近来接到一个小项目,读取目标文件中每一行url,并逐个请求url,拿到想要的数据。
#-*- coding:utf-8 -*- class IpUrlManager(object): def __init__(self): self.newipurls = set() #self.oldipurls = set() def Is_has_ipurl(self): return len(self.newipurls)!=0 def get_ipurl(self): if len(self.newipurls)!=0: new_ipurl = self.newipurls.pop() #self.oldipurls.add(new_ipurl) return new_ipurl else: return None def download_ipurl(self,destpath): try: f = open(destpath,'r') iter_f = iter(f) lines = 0 for ipurl in iter_f: lines = lines + 1 self.newipurls.add((ipurl.rstrip(' ')) #log记录读取了多少行IP url #print lines finally: if f: f.close()
咋一眼看code写的没问题,每一个url 增加进newipurls set集合中。但是请求的过程中,requests.get后,会出现如下错误:
raise InvalidSchema("No connection adapters were found for '%s'" % url)

后来发现每次都是第一行的url请求失败。然后打印print 请求的url。也没发现异常。然后从根源上去找,好吧,print打印newipurls set集合看看。
果然,问题就在这里。

奇怪,为什么这个URL前面为默认加上了xefxbbxbf 这几个字符呢?
上网看了一些资料,原来在python的file对象的readline以及readlines程序中,针对一些UTF-8编码的文件,开头会加入BOM来表明编码方式。
何为BOM?
所谓BOM,全称是Byte Order Mark,它是一个Unicode字符,通常出现在文本的开头,用来标识字节序(Big/Little Endian),除此以外还可以标识编码(UTF-8/16/32)。
其实如果大家有UltraEdit tool可以发现,在另存为文件的时候,可以保存为UTF-8 和UTF-8 无BOM的文件。
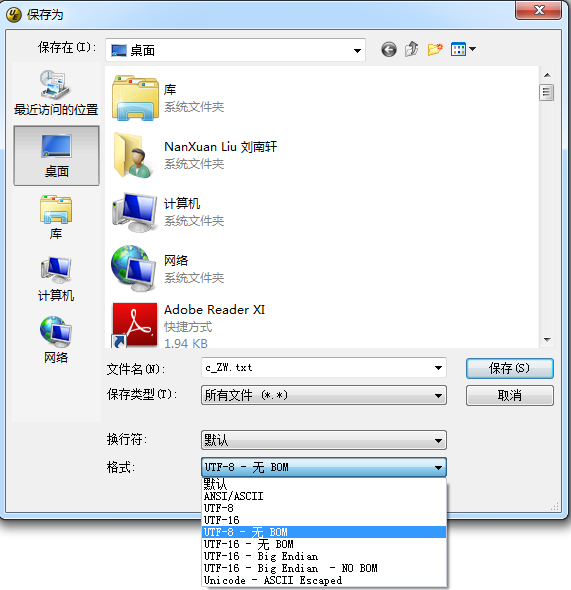
如果将文件另存在UTF-8的格式,则文件的开头默认会增加三个字节xefxbbxbf。
怎么检测该文件是否为UTF-8 带BOM的呢?
import codecs def download_ipurl(self,destpath): try: f = open(destpath,'r') iter_f = iter(f) lines = 0 for ipurl in iter_f: lines = lines + 1 if ipurl[0:3] == codecs.BOM_UTF8: self.newipurls.add((ipurl.rstrip(' ')).lstrip('xefxbbxbf')) #print self.newipurls #log记录读取了多少行IP url #print lines finally: if f: f.close()
引用codecs模块,来判断前三个字节是否为BOM_UTF8。如果是,则剔除xefxbbxbf字节。
其实大家可以通过其他方式剔除BOM字节,我写的比较粗糙。