一、特征抽取
1.TF-IDF
“词频-逆向文件频率”(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。词语由t表示,文档由d表示,语料库由D表示。
- 词频TF(t,d)是词语t在文档d中出现的次数
- 文件频率DF(t,D)是包含词语的文档的个数
TF-IDF就是在数值化文档信息,衡量词语能提供多少信息以区分文档。其定义如下:
![]()
![]()
在Spark ML库中,TF-IDF被分成两部分:
- TF (+hashing)【转换器】:HashingTF 是一个Transformer,在文本处理中,接收词条的集合然后把这些集合转化成固定长度的特征向量。这个算法在哈希的同时会统计各个词条的词频。
- IDF【评估器】:IDF是一个Estimator,在一个数据集上应用它的fit()方法,产生一个IDFModel。 该IDFModel 接收特征向量(由HashingTF产生),然后计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重。
过程描述:
- 在下面的代码段中,我们以一组句子开始
- 首先使用分解器Tokenizer把句子划分为单个词语
- 对每一个句子(词袋),使用HashingTF将句子转换为特征向量
- 最后使用IDF重新调整特征向量(这种转换通常可以提高使用文本特征的性能)


(1)导入TF-IDF所需要的包:
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
开启RDD的隐式转换:
import spark.implicits._
(2)创建一个简单的DataFrame,每一个句子代表一个文档
scala> val sentenceData = spark.createDataFrame(Seq(
| (0, "I heard about Spark and I love Spark"),
| (0, "I wish Java could use case classes"),
| (1, "Logistic regression models are neat")
| )).toDF("label", "sentence")
sentenceData: org.apache.spark.sql.DataFrame = [label: int, sentence: string]
(3)得到文档集合后,即可用tokenizer对句子进行分词

scala> val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
tokenizer: org.apache.spark.ml.feature.Tokenizer = tok_494411a37f99
scala> val wordsData = tokenizer.transform(sentenceData)
wordsData: org.apache.spark.sql.DataFrame = [label: int, sentence: string, words: array<string>]
scala> wordsData.show(false)
+-----+------------------------------------+---------------------------------------------+
|label|sentence |words |
+-----+------------------------------------+---------------------------------------------+
|0 |I heard about Spark and I love Spark|[i, heard, about, spark, and, i, love, spark]|
|0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes] |
|1 |Logistic regression models are neat |[logistic, regression, models, are, neat] |
+-----+------------------------------------+---------------------------------------------+
(4)得到分词后的文档序列后,即可使用HashingTF的transform()方法把句子哈希成特征向量,这里设置哈希表的桶数为2000。

scala> val hashingTF = new HashingTF().
| setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(2000)
hashingTF: org.apache.spark.ml.feature.HashingTF = hashingTF_2591ec73cea0
scala> val featurizedData = hashingTF.transform(wordsData)
featurizedData: org.apache.spark.sql.DataFrame = [label: int, sentence: string,
words: array<string>, rawFeatures: vector]
scala> featurizedData.select("rawFeatures").show(false)
+---------------------------------------------------------------------+
|rawFeatures |
+---------------------------------------------------------------------+
|(2000,[240,333,1105,1329,1357,1777],[1.0,1.0,2.0,2.0,1.0,1.0]) |
|(2000,[213,342,489,495,1329,1809,1967],[1.0,1.0,1.0,1.0,1.0,1.0,1.0])|
|(2000,[286,695,1138,1193,1604],[1.0,1.0,1.0,1.0,1.0]) |
+---------------------------------------------------------------------+
(5)使用IDF来对单纯的词频特征向量进行修正,使其更能体现不同词汇对文本的区别能力
scala> val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
idf: org.apache.spark.ml.feature.IDF = idf_7fcc9063de6f
scala> val idfModel = idf.fit(featurizedData)
idfModel: org.apache.spark.ml.feature.IDFModel = idf_7fcc9063de6f
- IDF是一个Estimator,调用fit()方法并将词频向量传入,即产生一个IDFModel
- IDFModel是一个Transformer,调用它的transform()方法,即可得到每一个单词对应的TF-IDF度量值
scala> val rescaledData = idfModel.transform(featurizedData)
rescaledData: org.apache.spark.sql.DataFrame = [label: int, sentence: string, words: array<string>, rawFeatures: vector, features: vector]
scala> rescaledData.select("features", "label").take(3).foreach(println)
[(2000,[240,333,1105,1329,1357,1777],[0.6931471805599453,0.6931471805599453,1.3862943611198906,0.5753641449035617,0.6931471805599453,0.6931471805599453]),0]
[(2000,[213,342,489,495,1329,1809,1967],[0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.28768207245178085,0.6931471805599453,0.6931471805599453]),0]
[(2000,[286,695,1138,1193,1604],[0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453]),1]
2.Word2Vec
- Word2Vec是一种著名的词嵌入(Word Embedding)方法,它可以计算每个单词在其给定语料库环境下的分布式词向量。
- 词向量表示可以在一定程度上刻画每个单词的语义。
- 如果词的语义相近,它们的词向量在向量空间中也相互接近。
- Word2vec是一个Estimator,它采用一系列代表文档的词语来训练word2vecmodel。
- 该模型将每个词语映射到一个固定大小的向量。
- word2vecmodel使用文档中每个词语的平均数来将文档转换为向量,然后这个向量可以作为预测的特征,来计算文档相似度计算等等。
任务描述:一组文档,其中一个词语序列代表一个文档。对于每一个文档,我们将其转换为一个特征向量。此特征向量可以被传递到一个学习算法。
(1)首先导入Word2Vec所需要的包,并创建三个词语序列,每个代表一个文档:
scala> import org.apache.spark.ml.feature.Word2Vec
scala> val documentDF = spark.createDataFrame(Seq(
| "Hi I heard about Spark".split(" "),
| "I wish Java could use case classes".split(" "),
| "Logistic regression models are neat".split(" ")
| ).map(Tuple1.apply)).toDF("text")
documentDF: org.apache.spark.sql.DataFrame = [text: array<string>]
(2)新建一个Word2Vec,显然,它是一个Estimator,设置相应的超参数,这里设置特征向量的维度为3
scala> val word2Vec = new Word2Vec().
| setInputCol("text").
| setOutputCol("result").
| setVectorSize(3).
| setMinCount(0)
word2Vec: org.apache.spark.ml.feature.Word2Vec = w2v_e2d5128ba199
(3)读入训练数据,用fit()方法生成一个Word2VecModel
scala> val model = word2Vec.fit(documentDF) model: org.apache.spark.ml.feature.Word2VecModel = w2v_e2d5128ba199
(4)利用Word2VecModel把文档转变成特征向量
scala> val result = model.transform(documentDF)
result: org.apache.spark.sql.DataFrame = [text: array<string>, result: vector]
scala> result.select("result").take(3).foreach(println)
[[0.018490654602646827,-0.016248732805252075,0.04528368394821883]]
[[0.05958533100783825,0.023424440695505054,-0.027310076036623544]]
[[-0.011055880039930344,0.020988055132329465,0.042608972638845444]]
3.CountVectorizer
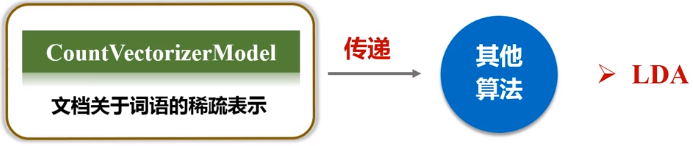

- CountVectorizer旨在通过计数来将一个文档转换为向量。当不存在先验字典时,Countvectorizer作为Estimator提取词汇进行训练,并生成一个CountVectorizerModel用于存储相应的词汇向量空间。
- 该模型产生文档关于词语的稀疏表示,其表示可以传递给其他算法,例如LDA。
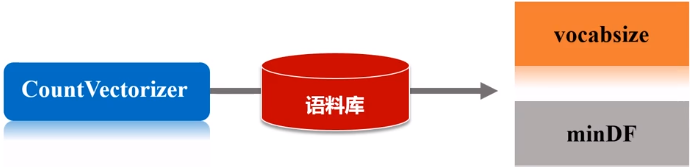
- 在CountVectorizerModel的训练过程中,CountVectorizer将根据语料库中的词频排序从高到低进行选择,词汇表的最大含量由vocabsize超参数来指定,超参数minDF,则指定词汇表中的词语至少要在多少个不同文档中出现。
(1)首先导入CountVectorizer所需要的包:
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
(2)假设有如下的DataFrame,其包含id和words两列,可以看成是一个包含两个文档的迷你语料库。
scala> val df = spark.createDataFrame(Seq(
| (0, Array("a", "b", "c")),
| (1, Array("a", "b", "b", "c", "a"))
| )).toDF("id", "words")
df: org.apache.spark.sql.DataFrame = [id: int, words: array<string>]
(3)通过CountVectorizer设定超参数,训练一个CountVectorizerModel,这里设定词汇表的最大量为3,设定词汇表中的词至少要在2个文档中出现过,以过滤那些偶然出现的词汇。
scala> val cvModel: CountVectorizerModel = new CountVectorizer().
| setInputCol("words").
| setOutputCol("features").
| setVocabSize(3).
| setMinDF(2).
| fit(df)
cvModel: org.apache.spark.ml.feature.CountVectorizerModel = cntVec_237a080886a2
(4)在训练结束后,可以通过CountVectorizerModel的vocabulary成员获得到模型的词汇表
scala> cvModel.vocabulary res7: Array[String] = Array(b, a, c)
从打印结果我们可以看到,词汇表中有“a”,“b”,“c”三个词,且这三个词都在2个文档中出现过(前文设定了minDF为2)
(5)使用这一模型对DataFrame进行变换,可以得到文档的向量化表示:
scala> cvModel.transform(df).show(false) +---+---------------+-------------------------+ |id |words |features | +---+---------------+-------------------------+ |0 |[a, b, c] |(3,[0,1,2],[1.0,1.0,1.0])| |1 |[a, b, b, c, a]|(3,[0,1,2],[2.0,2.0,1.0])| +---+---------------+-------------------------+
和其他Transformer不同,CountVectorizerModel可以通过指定一个先验词汇表来直接生成,如以下例子,直接指定词汇表的成员是“a”,“b”,“c”三个词:
scala> val cvm = new CountVectorizerModel(Array("a", "b", "c")).
| setInputCol("words").
| setOutputCol("features")
cvm: org.apache.spark.ml.feature.CountVectorizerModel = cntVecModel_c6a17c2befee
scala> cvm.transform(df).select("features").foreach { println }
[(3,[0,1,2],[1.0,1.0,1.0])]
[(3,[0,1,2],[2.0,2.0,1.0])]
二、特征变换
1.标签和索引的转化
在机器学习处理过程中,为了方便相关算法的实现,经常需要把标签数据(一般是字符串)转化成整数索引,或是在计算结束后将整数索引还原为相应的标签。
Spark ML包中提供了几个相关的转换器,例如:StringIndexer、IndexToString、OneHotEncoder、VectorIndexer,它们提供了十分方便的特征转换功能,这些转换器类都位于org.apache.spark.ml.feature包下。
值得注意的是,用于特征转换的转换器和其他的机器学习算法一样,也属于ML Pipeline模型的一部分,可以用来构成机器学习流水线,以StringIndexer为例,其存储着进行标签数值化过程的相关 超参数,是一个Estimator,对其调用fit(..)方法即可生成相应的模型StringIndexerModel类,很显然,它存储了用于DataFrame进行相关处理的 参数,是一个Transformer(其他转换器也是同一原理)。
1.1 StringIndexer
StringIndexer转换器可以把一列类别型的特征(或标签)进行编码,使其数值化,索引的范围从0开始,该过程可以使得相应的特征索引化,使得某些无法接受类别型特征的算法可以使用,并提高诸如决策树等机器学习算法的效率。
索引构建的顺序为标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为0号如果输入的是数值型的,我们会把它转化成字符型,然后再对其进行编码。
(1)首先引入必要的包,并创建一个简单的DataFrame,它只包含一个id列和一个标签列category
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel}
scala> val df1 = spark.createDataFrame(Seq(
| (0, "a"),
| (1, "b"),
| (2, "c"),
| (3, "a"),
| (4, "a"),
| (5, "c"))).toDF("id", "category")
df1: org.apache.spark.sql.DataFrame = [id: int, category: string]
(2)随后,我们创建一个StringIndexer对象,设定输入输出列名,其余参数采用默认值,并对这个DataFrame进行训练,产生StringIndexerModel对象:
scala> val indexer = new StringIndexer().
| setInputCol("category").
| setOutputCol("categoryIndex")
indexer: org.apache.spark.ml.feature.StringIndexer = strIdx_95a0a5afdb8b
scala> val model = indexer.fit(df1)
model: org.apache.spark.ml.feature.StringIndexerModel = strIdx_4fa3ca8a82ea
(3)随后即可利用该对象对DataFrame进行转换操作,可以看到,StringIndexerModel依次按照出现频率的高低,把字符标签进行了排序,即出现最多的“a”被编号成0,“c”为1,出现最少的“b”为0
scala> val indexed1 = model.transform(df1) indexed1: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double] scala> indexed1.show() +---+--------+-------------+ | id|category|categoryIndex| +---+--------+-------------+ | 0| a| 0.0| | 1| b| 2.0| | 2| c| 1.0| | 3| a| 0.0| | 4| a| 0.0| | 5| c| 1.0| +---+--------+-------------+
1.2 IndexToString
与StringIndexer相对应,IndexToString的作用是把标签索引的一列重新映射回原有的字符型标签。
其主要使用场景一般都是和StringIndexer配合,先用StringIndexer将标签转化成标签索引,进行模型训练,然后在预测标签的时候再把标签索引转化成原有的字符标签。当然,你也可以另外定义其他的标签
(1)首先,和StringIndexer的实验相同,我们用StringIndexer读取数据集中的“category”列,把字符型标签转化成标签索引,然后输出到“categoryIndex”列上,构建出新的DataFrame
scala> val df = spark.createDataFrame(Seq(
| (0, "a"),
| (1, "b"),
| (2, "c"),
| (3, "a"),
| (4, "a"),
| (5, "c")
| )).toDF("id", "category")
df: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val model = new StringIndexer().
| setInputCol("category").
| setOutputCol("categoryIndex").
| fit(df)
indexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_00fde0fe64d0
scala> val indexed = indexer.transform(df)
indexed: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double]
(2)随后,创建IndexToString对象,读取“categoryIndex”上的标签索引,获得原有数据集的字符型标签,然后再输出到“originalCategory”列上。最后,通过输出“originalCategory”列,可以看到数据集中原有的字符标签
scala> val converter = new IndexToString().
| setInputCol("categoryIndex").
| setOutputCol("originalCategory")
converter: org.apache.spark.ml.feature.IndexToString = idxToStr_b95208a0e7ac
scala> val converted = converter.transform(indexed)
converted: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double, originalCategory: string]
scala> converted.select("id", "originalCategory").show()
+---+----------------+
| id|originalCategory|
+---+----------------+
| 0| a|
| 1| b|
| 2| c|
| 3| a|
| 4| a|
| 5| c|
+---+----------------+
1.3 OneHotEncoder
- 独热编码(One-Hot Encoding) 是指把一列类别性特征(或称名词性特征,nominal/categorical features)映射成一系列的二元连续特征的过程,原有的类别性特征有几种可能取值,这一特征就会被映射成几个二元连续特征,每一个特征代表一种取值,若该样本表现出该特征,则取1,否则取0。
- One-Hot编码适合一些期望类别特征为连续特征的算法,比如说逻辑斯蒂回归等。
(1)首先创建一个DataFrame,其包含一列类别性特征,需要注意的是,在使用OneHotEncoder进行转换前,DataFrame需要先使用StringIndexer将原始标签数值化:
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
scala> val df = spark.createDataFrame(Seq(
| (0, "a"),
| (1, "b"),
| (2, "c"),
| (3, "a"),
| (4, "a"),
| (5, "c"),
| (6, "d"),
| (7, "d"),
| (8, "d"),
| (9, "d"),
| (10, "e"),
| (11, "e"),
| (12, "e"),
| (13, "e"),
| (14, "e")
| )).toDF("id", "category")
df: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val indexer = new StringIndexer().
| setInputCol("category").
| setOutputCol("categoryIndex").
| fit(df)
indexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_b315cf21d22d
scala> val indexed = indexer.transform(df)
indexed: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double]
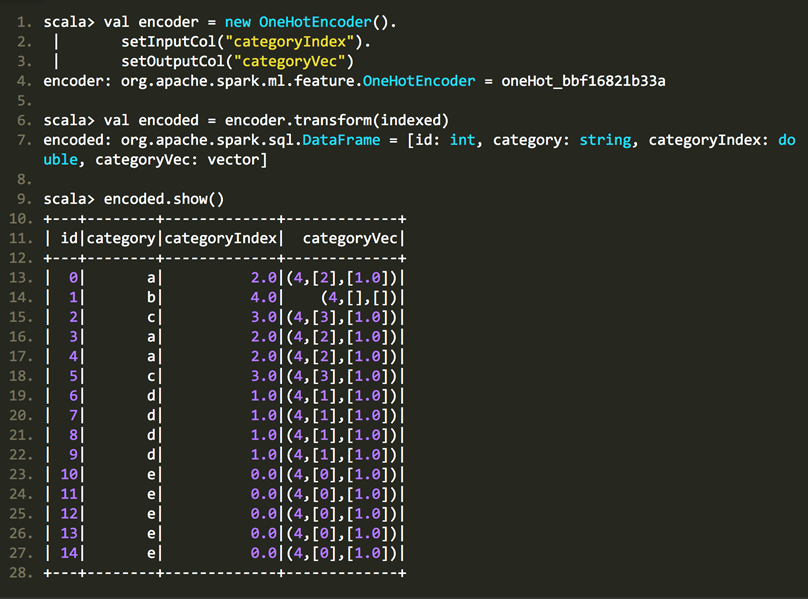
(2)随后,我们创建OneHotEncoder对象对处理后的DataFrame进行编码,可以看见,编码后的二进制特征呈稀疏向量形式,与StringIndexer编码的顺序相同,需注意的是最后一个Category("b")被编码为全0向量,若希望"b"也占有一个二进制特征,则可在创建OneHotEncoder时指定setDropLast(false)
scala> val encoder = new OneHotEncoder().
| setInputCol("categoryIndex").
| setOutputCol("categoryVec")
encoder: org.apache.spark.ml.feature.OneHotEncoder = oneHot_bbf16821b33a
scala> val encoded = encoder.transform(indexed)
encoded: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double, categoryVec: vector]
1.4 VectorIndexer
之前介绍的StringIndexer是针对单个类别型特征进行转换,倘若所有特征都已经被组织在一个向量中,又想对其中某些单个分量进行处理时,Spark ML提供了VectorIndexer类来解决向量数据集中的类别性特征转换。
通过为其提供maxCategories超参数,它可以自动识别哪些特征是类别型的,并且将原始值转换为类别索引。它基于不同特征值的数量来识别哪些特征需要被类别化,那些取值可能性最多不超过maxCategories的特征需要会被认为是类别型的。
在下面的例子中,我们读入一个数据集,然后使用VectorIndexer训练出模型,来决定哪些特征需要被作为类别特征,将类别特征转换为索引,这里设置maxCategories为2,即只有种类小于2的特征才被认为是类别型特征,否则被认为是连续型特征:
import org.apache.spark.ml.feature.VectorIndexer
import org.apache.spark.ml.linalg.{Vector, Vectors}
scala> val data = Seq(
| Vectors.dense(-1.0, 1.0, 1.0),
| Vectors.dense(-1.0, 3.0, 1.0),
| Vectors.dense(0.0, 5.0, 1.0))
data: Seq[org.apache.spark.ml.linalg.Vector] = List([-1.0,1.0,1.0], [-1.0,3.0,1.0], [0.0,5.0,1.0])
scala> val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df: org.apache.spark.sql.DataFrame = [features: vector]
scala> val indexer = new VectorIndexer().
| setInputCol("features").
| setOutputCol("indexed").
| setMaxCategories(2)
indexer: org.apache.spark.ml.feature.VectorIndexer = vecIdx_abee81bafba8
scala> val indexerModel = indexer.fit(df)
indexerModel: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_abee81bafba8
可以通过VectorIndexerModel的categoryMaps成员来获得被转换的特征及其映射,这里可以看到共有两个特征被转换,分别是0号和2号。
scala> val categoricalFeatures: Set[Int] = indexerModel.categoryMaps.keys.toSet
categoricalFeatures: Set[Int] = Set(0, 2)
scala> println(s"Chose ${categoricalFeatures.size} categorical features: " + categoricalFeatures.mkString(", "))
Chose 2 categorical features: 0, 2
可以看到,0号特征只有-1,0两种取值,分别被映射成0,1,而2号特征只有1种取值,被映射成0
scala> val indexed = indexerModel.transform(df) indexed: org.apache.spark.sql.DataFrame = [features: vector, indexed: vector] scala> indexed.show() +--------------+-------------+ | features| indexed| +--------------+-------------+ |[-1.0,1.0,1.0]|[1.0,1.0,0.0]| |[-1.0,3.0,1.0]|[1.0,3.0,0.0]| | [0.0,5.0,1.0]|[0.0,5.0,0.0]| +--------------+-------------+
2.卡方选择器
特征选择(Feature Selection)指的是在特征向量中选择出那些“优秀”的特征,组成新的、更“精简”的特征向量的过程。它在高维数据分析中十分常用,可以剔除掉“冗余”和“无关”的特征,提升学习器的性能。
特征选择方法和分类方法一样,也主要分为有监督(Supervised)和无监督(Unsupervised)两种。
卡方选择则是统计学上常用的一种有监督特征选择方法,它通过对特征和真实标签之间进行卡方检验,来判断该特征和真实标签的关联程度,进而确定是否对其进行选择
和ML库中的大多数学习方法一样,ML中的卡方选择也是以estimator+transformer的形式出现的,其主要由ChiSqSelector和ChiSqSelectorModel两个类来实现:
(1)在进行实验前,首先进行环境的设置。引入卡方选择器所需要使用的类:
import org.apache.spark.ml.feature.{ChiSqSelector, ChiSqSelectorModel}
import org.apache.spark.ml.linalg.Vectors
(2)随后,创造实验数据,这是一个具有三个样本,四个特征维度的数据集,标签有1,0两种,我们将在此数据集上进行卡方选择:
scala> val df = spark.createDataFrame(Seq(
| (1, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1),
| (2, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0),
| (3, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0)
| )).toDF("id", "features", "label")
df: org.apache.spark.sql.DataFrame = [id: int, features: vector ... 1 more field]
scala> df.show()
+---+------------------+-----+
| id| features|label|
+---+------------------+-----+
| 1|[0.0,0.0,18.0,1.0]| 1|
| 2|[0.0,1.0,12.0,0.0]| 0|
| 3|[1.0,0.0,15.0,0.1]| 0|
+---+------------------+-----+
(3)现在,用卡方选择进行特征选择器的训练,为了观察地更明显,我们设置只选择和标签关联性最强的一个特征(可以通过setNumTopFeatures(..)方法进行设置):
scala> val selector = new ChiSqSelector().
| setNumTopFeatures(1).
| setFeaturesCol("features").
| setLabelCol("label").
| setOutputCol("selected-feature")
selector: org.apache.spark.ml.feature.ChiSqSelector = chiSqSelector_688a180ccb71
scala> val selector_model = selector.fit(df)
selector_model: org.apache.spark.ml.feature.ChiSqSelectorModel = chiSqSelector_688a180ccb71
(4)用训练出的模型对原数据集进行处理,可以看见,第三列特征被选出作为最有用的特征列:
scala> val selector_model = selector.fit(df) selector_model: org.apache.spark.ml.feature.ChiSqSelectorModel = chiSqSelector_688a180ccb71 scala> val result = selector_model.transform(df) result: org.apache.spark.sql.DataFrame = [id: int, features: vector ... 2 more fields] scala> result.show(false) +---+------------------+-----+----------------+ |id |features |label|selected-feature| +---+------------------+-----+----------------+ |1 |[0.0,0.0,18.0,1.0]|1.0 |[18.0] | |2 |[0.0,1.0,12.0,0.0]|0.0 |[12.0] | |3 |[1.0,0.0,15.0,0.1]|0.0 |[15.0] | +---+------------------+-----+----------------+