今日内容以及未来的计划:
1、并发编程需要掌握的知识点:
开启进程/线程
生产者消费者模型!!!(后面讲)
GIL全局解释器锁(进程与线程的区别和应用场景)
进程池线程池
10模型(理论)
2、多线程
线程vs进程
GIL全局解释器锁
线程池
二、新内容:
1、(1)进程只是把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是CPI上的执行单位
(2)线程相当于流水线(一条具体的地铁线路),进程是指的资源(北京地铁)
(3)改变主线程会影响其他线程(因为线程是共享资源)
改变主进程不会影响其他子进程(空间是隔离的,执行也是互不影响的)
(4)子线程改变同样会影响主线程
2、为什么要使用多线程

3、多线程
(1)线程的概念?—————
一个进程内默认就会有一个控制线程,该控制线程可以执行代码从而创建新的线程
该控制线程的执行周期就代表改进程的执行周期
(2)线程VS进程
1、线程的创建开销小于进程,创建速度快
2、同一进程下的多个线程共享该进程的地址空间
GIL全局解释器锁
线程池
4、开启线程的两个方式(为了使任务并发)
有两个线程(主线程,子线程(t.start()))
线程的开启速度快(开销小)
(1)线程开启的第一种方式


from threading import Thread import time,os def task(): print("%s is running"%os.getpid()) time.sleep(2) print("%s is done"%os.getpid()) if __name__=="__main__": t=Thread(target=task,) t.start() print("主")
from threading import Thread from multiprocessing import Process import time,os def task(): print("%s is running"%os.getpid()) time.sleep(2) print("%s is done"%os.getpid()) class Mythread(Thread): def __init__(self,name): super().__init__() self.name=name def run(self): print("%s is running"%os.getpid()) time.sleep(5) print("%s is done"%os.getpid()) if __name__=="__main__": t=Mythread("xxxx") t.start() print("主")
总结:
(1)一个进程内不开子进程也不开“子线程”,主线程结束,该进程就结束
(2)当一个进程内开启子进程时:
主线程结束,主进程要等,等所有子进程运行完毕,给儿子收尸
(3)当一个进程内开启多个线程时;
主线程结束并不意味着看进程结束;
进程的结束指的是该进程内所有的线程都运行完毕,才应该回收进程
5、ID号的说明
from threading import Thread from multiprocessing import Process import time,os def task(): print("partent,%s self,%s"%(os.getpid(),os.getpid())) time.sleep(2) if __name__=="__main__": t=Thread(target=task,) # t=Process(target=task(),) t.start() print("主",os.getpid(),os.getpid())
6、开子进程需要申请空间
(1)进程之间内存空间隔离
线程之间内存空间隔离
from threading import Thread from multiprocessing import Process import time,os n=100 def task(): global n n=0 if __name__=="__main__": t=Thread(target=task,) #线程之间内存空间共享 # t=Process(target=task,) #进程之间内存空间隔离 t.start() t.join() print("主",n)
7、了解部分
用来调试线程,查看是哪一条线程(测试时会用到)
# 用来调试线程,查看是哪一条线程(测试时会用到) from threading import Thread,current_thread import time,os def task(): print("%s is running"%current_thread().getName()) time.sleep(5) print("%s is done"%current_thread().getName()) if __name__=="__main__": t=Thread(target=task,name="xxx") t=Thread(target=task,) t=Thread(target=task,) t.start() # print(t.name) print("主",current_thread().getName())
查看当前活着的线程
# 用来调试线程,查看是哪一条线程(测试时会用到) from threading import Thread,current_thread,enumerate,active_count import time,os def task(): print("%s is running"%current_thread().getName()) time.sleep(1) print("%s is done"%current_thread().getName()) if __name__=="__main__": t=Thread(target=task,name="xxx") t=Thread(target=task) t.start() # print(t.name) print("主",current_thread().getName()) # 查看当前活着的线程 print(enumerate()[0].getName()) print(active_count()) print("主",current_thread().getName())
8、线程池
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import current_thread import time,random def task(): print("%s is running"%current_thread().getName()) time.sleep(random.randint(1,3)) if __name__=="__main__": # t=ProcessPoolExecutor() 默认cpu的核数 # import os # print(os.cpu_count()) t=ThreadPoolExecutor(3) for i in range(10): t.submit(task,) t.shutdown(wait=True) print("主",current_thread().getName())
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor from threading import current_thread import time,random def task(n): print("%s is running"%current_thread().getName()) time.sleep(random.randint(1,3)) return n**2 if __name__=="__main__": # t=ProcessPoolExecutor() 默认cpu的核数 # import os # print(os.cpu_count()) t=ThreadPoolExecutor(3) #默认是cpu的核数*5 objs=[] for i in range(10): obj=t.submit(task,i) objs.append(obj) t.shutdown(wait=True) for obj in objs: print(obj.result()) print("主",current_thread().getName())
9、什么时候用池:用量大的时候
什么时候时候用进程 什么时候用线程
10、补充异步的概念
爬虫中的应用
(1)串着爬取:
#pip install resquests import requests from threading import current_thread urls=[ "https://www.python.org", "https://www.baidu.com", "https://www.tmall.com", ] def get(url): print("%s GET %s"%(current_thread().getName(),url)) response=requests.get(url) if response.status_code==200: return {"url":url,"text":response.text} def parse(res): print("%s parse %s"%(current_thread().getName(),res["url"])) print("[%s] parse res[%s]"%(res["url"],len(res["text"]))) for url in urls: res=get(url) parse(res)
使用正则:
#pip install resquests import requests from threading import current_thread urls=[ "https://www.python.org", "https://www.baidu.com", "https://www.tmall.com", ] def get(url): print("%s GET %s"%(current_thread().getName(),url)) response=requests.get(url) if response.status_code==200: return {"url":url,"text":response.text} def parse(res): # print("%s parse %s"%(current_thread().getName(),res["url"])) # print("[%s] parse res[%s]"%(res["url"],len(res["text"]))) print("[%s] <%s> (%s)"%(current_thread().getName(),res["url"],len(res["text"]))) for url in urls: res=get(url) parse(res)
(2)开发爬取 异步的方式提交
爬虫是下载耗时,解析的时间是可以忽略不计的
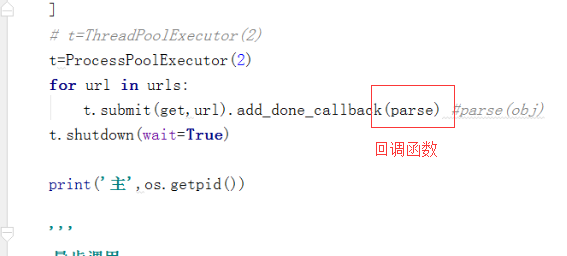
#pip install resquests import requests from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor from threading import current_thread import time import os def get(url): print("%s GET %s"%(os.getpid(),url)) response=requests.get(url) time.sleep(3) if response.status_code==200: return {"url":url,"text":response.text} def parse(obj): res=obj.result() print("[%s] <%s> (%s)"%(os.getpid(),res["url"],len(res["text"]))) if __name__=="__main__": urls=[ "https://www.python.org", "https://www.baidu.com", "https://www.tmall.com", ] t=ProcessPoolExecutor(2) for url in urls: t.submit(get,url).add_done_callback(parse) t.shutdown(wait=True) print("主",os.getpid())

下节课继续完善
# pip install requests import requests from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor from threading import current_thread import time import os def get(url): print('%s GET %s' %(current_thread().getName(),url)) response=requests.get(url) time.sleep(3) if response.status_code == 200: return {'url':url,'text':response.text} def parse(obj): res=obj.result() print('[%s] <%s> (%s)' % (current_thread().getName(), res['url'],len(res['text']))) if __name__ == '__main__': urls = [ 'https://www.python.org', 'https://www.baidu.com', 'https://www.jd.com', 'https://www.tmall.com', ] t=ThreadPoolExecutor(2) for url in urls: t.submit(get,url).add_done_callback(parse) t.shutdown(wait=True) print('主',os.getpid())
、