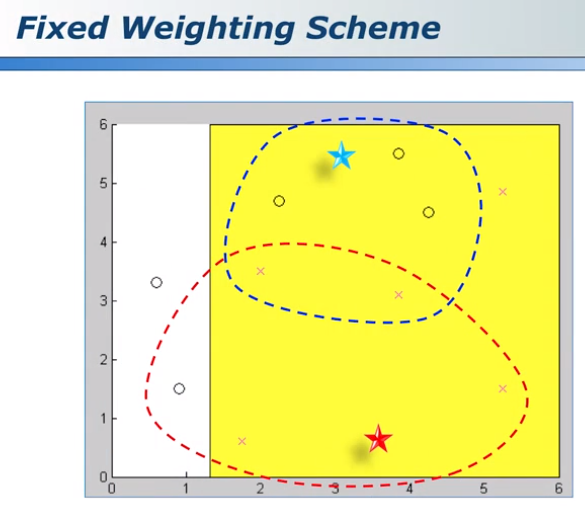
在adaboost当中,样本的权重alpha是固定的,蓝色五角星所在的圈中3个○分错了,红色五角星所在的圈中4个×和1个○都分对了,很容易让人想到,这个模型,对于红色位置的判断更加可信。
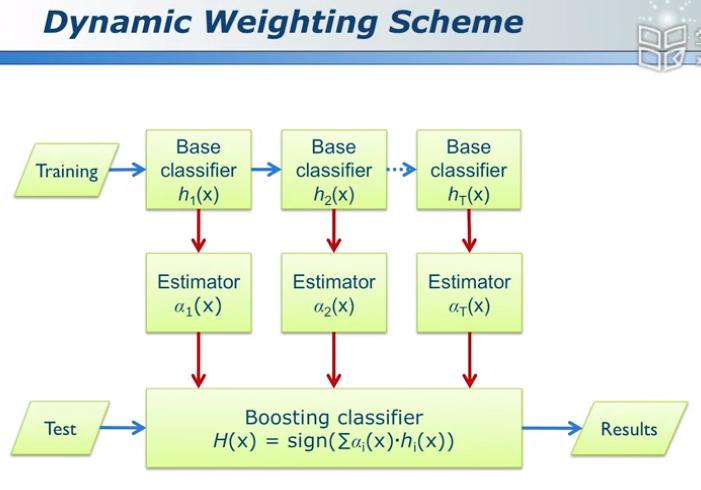
动态权重,每个x都会有特定的权重,不同的分类器对于不同的样本的权重是不一样的

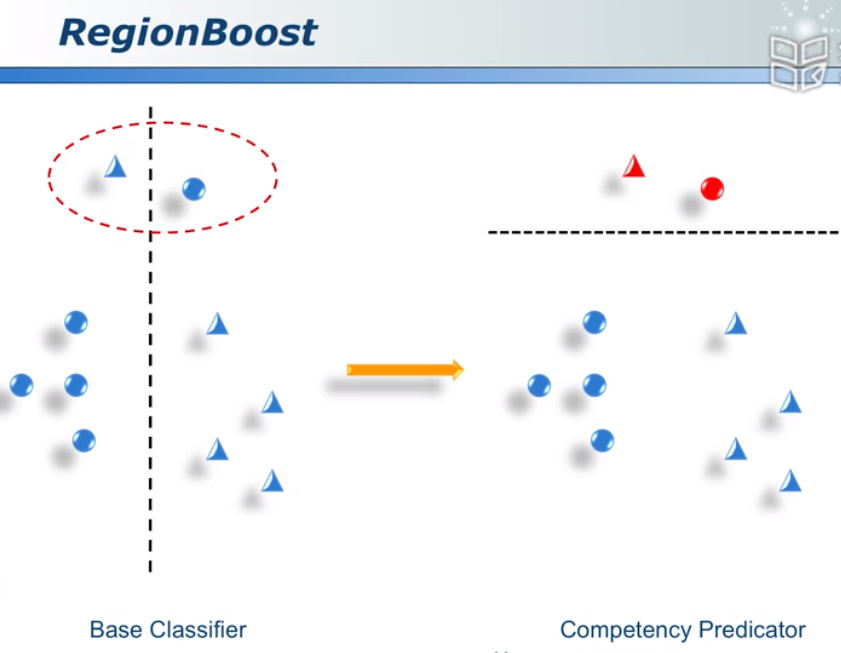
base classifer:分○和△
competency predictor:分对和分错的样本
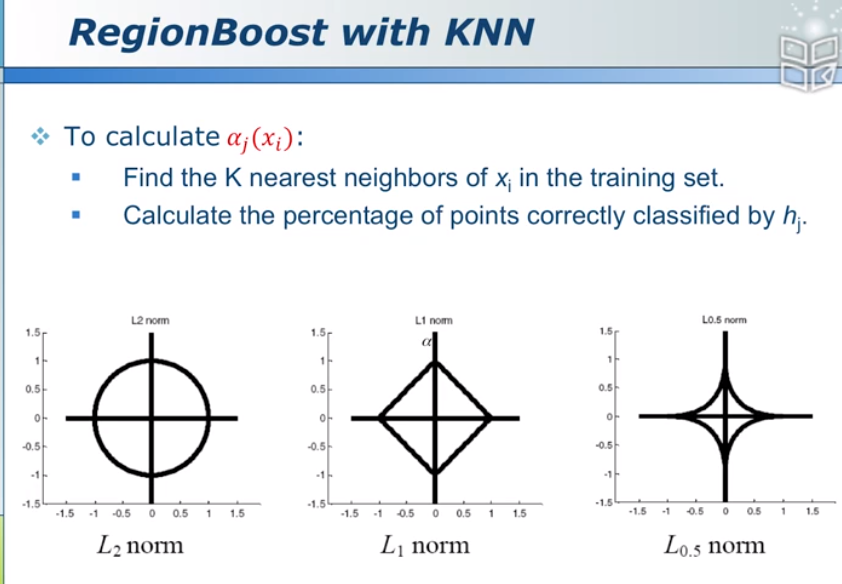
将分错的归到一处,利用KNN的方法,比如要测试一个样本xi和5个最近的训练样本,计算这个模型在5个样本上面分的对还是错,如果那5个分的都对,那这个模型比较靠谱。
但欧氏距离在高维空间
L1:曼哈顿距离
L0.5:分式距离

如上图所示,adaboost收敛性要好于Regionboost

但regionboost的测试误差要低于adaboost
论文出处:

参考文献: