tf.nn.embedding_lookup(
params,
ids,
partition_strategy='mod',
name=None,
validate_indices=True,
max_norm=None
)
功能:选取一个张量里面索引对应的行的向量
TensorFlow链接:https://tensorflow.google.cn/api_docs/python/tf/nn/embedding_lookup?hl=en
参数:
- params:张量或数组;
- id:对应的索引
- partition_strategy:partition_strategy是用于当len(params) > 1,params的元素分割不能整分的话,则前(max_id + 1) % len(params)多分一个id.
- 当partition_strategy = 'mod'的时候,13个ids划分为5个分区:[[0, 5, 10], [1, 6, 11], [2, 7, 12], [3, 8], [4, 9]],也就是是按照数据列进行映射,然后再进行look_up操作。默认是mod
- 当partition_strategy = 'div'的时候,13个ids划分为5个分区:[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10], [11, 12]],也就是是按照数据先后进行排序标序,然后再进行look_up操作。
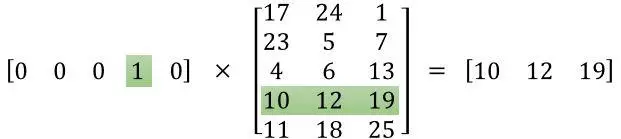 (图来自https://www.jianshu.com/p/abea0d9d2436)
(图来自https://www.jianshu.com/p/abea0d9d2436)
举例:
import numpy as np
A = tf.convert_to_tensor(np.array([[[1],[2]],[[3],[4]],[[5],[6]]]))
B = tf.nn.embedding_lookup(A, [[0,1],[1,0],[0,0]])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print('A',sess.run(A))
print('A shape',A.shape)
print('B',sess.run(B))
print('B shape',B.shape)
结果:
A [[[1] [2]] [[3] [4]] [[5] [6]]] A shape (3, 2, 1) B [[[[1] [2]] [[3] [4]]] [[[3] [4]] [[1] [2]]] [[[1] [2]] [[1] [2]]]] B shape (3, 2, 2, 1)
参考文献: