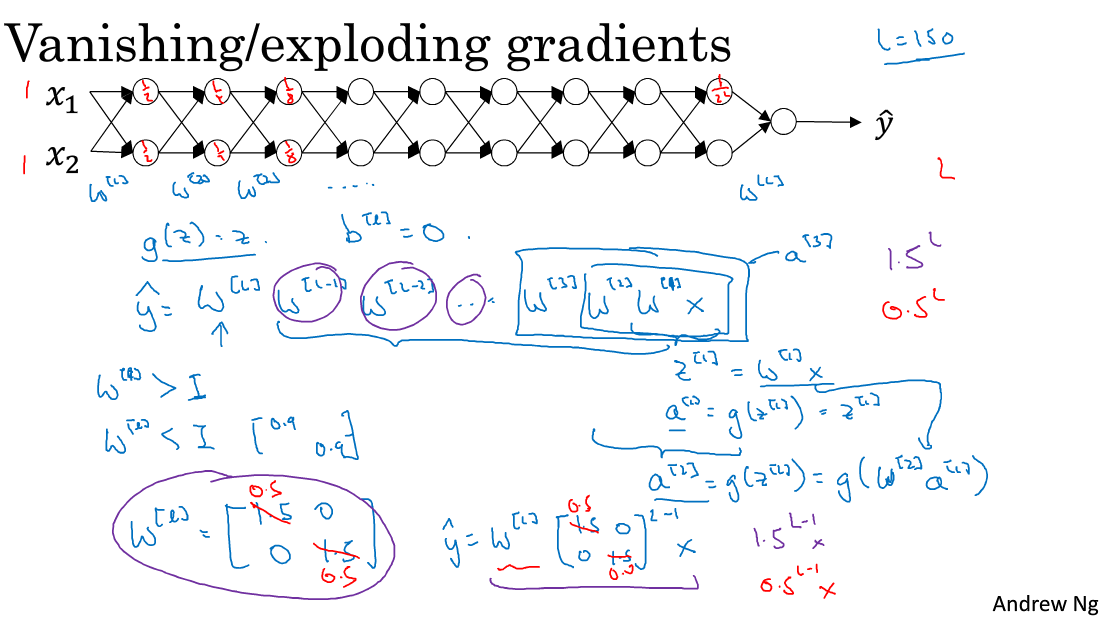
梯度消失与梯度爆炸
当训练神经网络时,导数或坡度有时会变得非常大或非常小,甚至以指数方式变小,这加大了训练的难度
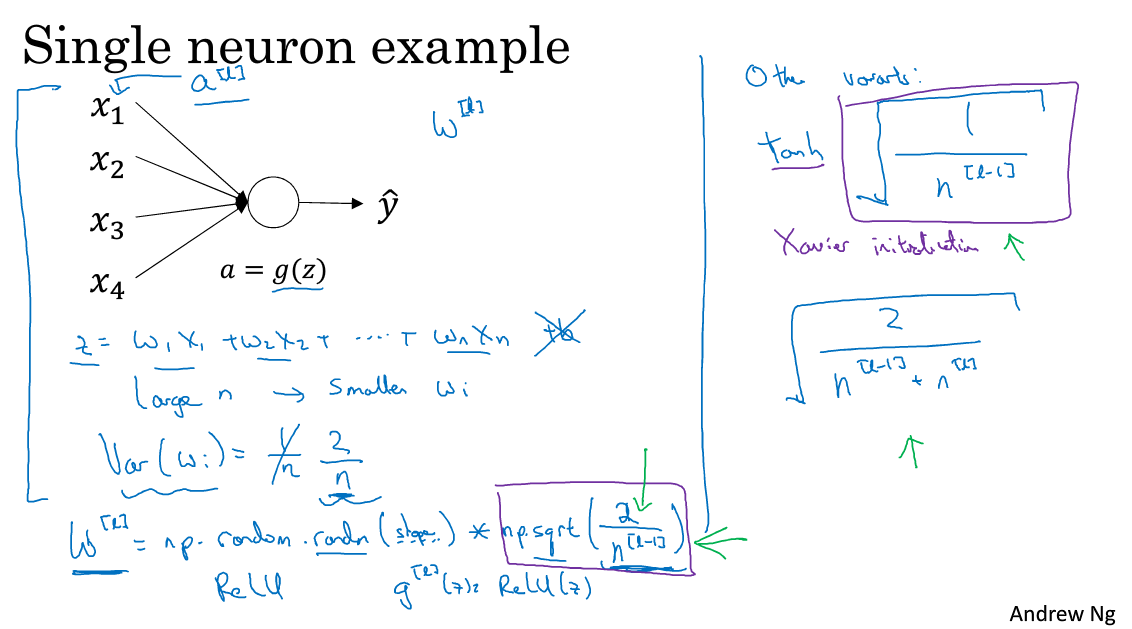
这里忽略了常数项b。为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小才好。这样能够保证z不会过大。
1.如果激活函数是tanh,一般选择下面的初始化方法
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(1/n[l-1])
2.如果激活函数是ReLU,权重w的初始化一般令其方差为:
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(2/n[l-1])
3.除此之外,Yoshua Bengio提出了另外一种初始化w的方法,令其方差为:
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(2/n[l-1]*n[l])
至于选择哪种初始化方法因人而异,可以根据不同的激活函数选择不同方法。