1、官方文档
https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/item-pipeline.html
2、简介
当item在Spider中被收集之后,它会将被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
3、编写item pipeline组件
通过在spider中yield item对象前,添加一个来源信息,item["come_from"]="spidername",以此来区分不同的返回的item。
也可以通过传递过来的spider.name属性来判断,即if spider.name='spidername'... else...
也可以导入item的类,通过if isinstance(item,myitem):...来执行相应的操作
item pipeline组件是一个独立的Python类,其中process_item()方法必须实现。
class SomethingPipeline(object): def __init__(self): # 可选实现,做参数初始化等 pass def process_item(self,item,spider): #item(Item对象)---被爬取的item #spider(Spider对象)---爬取该item的spider # 这个方法必须实现,每个item pipeline组件都需要调用该方法 # 这个方法必须返回一个Item对象,被丢弃的item将不会被之后的pipeline组件所处理 return item # 不return的情况下,另一个权重较低的pipeline就不会获取到该item def open_spider(self,spier): # spider(Spider对象)---被开启的spider # 可选参数,当spider被开启时,这个方法被调用 pass def close_spider(self,spider): # spider(Spider对象)---被关闭的spider # 可选实现,当spider被关闭时,这个方法被调用 pass
4、启动一个item pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到settings.py文件ITEM_PIPELINES配置
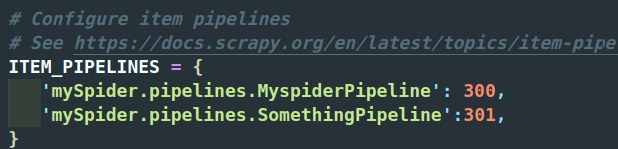
分配给每个类的整型值,确定了它们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
5、启动爬虫验证
`scrapy crawl projectName`
6、from_crawler(cls,crawler)方法
参数crawler时一个Crawler对象
from_crawler这个类方法从Crawler属性中创建一个pipeline实例,Crawler对象能够接触所有scrapy的核心组件,比如settings和signals。
```
import pymongo
class MongoPipeline(object):
collection_name = "scrapy_items"
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler): # 通过from_crawler方法获取settings中的MongoDB的url和数据名称,从而创建了一个MongoPipeline实例
return cls(
mongo_uri = crawler.settings.get("MONOG_URI")
mongo_db = crawler.settings.get("MONGO_DATABASE","items")
)
def open_spider(self,spider): # 当Spider开始运行时,再open_spider方法中建立数据库连接
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self,mongo_db]
def close_spider(self,spider): # 当Spider关闭时,再close_spider方法中关闭数据库连接
self.client.close()
def process_item(self,item,spider):
self.db[self.collection_name].insert(dict(item))
return item
```
7、item pipeline处理来自多个spider的item
(1)可以通过process_item(self,item,spider)中的Spider参数判断是来自哪个爬虫。
(2)配置Spider类中的custom_settings对象,为每一个Spider配置不同的Pipeline
```
class MySpider(CrawlSpider):
# 自定义配置
custom_settings = {
”ITEM_PIPELINES“:{
”test.pipelines.TestPipeline”:1,
}
}
```