一、RDD编程基础

1.创建

spark采用textFile()方法来从文件系统中加载数据创建RDD,该方法把文件的URL作为参数,这个URL可以是:
- 本地文件系统的地址
- 分布式文件系统HDFS的地址
- 从云端加载数据,比如亚马逊的云端存储S3
(1)从本地文件系统中加载数据创建RDD

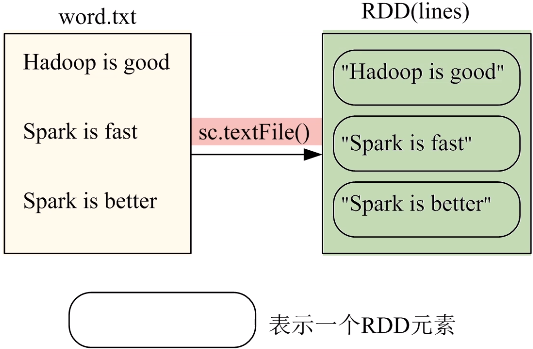
(2)从分布式文件系统HDFS中加载数据

上面三条等价的前提是当前登录linux系统的用户名必须是Hadoop用户,这样当执行括号里给的文本文件名称word.txt时,系统默认去当前登录Ubuntu系统的用户在HDFS当中对应的用户主目录中寻找
/user/hadoop是hdfs中的用户主目录
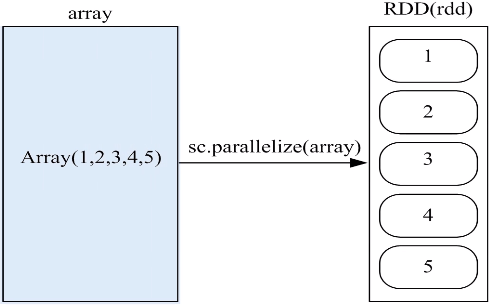
(3)通过并行集合(数组)创建RDD
可以调用SparkContext对象的Parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
a.通过数组创建RDD

b.通过列表创建RDD

2.基本操作
(1)转换操作
- 对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用
- 转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作

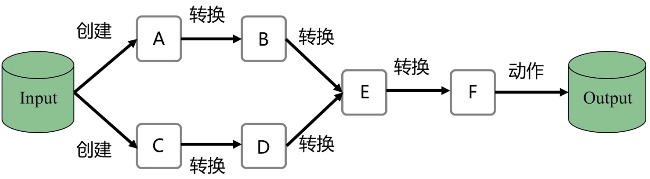
RDD常用转换操作:
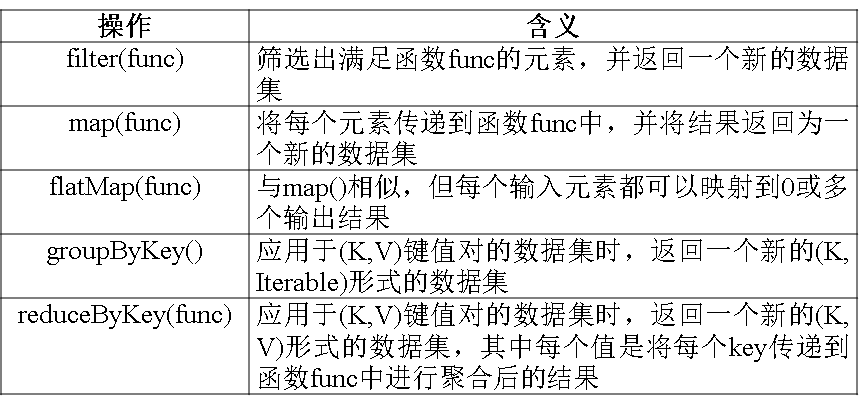
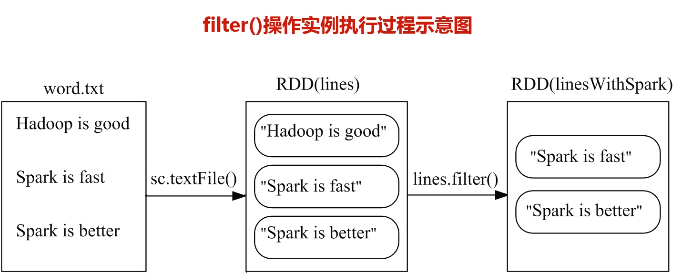
a.filter(func)
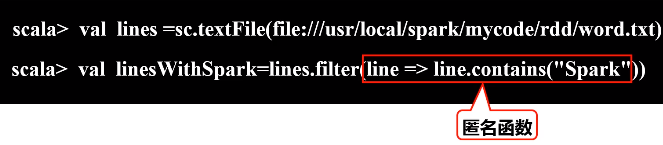
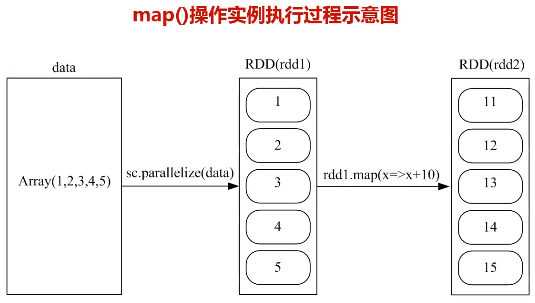
b.map(func)操作



c.flatMap(func)操作

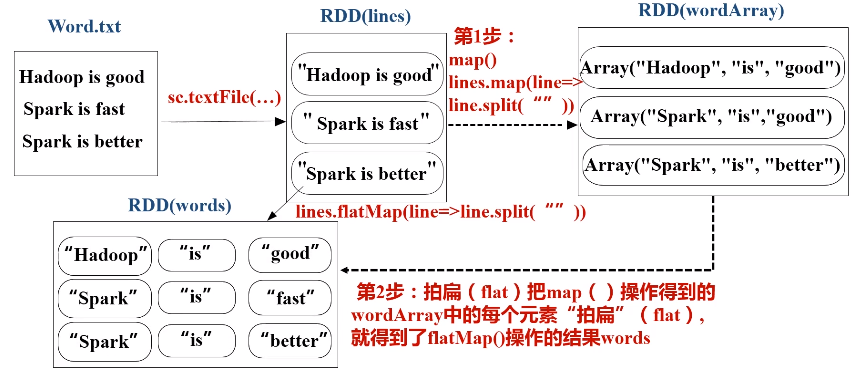
d.groupByKey(func)操作
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集

e.reduceByKey(func)操作
reduceByKey(func)应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果

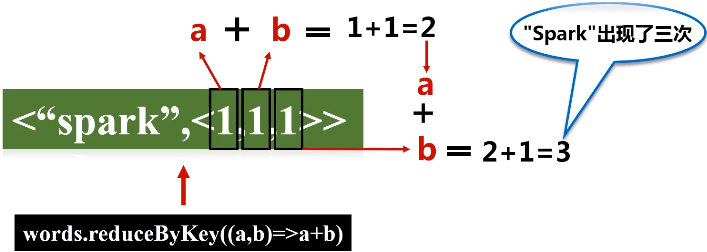
reduceByKey和groupByKey的区别:reduceByKey不仅会进行一个分组,还会把value list再根据传入的函数再做操作
(2)行动操作

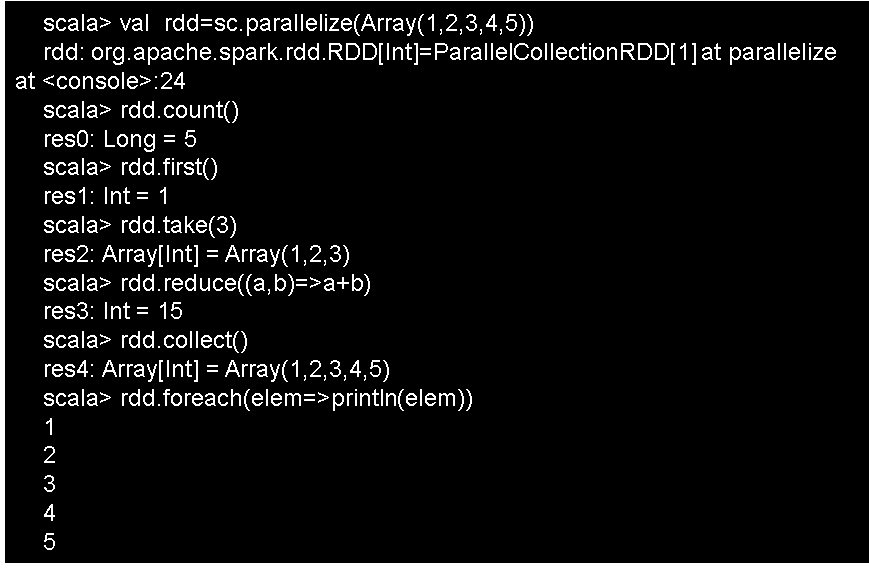
a.count()
返回数据集中的元素个数。
b.collect()
把在不同电脑上生成结果都收集回来,可以在发起程序的终端上显示出来。

c.first()
返回数据集中的第一个元素
d.take(n)
返回数据集中的前n个元素,并且以数组的形式
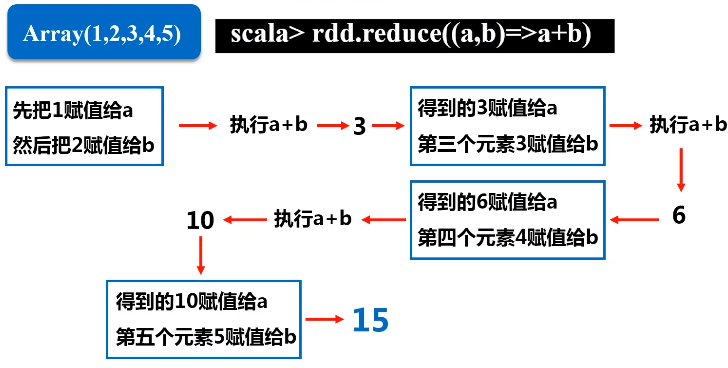
e.reduce(func)
func是一个高阶函数
f.foreach(func):遍历
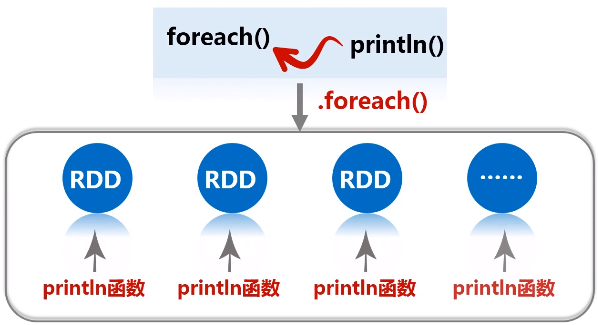
(3)惰性机制
惰性机制:整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。

3.持久化
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据

rdd.count()第一次动作类型,得到的结果先把它存起来,这样下面再去执行rdd.collect()又遇到第二次动作类型操作的时候,就不用再从头到尾去算了,只需要用刚才存起来的值就可以了。但是如果计算结果不需要重复用的话,就不要随便去用持久化,会很耗内存。

job的由来:每次遇到一个动作类型操作,都会生成一个job。
持久化的方式:
- 可以通过持久化(缓存)机制避免这种重复计算的开销
- 可以使用persist()方法对一个RDD标记为持久化
- 之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
- 持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
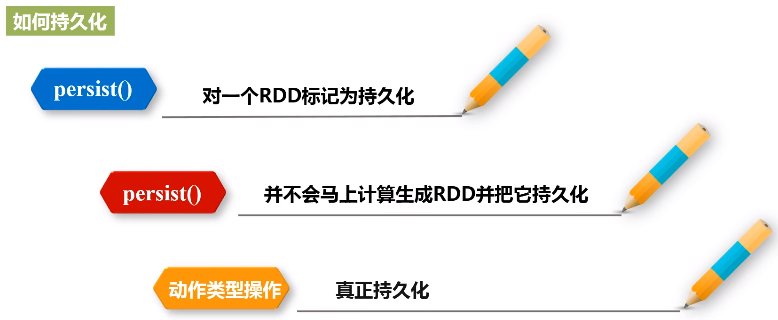
- persist()的圆括号中包含的是持久化级别参数:
- persist(MEMORY_ONLY):标记为持久化,并不会真正缓存rdd,将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容 ,RDD.cache()等价于RDD.persist(MEMORY_ONLY)
- persist(MEMORY_AND_DISK)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上
- 一般而言,使用cache()方法时,会调用persist(MEMORY_ONLY)
- 可以使用unpersist()方法手动地把持久化的RDD从缓存中移除
针对上面的实例,增加持久化语句以后的执行过程如下:
4.分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上
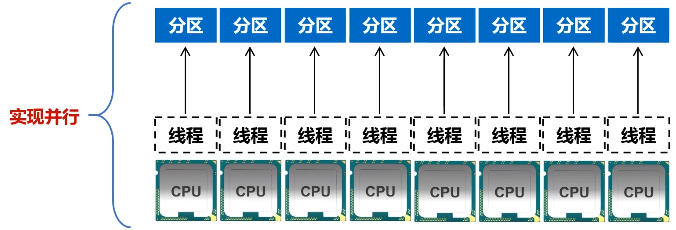
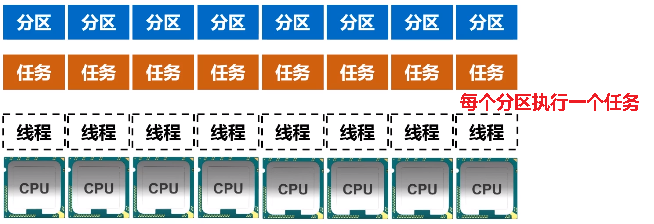
(1)分区的作用
a.增加并行度
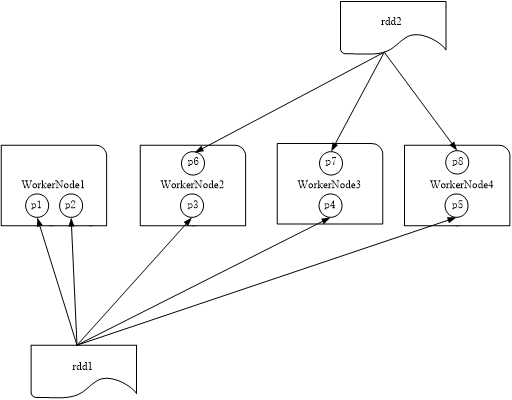
图 RDD分区被保存到不同节点上

b.减少通信开销
u1,u2,...是放在不同机器上的,右边也是放在不同机器上的,会在网络上大量机器之间来回传输。
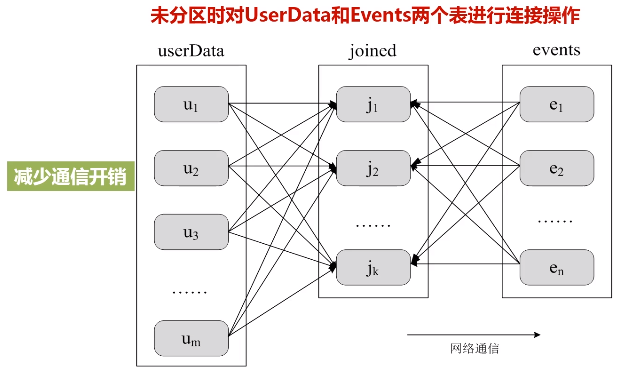
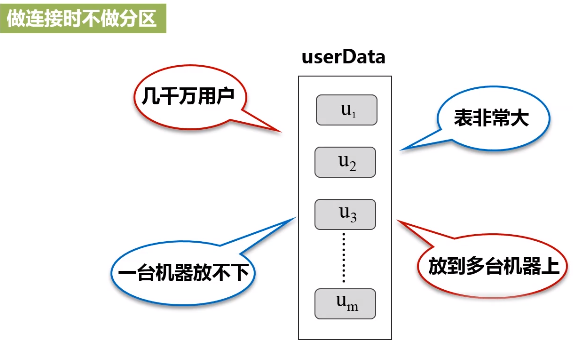
图:未分区时对UserData和Events两个表进行连接操作
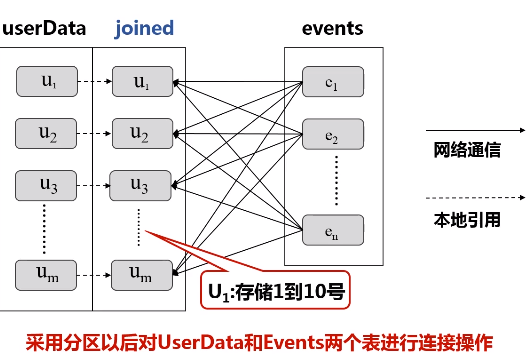
图:采用分区以后对UserData和Events两个表进行连接操作
userData表:u1存储1到10号,u2存储11到20号,...
events表:挑出1到10号的扔给u1,11到20的扔给u2,...
(2)分区原则
RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
- *本地模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N
- *Apache Mesos:默认的分区数为8
- *Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值
分区个数=集群中CPU核心数目
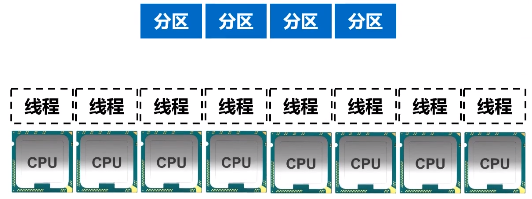
如果分区个数和CPU核数不接近,比如说有4个分区,8个CPU,那意味着4个CPU的线程是浪费掉的,因为只有4个分区,顶多可以启动4个线程。
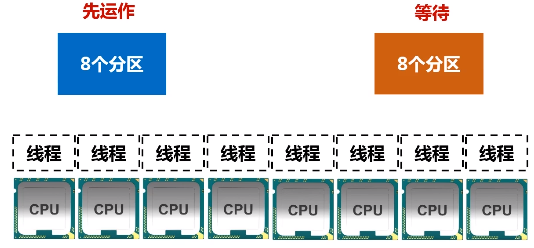
如果有16个分区,8个线程,那只能有8个分区去运作,剩下8个分区得等待。
(3)设置分区的个数
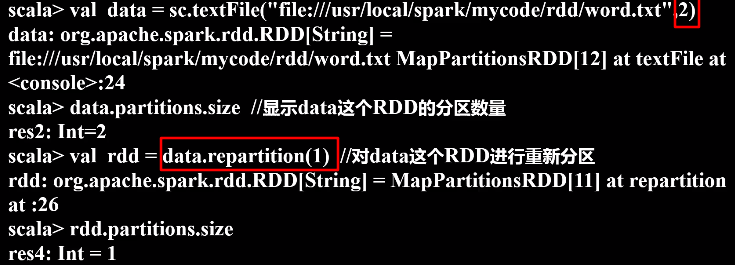
a.创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下: sc.textFile(path, partitionNum) 其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
语法格式:
sc.textFile(path,partitionNum) // partitionNum表示指定分区个数

b.使用repartition方法重新设置分区个数
(4)自定义分区方法
Spark提供了自带的HashPartitioner(哈希分区)与RangePartitioner(区域分区),能够满足大多数应用场景的需求。与此同时,Spark也支持自定义分区方式,即通过提供一个自定义的Partitioner对象来控制RDD的分区方式,从而利用领域知识进一步减少通信开销。
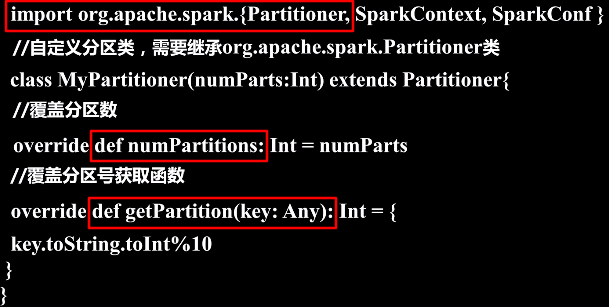
要实现自定义分区,需要定义一个类,这个自定义类需要继承org.apache.spark.Partitioner类,并实现下面三个方法:
- numPartitions: Int 返回创建出来的分区数
- getPartition(key: Any): Int 返回给定键的分区编号(0到numPartitions-1)
- equals():Java判断相等性的标准方法

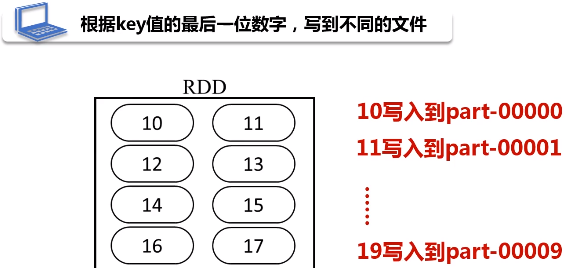
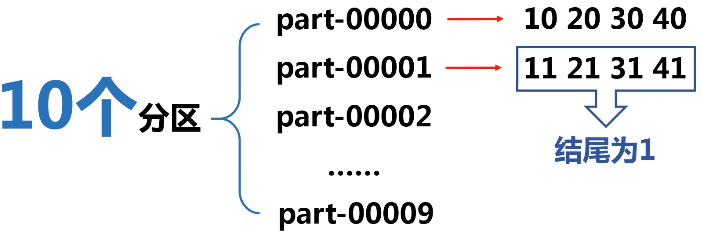
实例:根据key值的最后一位数字,写到不同的文件,例如:
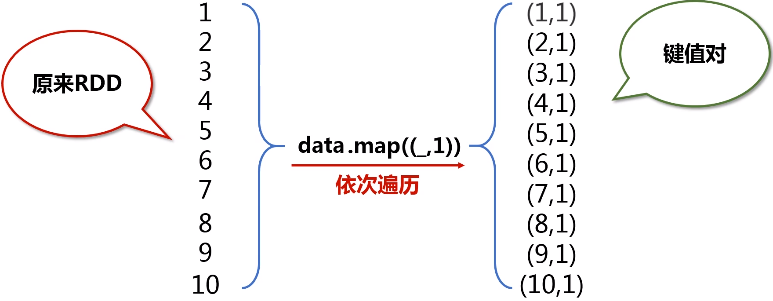
用单例对象定义入口函数,凡是写在单例对象中的都是静态的方法。

map(_._n)表示任意元组tuple对象,后面的数字n表示取第几个数.(n>=1的整数)
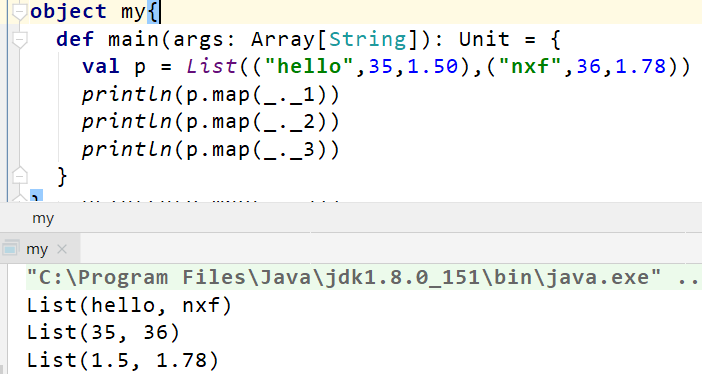

注意:partitioner自定义分区类只支持RDD为键值对的形式
5.基本实例---词频统计
假设有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数):

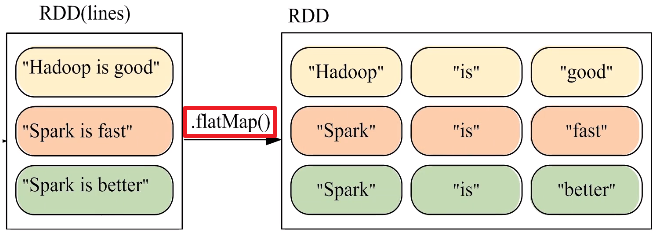
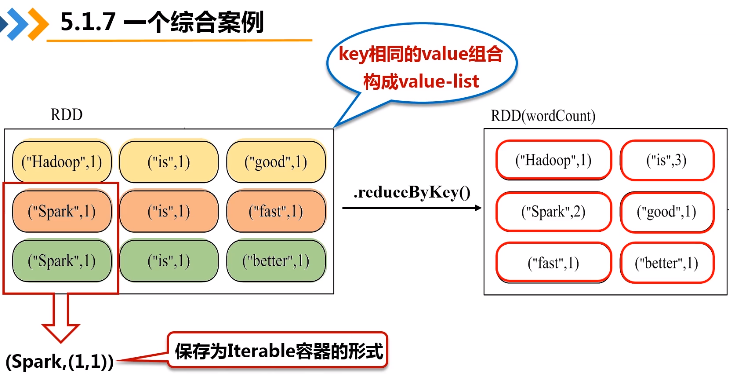

在实际应用中,单词文件可能非常大,会被保存到分布式文件系统HDFS中,Spark和Hadoop会统一部署在一个集群上。spark的wordnode和hdfs的datanode部署在一起的(让数据更靠近计算) 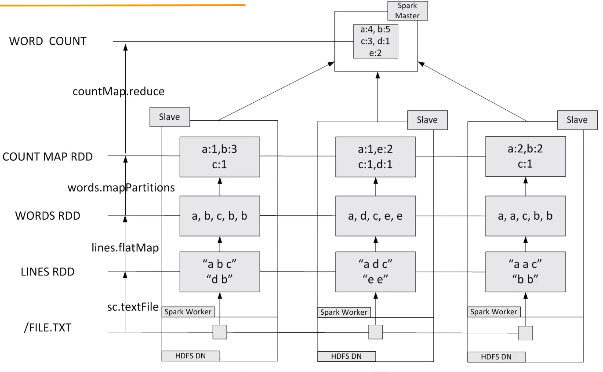
先在不同的机器上分别并行执行词频统计,得到统计结果后,再到spark master节点上进行汇总,最终得到总的结果。