一、jvm内存调优 (Gc 和 Full gc)
hotspot
-Xms40m 最小堆内存
-Xmx512m 最大值内存
-verboose:gc
-XX:PrintGCDetails
-XX:printGCDateStamps
-Xloggc:D:/gc/gc.log
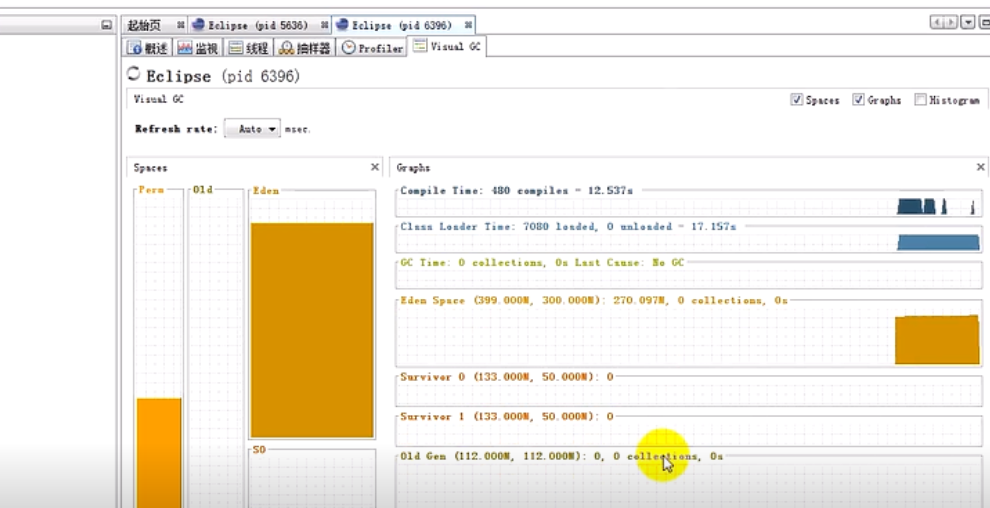
调优主要调到Gc [PSYoungGen: 10752k->1530k(12288k)] 不出现即可。
PSYoungGen : Young 年轻
Prallel Scavenge: 年轻代并行收集器
10752k -->1530k(12288k)
当前年轻代大小 --->gc之后年轻代大小 (年轻代总的分配的空间)
10752中-->2543k(39936k)
堆内存
调优工具:Eclipse软件
#jvm内存调优参数 (备注:调优gc )
用编辑器打开:eclipse.ini 文件
-Xms512m #堆的大小,默认512m
-Xmx512m #堆的大小,默认512m
-XX:NewSize=400m #年轻代大小
-XX:MaxNewSize=400m #年轻代大小
-XX:PermSize=90m #永久代大小
-XX:MaxPermSize=90m #永久代大小
查看日志: gc.log
2017-02-22To0:57:18.252+0800 : 9.149: 【Full GC [PSYoungGen: 1521k ->0k(23040k)]】....后面省略。
Linux系统中,安装好tomcat,
#配置文件路径 [root@nulige bin]# cd /application/tomcat/bin [root@nulige bin]# ll total 788 -rw-r--r-- 1 root root 28393 Sep 28 2015 bootstrap.jar -rw-r--r-- 1 root root 13825 Sep 28 2015 catalina.bat -rwxr-xr-x 1 root root 21389 Sep 28 2015 catalina.sh -rw-r--r-- 1 root root 1647 Sep 28 2015 catalina-tasks.xml -rw-r--r-- 1 root root 24283 Sep 28 2015 commons-daemon.jar -rw-r--r-- 1 root root 204944 Sep 28 2015 commons-daemon-native.tar.gz -rw-r--r-- 1 root root 2040 Sep 28 2015 configtest.bat -rwxr-xr-x 1 root root 1922 Sep 28 2015 configtest.sh -rwxr-xr-x 1 root root 7888 Sep 28 2015 daemon.sh -rw-r--r-- 1 root root 2091 Sep 28 2015 digest.bat -rwxr-xr-x 1 root root 1965 Sep 28 2015 digest.sh -rw-r--r-- 1 root root 3430 Sep 28 2015 setclasspath.bat -rwxr-xr-x 1 root root 3547 Sep 28 2015 setclasspath.sh -rw-r--r-- 1 root root 2020 Sep 28 2015 shutdown.bat -rwxr-xr-x 1 root root 1902 Sep 28 2015 shutdown.sh -rw-r--r-- 1 root root 2022 Sep 28 2015 startup.bat -rwxr-xr-x 1 root root 1904 Sep 28 2015 startup.sh -rw-r--r-- 1 root root 40882 Sep 28 2015 tomcat-juli.jar -rw-r--r-- 1 root root 388787 Sep 28 2015 tomcat-native.tar.gz -rw-r--r-- 1 root root 4057 Sep 28 2015 tool-wrapper.bat -rwxr-xr-x 1 root root 5061 Sep 28 2015 tool-wrapper.sh -rw-r--r-- 1 root root 2026 Sep 28 2015 version.bat -rwxr-xr-x 1 root root 1908 Sep 28 2015 version.sh
#调优参数 (备注:根据服务器硬件配置,进行调优)
优化catalina.sh配置文件。在catalina.sh配置文件中添加以下代码: JAVA_OPTS="-Djava.awt.headless=true -Dfile.encoding=UTF-8 -server -Xms1024m -Xmx1024m -XX:NewSize=512m -XX:MaxNewSize=512m -XX:PermSize=512m -XX:MaxPermSize=512m" server:一定要作为第一个参数,在多个CPU时性能佳 -Xms:初始堆内存Heap大小,使用的最小内存,cpu性能高时此值应设的大一些 -Xmx:初始堆内存heap最大值,使用的最大内存 上面两个值是分配JVM的最小和最大内存,取决于硬件物理内存的大小,建议均设为物理内存的一半。 -XX:PermSize:设定内存的永久保存区域 -XX:MaxPermSize:设定最大内存的永久保存区域 -XX:MaxNewSize: -Xss 15120 这使得JBoss每增加一个线程(thread)就会立即消耗15M内存,而最佳值应该是128K,默认值好像是512k. +XX:AggressiveHeap 会使得 Xms没有意义。这个参数让jvm忽略Xmx参数,疯狂地吃完一个G物理内存,再吃尽一个G的swap。 -Xss:每个线程的Stack大小 -verbose:gc 现实垃圾收集信息 -Xloggc:gc.log 指定垃圾收集日志文件 -Xmn:young generation的heap大小,一般设置为Xmx的3、4分之一 -XX:+UseParNewGC :缩短minor收集的时间 -XX:+UseConcMarkSweepGC :缩短major收集的时间
二、垃圾回收机制处法
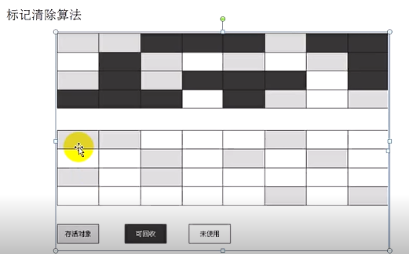
2.1、标记清除算法
标记-清除(Mark-Sweep)算法是最基础的算法,就如它的名字一样,算法分为”标记”和”清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。它主要有两个缺点:一个是效率问题,标记和清楚过程的效率都不高;另外一个是空间问题,标记清楚后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够连续的内存空间而不得不提前出发另一次垃圾收集动作。
内存会产生碎片,导致没有空间来分配,会发生Full GC,导致进程会停顿。
2.2、复制算法
内存划分成两块,会先使用一块,用完后,就会放到保留区,再把原来的空间一次性清理掉。(实际分配比例,不是按一比一分配的,新生代>老年代。)
为了解决效率问题,一种称为复制(Copying)的收集算法就出现了,它将可用内存按容量划分为大小相等的两块,每次只是用其中一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对其中的一块进行内存回收,没存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将员村缩小为原来的一半,未免太高了一点。
优点:解决内存碎片的问题。
缺点:例如:64G内存,只使用其中一半。

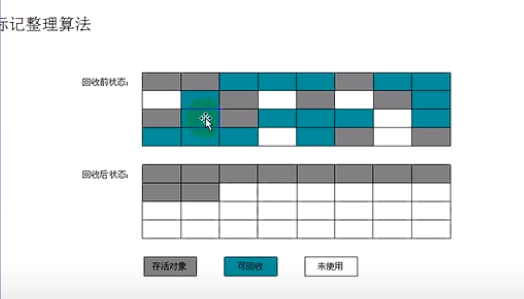
2.3、标记整理算法
标记-整理(Mark-Compact)算法不直接对可回收对象进行清理,而是让所有可用的对象都向一端移动。然后直接清理掉边界意外的内存。
复制手机算法在对象存活率较高时就要执行较多的复制操作,效率将会贬低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种”标记-整理”算法,标记过程仍然与标记-清楚算法一样,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界意外的内存。
2.4、分代收集算法
当前商业虚拟机的垃圾收集都采用分代收集(Generational Collection)算法,这种算法并没有什么新的思想,只是根据对象的存货周期的不同将内存划分为几块。一般是把Java堆分成新生代和老年代,这样就可以根据各个年代的特点采用最适当的手机算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那么就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用标记-清理或标记-整理算法来进行回收
三、垃圾收集器
3.1、Serial : 串行收集器 (备注:单核cpu,单线程收集),属于新生代收集器
Serial收集器是JAVA虚拟机中最基本、历史最悠久的收集器,在JDK 1.3.1之前是JAVA虚拟机新生代收集的唯一选择。Serial收集器是一个单线程的收集器,但它的“单线程”的意义并不仅仅是说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。
要是服务器每运行一个小时就会暂停5分钟,老板会有什么样的心情?
3.2、ParNew: 并行收集器 (备注:多线程同时收集) ,属于新生代收集器
ParNew收集器是JAVA虚拟机中垃圾收集器的一种。它是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为包括Serial收集器可用的所有控制参数(例如:-XX:SurvivorRatio、-XX:PretenureSizeThreshold、-XX:HandlePromotionFailure等)、收集算法、Stop The World、对象分配规则、回收策略等都与Serial收集器一致。
3.3、Parallel scavenge: 并行收集器,属于新生代收集器
Parallel Scavenge收集器的关注点与其他收集器不同, ParallelScavenge收集器的目标则是达到一个可控制的吞吐量(Throughput)。所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间),虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
由于与吞吐量关系密切,Parallel Scavenge收集器也经常被称为“吞吐量优先”收集器。
该垃圾收集器,是JAVA虚拟机在Server模式下的默认值,使用Server模式后,java虚拟机使用Parallel Scavenge收集器(新生代)+ Serial Old收集器(老年代)的收集器组合进行内存回收。
3.4、Serial old: 老年代
3.5、Parallel old: 老年代,多线程,并行处理
3.6、CMS concurrent Nark Sweep 并发标记整理 (备注:老年代中用得最多的收集器)
并发标记清理(Concurrent Mark Sweep,CMS)收集器也称为并发低停顿收集器(Concurrent Low Pause Collector)或低延迟(low-latency)垃圾收集器;
在前面ParNew收集器曾简单介绍过其特点;
针对老年代;
基于"标记-清除"算法(不进行压缩操作,产生内存碎片);
以获取最短回收停顿时间为目标;
并发收集、低停顿;
需要更多的内存(看后面的缺点);
3.7、G1
整堆收集器:G1,不会产生碎片
(A)、并行与并发
能充分利用多CPU、多核环境下的硬件优势;
可以并行来缩短"Stop The World"停顿时间;
也可以并发让垃圾收集与用户程序同时进行;
(B)、分代收集,收集范围包括新生代和老年代
能独立管理整个GC堆(新生代和老年代),而不需要与其他收集器搭配;
能够采用不同方式处理不同时期的对象;
虽然保留分代概念,但Java堆的内存布局有很大差别;
将整个堆划分为多个大小相等的独立区域(Region);
新生代和老年代不再是物理隔离,它们都是一部分Region(不需要连续)的集合;
四、使用方法
看应用场景:
单核cpu: 使用GMS + Serial
多核cpu: 使用GMS + ParNew
Serialold + Serial /Parallel scavenge /ParNew
Parallel old + Parallel scavenge
Eden from survivor to survivor
五、其它
Java虚拟机垃圾回收, 7种垃圾收集器 。
参考:https://blog.csdn.net/tjiyu/article/details/53983650
视频学习地址:https://v.qq.com/x/page/s0379plgejm.html