日志等级 protected boolean isDiscardable(ILoggingEvent event) { Level level = event.getLevel(); return level.toInt() <= Level.INFO_INT; } private void put(E eventObject) { // 判断是否阻塞(默认为false),则会调用阻塞队列的put方法 if (neverBlock) { blockingQueue.offer(eventObject); } else { putUninterruptibly(eventObject); } } // 可中断的阻塞put方法 private void putUninterruptibly(E eventObject) { boolean interrupted = false; try { while (true) { try { blockingQueue.put(eventObject); break; } catch (InterruptedException e) { interrupted = true; } } } finally { if (interrupted) { Thread.currentThread().interrupt(); } } } // ArrayBlockingQueue的put方法,当count==len时,调用await方法阻塞线程 public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); enqueue(e); } finally { lock.unlock(); } }
addAppender方法,有该方法可以看出,一个异步的appender只能绑定一个同步appender,这个appender会被放入AppenderAttachableImpl的appenderList列表里边。
public void addAppender(Appender<E> newAppender) { if (appenderCount == 0) { appenderCount++; addInfo("Attaching appender named [" + newAppender.getName() + "] to AsyncAppender."); aai.addAppender(newAppender); } else { addWarn("One and only one appender may be attached to AsyncAppender."); addWarn("Ignoring additional appender named [" + newAppender.getName() + "]"); } }
注意内部类Worker的run方法(消费者,将日志写入磁盘的线程方法)
class Worker extends Thread { public void run() { AsyncAppenderBase<E> parent = AsyncAppenderBase.this; AppenderAttachableImpl<E> aai = parent.aai; // loop while the parent is started 一直循环知道线程被中断 while (parent.isStarted()) { try {// 从阻塞队列中获取元素,交由给同步的appender将日志打印到磁盘 E e = parent.blockingQueue.take(); aai.appendLoopOnAppenders(e); } catch (InterruptedException ie) { break; } } addInfo("Worker thread will flush remaining events before exiting. "); //执行到这里说明该线程被中断,则把队列里边的剩余日志任务刷新到磁盘 for (E e : parent.blockingQueue) { aai.appendLoopOnAppenders(e); parent.blockingQueue.remove(e); } aai.detachAndStopAllAppenders(); } }
11.2Tomcat的NioEndPoint中的ConcurrentLinkedQueue
Tomcat的容器结构:

其中Connector是一个桥梁,他把server和Engine连接起来了,Connector的作用是接受客户端请求,然后把请求委托给Engine。在Connector中使用Endpoint来进行处理根据不同的处理方式可分为NioEndpoint、JIoEndpoint、AprEndpoint。
NioEndpoint中三大组件的关系:
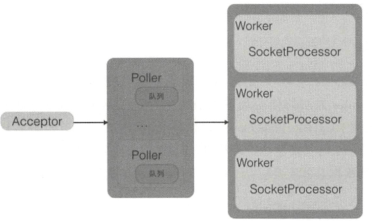
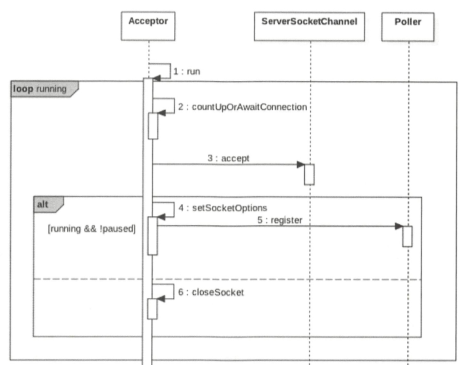
Acceptor作用:是套接字的接受线程,用来接受用户的请求,并把请求封装进Poller的队列,一个Connector中只有一个Acceptor。
Poller偶用:是套接字的处理线程,每一个Poller内部都有一个独有的队列,Poller线程则从自己的队列里边获取具体的事件任务,然后将其交给Worker进行处理,其中Poller的线程数和cpu个数有关。
Worker:是时间处理请求的线程,Worker只是组件的名字,真正做事情的是SocketProcessor。
由此可见,tomcat使用队列将接受请求和处理请求操作进行解耦,实现异步处理。
其实Tomcat中Endpoint中的每一个Poller里边都维护着一个ConcurrentLinkedQueue队列,用来缓存请求任务,其本身也是一个多生产者-单消费者模型。
1、Acceptor生产者
Acceptor线程的作用:接受客户端请求并将其放入Poller中的队列。
时序图(简单):
11.7创建线程和线程池时要指定与业务相关的名称
在日常开发过程中,当在一个应用中需要创建多个线程或者线程池时,最好给每个线程或者每个线程池根据业务类型设置具体的名称,以便在出现问题时方便定位。
1、创建多个线程案例
package com.nxz.blog.otherTest; public class TestThread0014 { public static void main(String[] args) { // 假设该线程操作保单模块 Thread t1 = new Thread(new Runnable() { @Override public void run() { System.out.println("操作保单"); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } // 手动抛异常 throw new NullPointerException(); } }); // 假设该模块是投保模块 Thread t2 = new Thread(new Runnable() { @Override public void run() { System.out.println("操作投保"); } }); t1.start(); t2.start(); } }
以上代码执行结果: 从异常信息中只能看出是Thread-0出现问题了,不能确定具体是哪一个模块出的问题,确认问题困难
操作保单 操作投保 Exception in thread "Thread-0" java.lang.NullPointerException at com.nxz.blog.otherTest.TestThread0014$1.run(TestThread0014.java:18) at java.lang.Thread.run(Thread.java:748)
看Thread构造函数:
public Thread(Runnable target) { // 当参数中没有提供name时,默认使用nextThreadNum生成编号来当做线程name init(null, target, "Thread-" + nextThreadNum(), 0); }
修改以上代码:即将创建线程时使用多个参数的构造函数:
public static void main(String[] args) { // 假设该线程操作保单模块 Thread t1 = new Thread(new Runnable() { @Override public void run() { System.out.println("操作保单"); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } // 手动抛异常 throw new NullPointerException(); } }, "保单模块"); // 假设该模块是投保模块 Thread t2 = new Thread(new Runnable() { @Override public void run() { System.out.println("操作投保"); } }, "投保模块"); t1.start(); t2.start(); }
执行结果: 很明显的看出是保单模块产生了问题
操作保单 操作投保 Exception in thread "保单模块" java.lang.NullPointerException at com.nxz.blog.otherTest.TestThread0014$1.run(TestThread0014.java:19) at java.lang.Thread.run(Thread.java:748)
2、创建线程池时也要指定线程池的名称
由线程池的构造函数,可以看出,默认的名称是类似“pool-1-thread-1”这样的名称
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), handler); } public static ThreadFactory defaultThreadFactory() { return new DefaultThreadFactory(); } DefaultThreadFactory() { SecurityManager s = System.getSecurityManager(); group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup(); namePrefix = "pool-" + poolNumber.getAndIncrement() + "-thread-"; }
因此使用ThreadPoolExecutor构建线程池的时候自定义ThreadFactory的名称(即仿照DefaultThreadFactory仿照一个CustomerThreadFactory,只需修改namePrefix即可):
package com.nxz.blog.otherTest; import java.util.concurrent.*; import java.util.concurrent.atomic.AtomicInteger; public class TestThread0015 { static class NamedThreadFactory implements ThreadFactory { private static final AtomicInteger poolNumber = new AtomicInteger(); private final ThreadGroup group; private final AtomicInteger threadNumber = new AtomicInteger(); private final String namePrefix; public NamedThreadFactory(String name) { SecurityManager s = System.getSecurityManager(); group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup(); if (name == null || name.isEmpty()) { name = "pool"; } namePrefix = name + "-" + poolNumber.getAndIncrement() + "-thread-"; } @Override public Thread newThread(Runnable r) { // 给线程也设置名称 Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0); if (t.isDaemon()) { t.setDaemon(false); } if (t.getPriority() != Thread.NORM_PRIORITY) { t.setPriority(Thread.NORM_PRIORITY); } return t; } } static ExecutorService executorServicePolicy = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES, new LinkedBlockingQueue<>(), new NamedThreadFactory("保单模块")); static ExecutorService executorServiceProposal = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES, new LinkedBlockingQueue<>(), new NamedThreadFactory("投保模块")); public static void main(String[] args) { executorServicePolicy.execute(new Runnable() { @Override public void run() { System.out.println("aaaa"); throw new NullPointerException(); } }); executorServiceProposal.execute(new Runnable() { @Override public void run() { System.out.println("bbbb"); // throw new NullPointerException(); } }); executorServicePolicy.shutdown(); executorServiceProposal.shutdown(); } }
以上代码执行结果:可以明显看出是保单模块线程池报错了
aaaa Exception in thread "保单模块-0-thread-0" java.lang.NullPointerException bbbb at com.nxz.blog.otherTest.TestThread0015$1.run(TestThread0015.java:51) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
11.8使用线程池的情况下当程序结束的时候记得调用shutdown方法关闭线程池
在日常开发过程中,为了复用线程,经常会用到线程池,然而使用完线程池后如果不调用shutdown方法关闭线程池,则会导致线程池资源得不到释放。
1、问题复现
package com.nxz.blog.otherTest; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class TestThread0013 { static void executeOne() { ExecutorService executorService = Executors.newSingleThreadExecutor(); executorService.execute(new Runnable() { @Override public void run() { System.out.println("execute One"); } });
//executorService.shutdoan(); } static void executeTwo() { ExecutorService executorService = Executors.newSingleThreadExecutor(); executorService.execute(new Runnable() { @Override public void run() { System.out.println("execute Two"); } });
//executorService.shutdoan(); } public static void main(String[] args) { System.out.println("main start"); executeOne(); executeTwo(); System.out.println("end"); } }
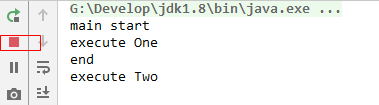
执行代码:当前主线程并没有结束,即资源没有释放; 如果将注释放开的话,则主线程会结束
 ----- 》》
----- 》》
那为什么不执行shutdown时,不释放资源?
在基础篇,曾经说过守护线程和用户现场,jvm退出的条件是当前不存在用户线程,而线程池默认创建的线程都是用户线程,而线程池中的线程会一直存在,所有jvm会一直运行。
11.9使用FutureTask时需要注意的事情
线程池使用FutureTask时如果把拒绝策略设置为DiscardPolicy或者DiscardOldestPolicy,并且在被拒绝任务的Future对象上调用了无参的get方法,那么调用线程会一直阻塞。
1、问题复现
package com.nxz.blog.otherTest; import java.util.concurrent.*; public class TestThread0012 { private final static ThreadPoolExecutor executorService = new ThreadPoolExecutor(1, 1, 1L, TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(1), new ThreadPoolExecutor.DiscardPolicy()); public static void main(String[] args) throws ExecutionException, InterruptedException { Future<?> futureOne = executorService.submit(new Runnable() { @Override public void run() { System.out.println("start runnable one"); try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } } }); Future<?> futureTwo = executorService.submit(new Runnable() { @Override public void run() { System.out.println("start runnable two"); } }); Future futureThree = null; try { futureThree = executorService.submit(new Runnable() { @Override public void run() { System.out.println("start runnable three"); } }); } catch (Exception e) { System.out.println(e.getLocalizedMessage()); } System.out.println("futureOne" + futureOne.get()); System.out.println("futureTwo" + futureTwo.get()); // 代码执行到该位置后不向下执行了,也就是futureThree.get方法阻塞了 System.out.println("futureThree" + futureThree.get()); System.out.println("end"); executorService.shutdown(); } }
那么为什么futureThree.get方法阻塞,需要看FutureTask中的get方法是怎样实现的(什么情况下会返回值,什么情况下会阻塞):
先分析上边代码的流程,线程池的大小为1,有界队列也是1,也就是说,当阻塞队列中已经有一个任务时,在submit任务时,就会执行拒绝策略,上边代码futureOne的任务里边有个睡眠(该作用就是使futureTwo进入阻塞队列,futureThree中的任务执行拒绝策略),那么看下submit的代码流程干了什么:
// 提交任务时,会现将runnable封装为一个Future对象 public Future<?> submit(Runnable task) { if (task == null) throw new NullPointerException(); RunnableFuture<Void> ftask = newTaskFor(task, null); execute(ftask); return ftask; } // newTaskFor方法,直接创建了一个FutureTask对象,而FutureTask对象的默认状态是NEW protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) { return new FutureTask<T>(runnable, value); } public FutureTask(Runnable runnable, V result) { this.callable = Executors.callable(runnable, result); this.state = NEW; // ensure visibility of callable }
从上边代码可以看出submit方法会将任务封装成一个FutureTask对象,而该对象默认的状态是NEW,那么继续看execute方法(在该方法里边会根据当前任务的个数来判断是否执行阻塞队列):
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } else if (!addWorker(command, false)) // 执行拒绝策略 reject(command); } // 因为创建线程池时,配置的是DIscardPolicy,因此看该对象中reject方法执行了什么操作 final void reject(Runnable command) { handler.rejectedExecution(command, this); } public static class DiscardPolicy implements RejectedExecutionHandler { public DiscardPolicy() { } // 可以看到rejfect什么也没有执行 public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { } }
从上边代码可以看出,当执行拒绝策略时,什么都没有执行,也就是说没有对当前任务做任何操作。(而下边这个future的get方法,能够返回值的时候,futureTask的状态必须大于COMPLETING,这和上边说的不符合,因此,当futureThree.get时,会阻塞(当拒绝策略设置为DIscardOldestPolicy时,同样有该问题))
从下边FutureTask中的get方法可以看出,当Future的状态(future是有状态的)值,小于COMPLETING时,就会阻塞,大于的话就会返回一个值
public V get() throws InterruptedException, ExecutionException { int s = state; if (s <= COMPLETING) s = awaitDone(false, 0L); return report(s); }
private volatile int state; private static final int NEW = 0; private static final int COMPLETING = 1; private static final int NORMAL = 2; private static final int EXCEPTIONAL = 3; private static final int CANCELLED = 4; private static final int INTERRUPTING = 5; private static final int INTERRUPTED = 6;
解决阻塞的方法:1、可以将拒绝策略设置为默认(AbortPolicy)2、尽量使用带超时时间的get方法,这样即使会阻塞,也会因为超时而返回。3、自定义拒绝策略,重写rejectedExecution方法,将futureTask的状态设置为大于COMPLETING即可。
11.10ThreadLocal使用不当导致的内存泄漏
内存泄漏Memory leak:是指程序中已经动态分配的堆内存,由于某种原因程序未释放或无法释放,造成系统内存浪费,导致程序运行速度减慢,甚至程序崩溃等后果。
在基础篇有介绍,ThreadLocal只是一个工具类,具体存放变量时线程的threadlocals变量。该变量是ThreadLocalMap类型的变量,如下图:
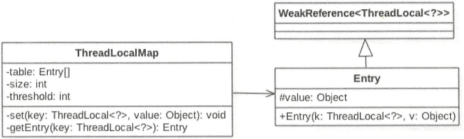
由图可知,ThreadLocalMap内部是一个Entry数组,Entry继承自WeakReference,Entry内部的value用来存放ThreadLocal的set方法传递的池,key则是ThreadLocal对象引用。
Entry构造:
key传递给WeakReference构造,也就是说ThreadLocalMap里边的key为ThreadLocal的弱引用,具体就是referent变量引用了ThreadLocal对象,value为具体调用ThreadLocal的set方法时传递的值
Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } public WeakReference(T referent) { super(referent); } Reference(T referent) { this(referent, null); } Reference(T referent, ReferenceQueue<? super T> queue) { this.referent = referent; this.queue = (queue == null) ? ReferenceQueue.NULL : queue; }
当一个线程调用ThreadLocal的set方法设置变量时,当前线程的ThreadLocalMap里边会存放一个记录,这个记录的key为ThreadLocal的弱引用,value为设置的值。如果线程一直没有调用remove方法,并且这个时候其他地方还有对ThreadLocal的引用,则当前线程的ThreadLocalMap变量里边存在对ThreadLocal变量的引用和对value对象的应用,他们是不会被释放的,这就会造成内存泄漏。另外,即使这个ThreadLocal变量没有其他强依赖,而当前线程还存在的,由于线程的ThreadLocalMap里边的key是弱引用,所以当前线程的ThreadLocal变量的弱引用会在GC的时候回收,但是对应的value不会回收,还是会造成内存泄漏。
虽然ThreadLocalMap提供的set、get、remove方法提供了在一些时机下对entry进行清理,但这是不及时的,也不是每次执行的,所以在一些情况下还是会有内存泄漏。
解决内ThreadLocal内存泄漏的方法:在ThreadLocal使用完毕后,及时调用remove方法进行清理工作。
案例:在线程池中使用ThreadLocal导致内存泄漏
package com.nxz.blog.otherTest; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; public class TestThread0010 { static class LocalVariable { //申请一块固定大小的内存 private Long[] a = new Long[1024 * 1024]; } static ThreadLocal<LocalVariable> localVariable = new ThreadLocal<>(); // 核心线程数和最大线程数都为5,超时时间1分钟 final static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES,new LinkedBlockingQueue<>()); public static void main(String[] args) throws InterruptedException { // 50个线程,每个线程都往ThreadLocal中放入一个固定大小的对象 for (int i = 0; i < 50; i++) { poolExecutor.execute(new Runnable() { @Override public void run() { localVariable.set(new LocalVariable()); System.out.println("user LocalVariable"); Thread thread1 = Thread.currentThread(); //localVariable.remove(); } }); Thread thread = Thread.currentThread(); Thread.sleep(1000); } System.out.println("pool executor over");
//poolExecutor.shutdown(); } }
运行代码,使用jconcle监控内存变化(我自己页测试来,但是显示效果没有书上的图好):
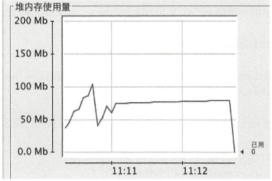
第二次运行时,放开remove方法的注释,继续看内存变化:
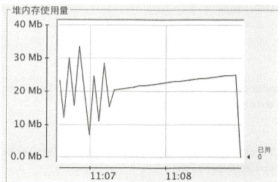
由两次运行的内存变化,可以看出,第一次运行时,当50个线程运行完毕后(此时主线程并没有结束,因为没有调用shutdown方法),结束时的内存为75MB左右,第二次运行时,结束内存为25MB左右,由此可以明显的看出,当没有调用remove方法是会造成内存泄漏。(PS:尚未理解的问题:这里为啥两次差距50MB,这个值是怎么出来的,还是没理顺??new LocalVariable对象大概占用1MB内存,相差50MB,相当于每一个Runnable任务,都没有经过回收,仍然保留在内存中。还有就是线程池中有5个线程循环利用,那么也就表示总共有5个ThreadLocalMap对象,而ThreadLocalMap的key为当前线程,那个set方法的时候,后序的set的value没有覆盖之前的吗?如果覆盖的话,那么最终两次运行应该相差5MB,或者是经过一个回收弱引用,那么也是10MB,50MB是怎样出来的??)
原因:
第一次运行代码的时候,没有调用remove方法,这就导致了当5个核心线程运行完毕后,线程的threadlocals里边的new LocalVariable()对象并没有释放。虽然线程执行完毕了,但是5个核心线程会一直存在,知道被JVM杀死。(这里需要注意的是:localVariable被定义为static变量,虽然在线程的ThreadLocalMap里边对localVariable进行了弱引用,但是localVariable并不会被回收),没有被回收是因为存在强引用:thread--》threadLocalMap--》entry--》value
第二次,由于及时的调用了remove方法,所以不会造成内存泄漏。