参考url:
https://jakevdp.github.io/PythonDataScienceHandbook/05.13-kernel-density-estimation.html
密度评估器是一种利用D维数据集生成D维概率分布估计的算法,GMM算法用不同高斯分布的加权汇总来表示概率分布估计。核密度估计(kernel density estimation,KDE)算法将高斯混合理念扩展到了逻辑极限(logical extreme),它通过对每个点生成高斯分布的混合成分,获得本质上是无参数的密度评估器。
1、KDE的由来:直方图
密度估计评估器是一种寻找数据集生成概率分布模型的算法。
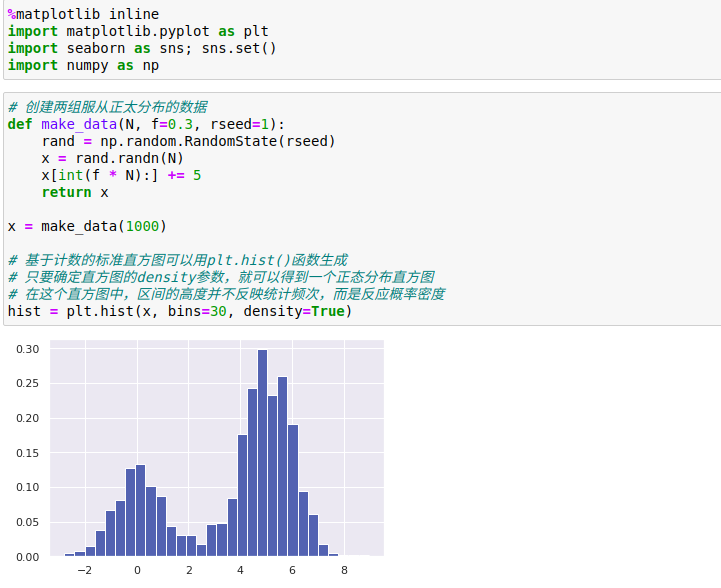
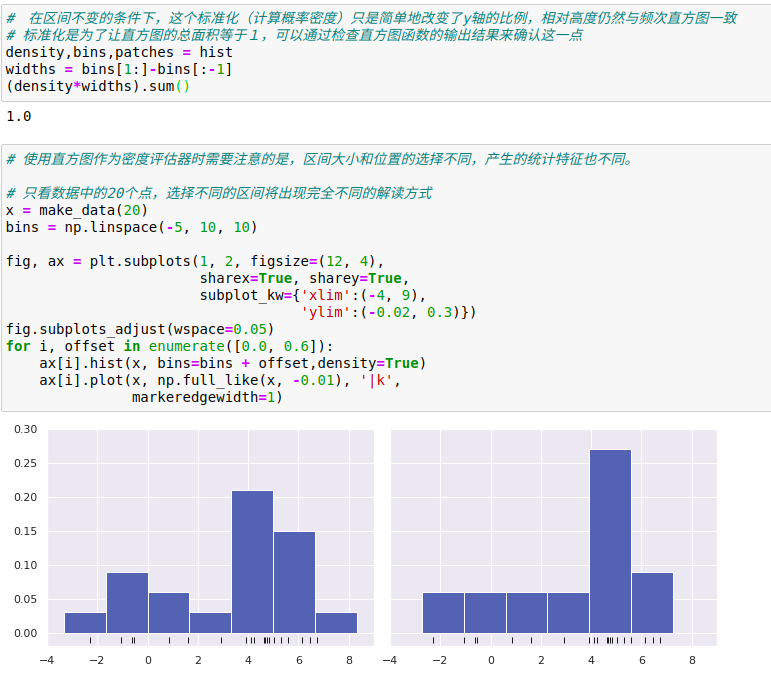
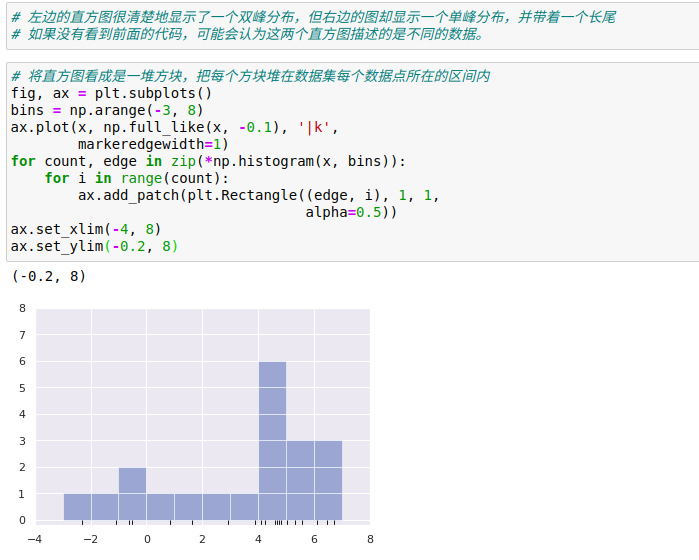
一维数据的密度估计——直方图,是一个简单的密度评估器,直方图将数据分成若干区间,统计落入每个区间内的点的数量,然后用直观的方式将结果可视化。
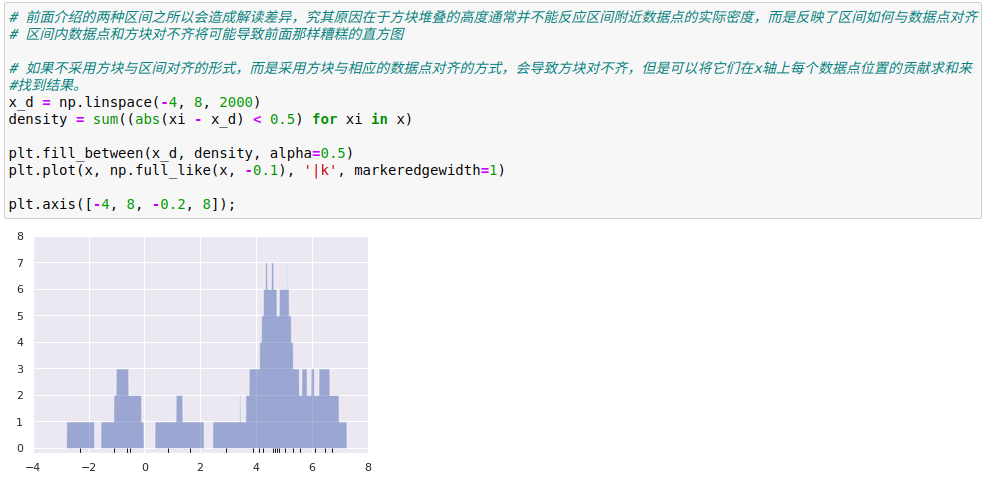

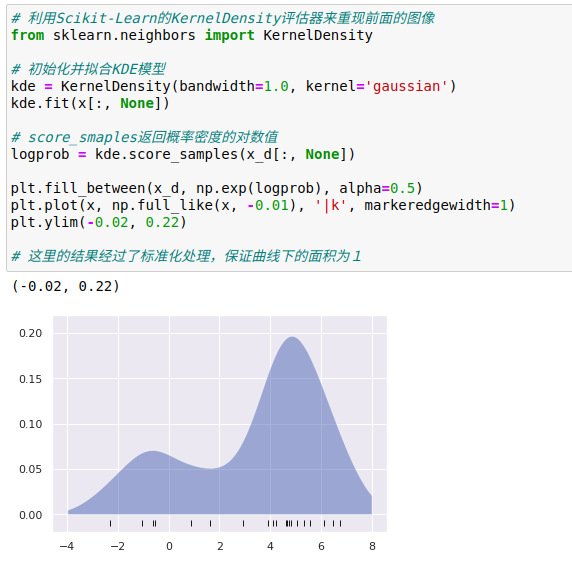
2、核密度估计的实际应用
核密度估计的自由参数是核类型(kernel)参数,他可以指定每个点核密度分布的形状。
核带宽(kernel bandwidth)参数控制每个点的核的大小
核密度估计算法在sklearn.neighbors.KernelDensity评估器中实现,借助六个核中的任意一个核、二三十个距离量度就可以处理具有多个维度的KDE。
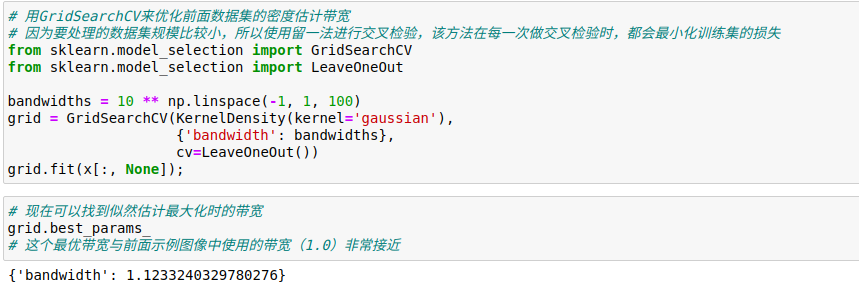
由于KDE计算量非常大,因此Scikit-Learn评估器底层使用了一种基于树的算法,可以利用atol(绝对容错)和rtol(相对容错)参数来平衡计算时间与准确性,可以用Scikit-Learn的标准交叉检验工具来确定自由参数核带宽。
通过交叉检验选择带宽
在KDE中,带宽的选择不仅对找到合适的密度估计非常重要,也是在密度估计中控制偏差-方差平衡的关键:
(1)带宽过窄将导致估计呈现高方差(即过拟合),而且每个点的出现或缺失都会引起很大的不同
(2)带宽过宽将导致估计呈现高偏差(即欠拟合),而且带宽较大的核还会破坏数据结构
机器学习中超参数的调优通常都是通过交叉检验完成的。