github_addr:https://github.com/Norni/proxy_pool
1、代理池的概述
1.1什么是代理池
-
代理池是由代理IP组成的池子,它可以提供多个稳定可用的代理IP
1.2为什么要实现代理池
-
应付ip反爬
-
免费代理是不稳定的,提高使用效率
-
部分收费代理也不稳定,提高使用效率
1.3代理池开发环境
-
平台:window+linux
-
开发语言:python
-
开发工具:pycharm
-
技术栈:
-
requests、urllib:发送请求,解析url和获取页面数据
-
pymongo:把提取到的代理IP存储到MongoDB数据库中和从MongoDB数据库中读取代理IP,给爬虫使用
-
Flask:用于提供web服务
-
2、代理池的设计
2.1代理池的工作流程
-
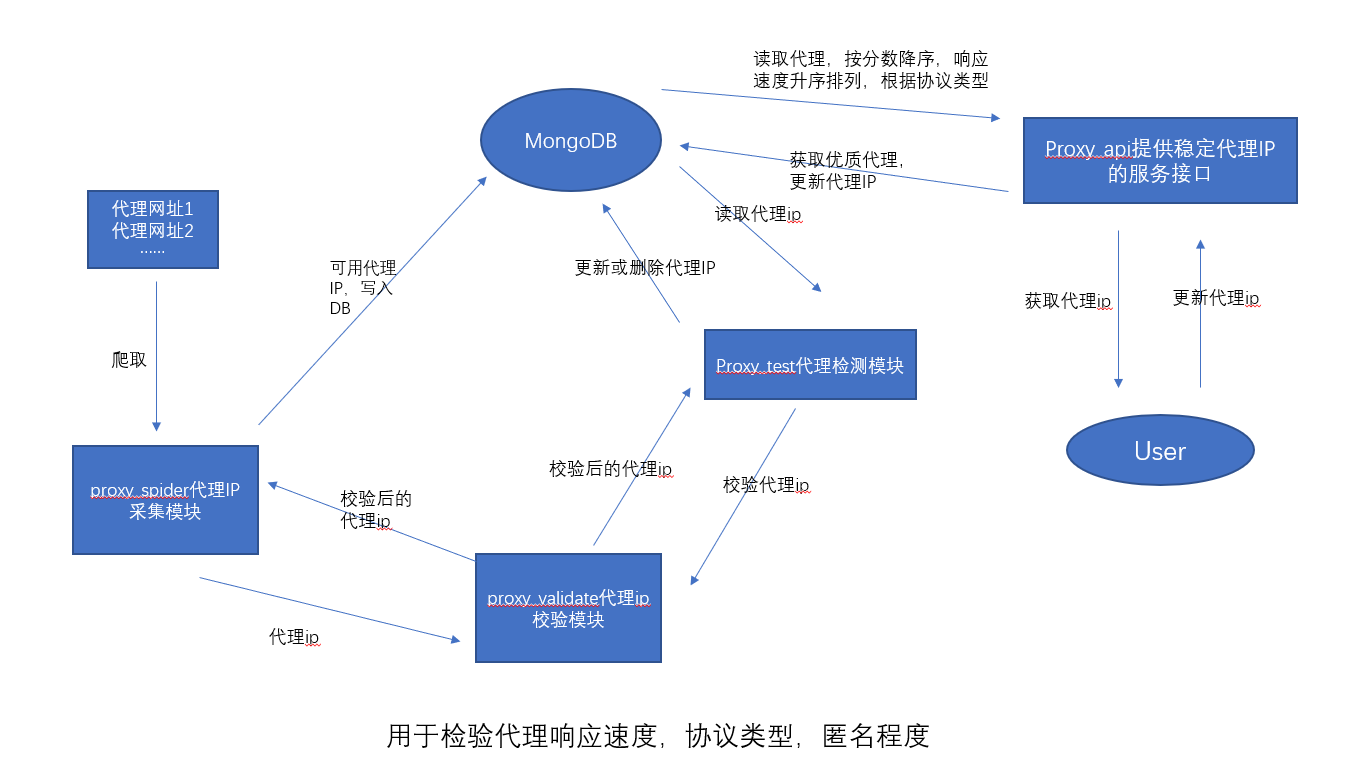
代理池的工作流程
-
代理池工作流程文字描述
-
代理IP采集模块 ->采集代理IP -> 检测代理IP -> 如果不可用,直接过滤掉,如果可用,指定默认分数 -> 存入数据库中
-
代理IP检测模块 -> 从数据库中获取所有代理IP -> 检测代理IP -> 如果代理IP不可用,就把分数-1,如果分数为0则会将其从数据库中删除,如果代理ip可用,恢复默认分数值,更新到数据库
-
代理API模块 -> 从数据库中提取高可用的代理IP给爬虫使用
-
2.2代理池的模块及其作用
-
代理池分为五大核心模块
-
爬虫模块:采集代理IP
-
从代理IP网站上采集代理IP
-
进行校验(获取代理响应速度,协议类型,匿名类型)
-
把可用代理ip存储到数据库中
-
-
代理ip的校验模块:获取指定代理的响应速度,支持的协议以及匿名程度
-
原因:网站上所标注的响应速度,协议类型和匿名类型是不准确的
-
使用httpbin.org进行检测
-
-
数据库模块:实现对代理ip的增删改查操作
-
使用MongoDB来存储代理IP
-
-
检测模块:定时的对代理池中的代理进行检测,保证代理池中代理的可用性
-
从数据库中读取所有的代理ip
-
对代理IP进行逐一检测,可开启多个协程,以提高检测速度
-
如果该代理不可用,就让这个代理分数-1,当代理的分数到0了,就删除该代理,如果检测到代理可用就恢复为满分
-
-
代理IP服务接口:提供高可用的代理IP给爬虫使用
-
根据协议类型和域名获取随机的高质量代理IP
-
根据协议类型和域名获取多个高质量代理IP
-
根据代理IP,不可用域名,告诉代理池这个代理IP在该域名下不可用,下次获取这个域名的代理IP时候,就不会再获取这个代理IP了,从而保证代理IP高可用性
-
-
-
代理池的其他模块:
-
数据模型:domain.py
-
代理IP的数据模型,用于封装代理IP相关信息,比如IP,端口号,响应速度,协议类型,匿名程度,分数等。
-
-
程序启动入口:main.py
-
代理池提供一个统一的启动入口
-
-
工具模块
-
日志模块:用于记录日志信息
-
http模块:用于获取随机User-Agent的请求头
-
-
配置文件:settings.py
-
用于默认代理的分数,配置日志格式,文件,启动的爬虫,检验的间隔时间等
-
-
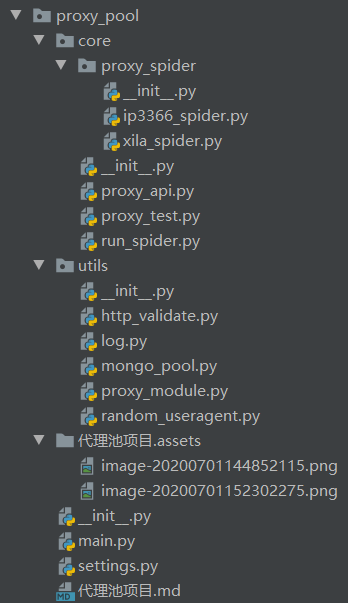
2.3代理池的项目结构
-
说明
-
proxy_pool为项目根目录
-
core为功能目录
-
proxy_spider目录为具体爬虫目录,单个爬虫实现了通用的接口
-
run_spider.py文件,为爬虫运行模块,实现所有爬虫的运行
-
proxy_test.py文件,为代理检测模块,负责从mongodb中读取文件,进行检验
-
proxy_api.py文件,通过flask,实现网页通用api
-
-
utils为工具目录
-
http_validate.py文件,负责检验proxy的可用性
-
log.py文件,负责文件日志记录和控制台输出
-
mongo_pool.py文件,数据库模块,实现增删改查
-
proxy_module.py文件,proxy的模型文件,定义关键字
-
random_useragent.py文件,负责提供随机的user-agent
-
-
main.py为项目运行入口,实现了各个模块之间的串连
-
settings.py为项目配置文件
-
.md文件 为说明文件
-
.assets目录 为.md文件的图片存放目录
-
-
3、实现代理的思路
-
思路1:
-
依据项目的设计的流程图,一步一步进行实现
-
遇到需要依赖于其他模块的地方,就暂停当前的模块,去实现其他模块中需要使用的功能
-
其他模块实现后,再回来接着写当前模块
-
-
思路2:
-
先实现基础模块,这些模块不依赖于其他的模块,如:数据模型,校验模块,数据库模块
-
然后实现具体的功能模块,如爬虫模块,检测模块,代理API模块
-
4、实现代理IP模型类
-
目标:定义代理IP的数据模型类
-
步骤:
-
定义Proxy类,继承object
-
实现
__init__方法,负责初始化,包括字段:-
ip:代理的IP地址
-
port:代理IP的端口号
-
protocol:代理IP支持的协议类型:http是0,https是1,http&https是2
-
nick_type:代理IP的匿名程度,高匿:0,匿名:1,透明:2
-
speed:代理IP的响应速度,单位s
-
area:代理IP所在地区
-
score:代理IP的评分,用于衡量代理的可用性,默认分数可以通过配置文件进行配置,在进行代理可用性检查时,没遇到一次请求失败就减去1,减到0时则从池中删除,如果检查代理可用,就恢CO复默认分值
-
disable_domains:不可用域名列表,有些代理IP在某些域名下不可用,但是在其他域名下可用
-
-
在配置文件:settings.py中定义MAX_SCORE=50,代表代理IP的默认最高分数
-
提供
__str__方法,返回数据字符串
-
-
代码
"""
模型类,定义关键字
"""
from .settings import MAX_SCORE
class Proxy(object):
def __init__(self, ip, port, protocol=-1, nick_type=-1, speed=-1, area=None, score=MAX_SCORE):
self.ip = ip
self.port = port
self.protocol = protocol
self.nick_type = nick_type
self.speed = speed
self.area = area
self.score = score
def __str__(self):
return str(self.__dict__)
5、实现代理IP的工具模块
5.1 日志模块
-
实现日志模块的目的
-
能够方便的对程序进行调试
-
能够方便记录程序的运行状态
-
能够方便记录错误信息
-
-
日志的实现
-
拷贝网络中的日志代码,根据自己的项目进行修改
-
整体代码
import sys
import logging
# 默认的配置
LOG_LEVEL = logging.INFO # 默认等级
LOG_FMT = '%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s: %(message)s' # 默认格式
LOG_DATEFMT = '%Y-%m-%d %H:%M:%S' # 默认时间格式
LOG_FILENAME = 'log.log' # 默认日志文件名称
class Logger(object):
def __init__(self):
# 获取一个logger对象
self._logger = logging.getLogger()
# 设置format对象
self.formatter = logging.Formatter(fmt=LOG_FMT, datefmt=LOG_DATEFMT)
# 设置日志输出
# -设置文件日志模式
self._logger.addHandler(self._get_file_handler(LOG_FILENAME))
# -设置终端日志模式
self._logger.addHandler(self._get_console_handler())
# 设置日志等级
self._logger.setLevel(LOG_LEVEL)
def _get_file_handler(self, filename):
"""返回一个文件日志handler"""
file_handler = logging.FileHandler(filename=filename, encoding='utf8')
file_handler.setFormatter(self.formatter)
return file_handler
def _get_console_handler(self):
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(self.formatter)
return console_handler
-
5.2 http模块
-
提供随机的User-Agent请求头
USER_AGENTS = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-GB; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11 (.NET CLR 3.5.30729)",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 GTB5",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; tr; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0a2) Gecko/20110622 Firefox/6.0a2",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0.1) Gecko/20100101 Firefox/7.0.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0b4pre) Gecko/20100815 Minefield/4.0b4pre",
"Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0 )",
"Mozilla/4.0 (compatible; MSIE 5.5; Windows 98; Win 9x 4.90)",
"Mozilla/5.0 (Windows; U; Windows XP) Gecko MultiZilla/1.6.1.0a",
"Mozilla/2.02E (Win95; U)",
"Mozilla/3.01Gold (Win95; I)",
"Mozilla/4.8 [en] (Windows NT 5.1; U)",
"Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.4) Gecko Netscape/7.1 (ax)",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.2; U; de-DE) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/234.40.1 Safari/534.6 TouchPad/1.0",
]
6、实现代理IP的校验模块
-
目的:检查代理IP速度,匿名程度以及支持的协议类型
-
步骤:
-
检查代理ip速度和匿名程度
-
代理ip速度:从发送请求到获取响应的时间间隔
-
匿名程度检查
-
对
http(https)://httpbin.org/get发送请求 -
如果响应的
origin中有由,分割的两个IP就是透明代理IP -
如果响应的
headers中包含``Proxy-Connection说明是匿名代理IP -
否则就是高匿代理IP
{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-5efc5633-ad2cb41439edaca07204ed84"
},
"origin": "171.42.143.174",
"url": "http://httpbin.org/get"
}
-
-
-
检查代理IP协议类型
-
如果
http://httpbin.org/get发送请求成功,说明支持http协议 -
如果
https://httpbin.org/get发送请求成功,说明支持https协议
-
-
-
import requests
import json
import time
from work_project.IpProxyPool.utils.http import RandomUserAgent
from work_project.IpProxyPool import settings
from work_project.IpProxyPool.utils.log import logger
from work_project.IpProxyPool.domain import Proxy
def _check_http_proxies(proxies=None, is_http=True):
nick_type = -1
speed = -1
if is_http:
test_url = 'http://httpbin.org/get'
else:
test_url = 'https://httpbin.org/get'
# 获取开始时间
start = time.time()
# 发送请求
headers = {
'User-Agent': "{}".format(RandomUserAgent()),
}
try:
response = requests.get(url=test_url, headers=headers, proxies=proxies, timeout=settings.TIMEOUT)
if response.ok:
# 响应速度
speed = round(time.time() - start, 2)
dict_ = json.loads(response.content.decode())
# 获取origin
origin = dict_.get('origin')
proxy_connection = dict_.get('headers').get('Proxy-Connection')
# 判断匿名程度
if ',' in origin:
nick_type = 2 # 2代表透明
elif proxy_connection:
nick_type = 1 # 1代表匿名
else:
nick_type = 0 # 0代表高匿
return True, nick_type, speed
return False, nick_type, speed
except Exception as ex:
# logger.exception(ex)
return False, nick_type, speed
def check_proxy(proxy):
"""
用于检查指定 代理ip 响应速度,匿名程度,支持协议类型
:param proxy: 代理IP模型对象
:return : 检查后的代理模型对象
"""
# 准备代理ip
proxies = {
"http": "http://{}:{}".format(proxy.ip, proxy.port),
'https': 'https://{}:{}'.format(proxy.ip, proxy.port)
}
# 测试该代理ip
is_http, http_nick_type, http_speed = _check_http_proxies(proxies=proxies, is_http=True)
is_https, https_nick_type, https_speed = _check_http_proxies(proxies=proxies, is_http=False)
if is_http