有消息称,阿里巴巴达摩院正在研发一款神经网络芯片——Ali-NPU,主要运用于图像视频分析、机器学习等AI推理计算。按照设计,这款芯片性能将是目前市面上主流CPU、GPU架构AI芯片的10倍,而制造成本和功耗仅为一半,其性价比超过40倍。
应用上,通过此款芯片的研发将会更好的落地在图像、视频识别、云计算等商业场景中。据阿里达摩院研究员骄旸介绍说:“CPU、GPU作为通用计算芯片,为处理线程逻辑和图形而设计,处理AI计算问题时功耗高,性价比低,在AI计算领域急需专用架构芯片解决上述问题。阿里巴巴此款Ali-NPU在AI领域积累了大量算法模型优势,以最小成本实现最大量的AI模型算法运算。”
英特尔、英伟达、AMD等传统芯片处理器巨头在CPU和GPU上存在的优势,而且它们都将人工智能定位为未来重要战略。
事实上,随着人工智能产业的发展,CPU、GPU、TPU、DPU、NPU、BPU……各种PU也开始爆发式出现。那么,究竟这些PU在性能和使用上有何异同,又有哪些优劣呢?
CPU:计算力占据部分很小 擅长逻辑控制
CPU是最为普遍,最为常见的中央处理器。主要包括运算器(ALU)和控制单元(CU),除此之外还包括若干寄存器、高速缓存器和它们之间通讯的数据、控制及状态的总线。依循冯诺依曼架构,CPU需要大量空间放置存储单元和控制逻辑,计算能力只占据很小的部分,更擅长逻辑控制。
GPU:计算单元数量众多 但无法单独使用
GPU的诞生可以解决CPU在计算能力上的天然缺陷。采用数量众多的计算单元和超长的流水线,善于处理图像领域的运算加速。但GPU的缺陷也很明显,即无法单独工作,必须由CPU进行控制调用才能工作。

TPU:高性能低功耗 然则开发周期长、转换成本高
谷歌专门为 TensorFlow 深度学习框架定制的TPU,是一款专用于机器学习的芯片。TPU可以提供高吞吐量的低精度计算,用于模型的前向运算而不是模型训练,且能效更高。但它的缺陷主要是开发周期长、可配置性能有限,缺乏灵活性且转换成本高。

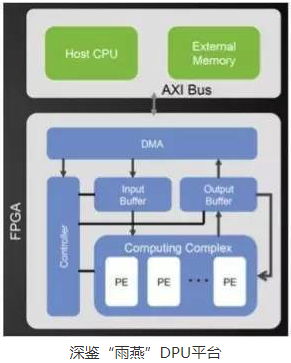
国际上,Wave Computing最早提出DPU。在国内,DPU最早是由深鉴科技提出,是基于Xilinx可重构特性的FPGA芯片,设计专用深度学习处理单元,且可以抽象出定制化的指令集和编译器,从而实现快速的开发与产品迭代。
NPU:运行效率提升 不支持大样本训练
NPU是神经网络处理器,在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理。相比于CPU和GPU的冯诺伊曼结构,NPU通过突触权重实现存储和计算一体化,从而提高运行效率。但NPU也有自身的缺陷,比如不支持对大量样本的训练。

BPU:比在CPU上用软件实现更为高效 不可再编程
BPU是由地平线主导的嵌入式处理器架构。第一代是高斯架构,第二代是伯努利架构,第三代是贝叶斯架构。BPU主要是用来支撑深度神经网络,比在CPU上用软件实现更为高效。然而,BPU一旦生产,不可再编程,且必须在CPU控制下使用。
从CPU、GPU的市场来看,已经基本被英特尔、英伟达和AMD三分天下。而在ASIC框架下的TPU,只有谷歌的体量和实力才有开发专用加速的动力。
推出DPU的深鉴科技有清华和斯坦福双重学术背景,公司目前的两条发展路线是:以芯片技术为主的纯技术路线,以及基于技术的产品路线。其处理器做深度学习应用端,不做训练端。目前,其深度压缩技术可以将神经网络压缩数十倍而不影响精度,还可以使用芯片存储深度学习算法模型,减少内存读取次数,降低运行功耗。
去年10月,深鉴科技推出了六款AI产品,分别是人脸检测识别模组、人脸分析解决方案、视频结构化解决方案、ARISTOTLE架构平台,深度学习SDK DNNDK,以及双目深度视觉套件。
寒武纪最初是中科院从2008年开始的一研究项目,负责人为陈氏兄弟陈云霁和陈天石,也是寒武纪科技的创始人,与他们合作研究Diannao系列的Olivier Temam是Google TPU的主架构师。2016年11月,寒武纪科技正式成立,同时推出世界首款商用深度学习专用处理器 Cambricon-AI,是一款神经网络处理器,面向手机、无人机等类手机的终端设备。
去年,一时火爆的华为麒麟970一大卖点就是集成了独立NPU,被宣传为世界首款手机AI芯片。确实属实。但据了解,这块NPU也并非华为的研究成果,而是来自寒武纪。对于华为来说,之所以如此重视NPU,或许和阿里爆出新闻的心态一样,认为集成NPU代表了人工智能未来的发展趋势。
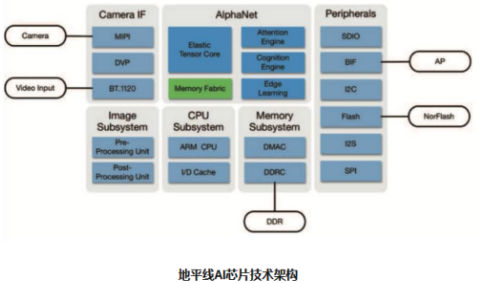
去年底,地平线在创办两年后终于发布首款芯片——“征程”与“旭日”。目前,这两款处理器都属于嵌入式人工智能视觉芯片,分别面向智能驾驶和智能摄像头。2018年CES上,英特尔和地平线还发布了基于伯努利架构的新一代征程处理器,其发展路径图为:2018年,感知;2019年,建模;2020年,决策。
而因为与英特尔的合作,地平线不禁让市场联想到英特尔早前重金收购的Mobileye。在嵌入式人工智能领域,Mobileye是业界领头羊。地平线在英特尔的定位版图是否是中国版Mobileye?但其创始人余凯的抱负是,地平线是要做中国的英特尔。
最后,谈到人工智能芯片,还是不得不提BAT。在国际四大科技巨头都造芯片,且ARM、英特尔、英伟达等传统芯片厂商仍然统治芯片天下的情况下,中国芯能不能发展起来,还需要看国内科技巨头们的表现。相较而言,阿里在三家中最为热衷芯片布局,上述包括寒武纪、深鉴科技均有阿里参投。
趣闻二:
“神经网络(Neural Networks)”和“机器学习(Machine Learning)”是近两年移动处理器领域最流行的两个词。华为麒麟970的NPU(神经网络处理器)、Google Pixel 2内置的IPU(图像处理器),以及苹果A11 Bionic,都是实现上述功能特性的专用硬件解决方案。
既然华为、Google和苹果都在都在探索神经引擎处理器,你可能以为机器学习需要特定的硬件。其实不然,神经网络可以在任何形式的处理器上运行,从微处理器到CPU、GPU甚至是DSP。
所以,问题的根本不在于处理器是否能利用神经神经网络和机器学习,而在于它到底有多快,能提升多少效率。
如果时间倒退回30年前,当年的桌面处理器是没有的FPU(浮点运算单元)芯片的,在486之后,Intel把FPU集成到了CPU内部,浮点运算性能大幅提升。而在很多实例计算中,全都是浮点数运算。这样以来,有FPU和没有FPU,运算效率天差之别。
而如今,移动处理器中的NPU也是类似的情况。你可能觉得我们并不需要NPU,就能使用神经网络,但实时情况是,华为正在用事实案例证明,当遇到实时处理运算的情况,NPU是必须的。
简单来说,“神经网络”可以理解为“机器学习”中“教”一台机器区别分辨不同“事物”的一系列技术中的一种。上述“事物”可以是一张照片、一个单词甚至是一种动物的声音,诸如此类。
“神经网络”由很多“神经元”组成,这些“神经元”可以接收输入信号,然后通过网络再向外传播信号,这取决于输入的强度和自身阈值。
举个简单的例子,神经网络正在监测一组灯其中一个的开关,但在网络中,这些灯的状态只能0或者1来表达,但不同的灯可能会出现一样的开关状态。
那么问题来了,神经网络怎么知道是该输出0还是该输出1呢?没有规则或者程序能告诉神经网络,输出我们想得到的逻辑答案。

唯一的方面就是对神经网络进行训练。大量的“样本”和预期结果一起被注入到神经网络中,各种各样的阈值反复微调,不断产生接近预期的结果。这个阶段可以称为“训练阶段”。
这听起来很简单,但实际上相当复杂,尤其是遇到语言、图像这种复杂样本的时候。一旦训练达成,神经网络会自动学会输出预期结果,即便输入的“样本”之前从来没有见过。
神经网络训练成功后,本质上就成了一种静态神经网络模型,它就能应用在数以百万计的设备上用于推理,在CPU、GPU甚至是DSP上运行。这个阶段可以称为“推理阶段”。
Gary Sims指出,“推理阶段”的难度要低于“训练阶段”,而这正是NPU发挥专长的地方。
所以,华为麒麟970最大的不同是,专门设置了NPU硬件芯片,它在处理静态神经网络模型方面有得天独厚的优势,不仅更快,还更有效率。事实上,NPU甚至能以17-33fps实时处理智能手机摄像头拍摄的“直播”视频。
其次是功耗和效率。NPU并非“电老虎”会牺牲手机的续航,相反它能高效的帮CPU承担大量推理运算的任务,反而能节省不少功耗。
总结,Gary Sims表示,如果华为能吸引更多第三方App开发者使用NPU,其前景不可限量。想象一下,当App在使用图像、声音、语音识别的时候,全部都能本地处理,不再需要网络连接或者云服务,App的使用体验将大大提升和加强。
试想,一名游客直接通过相机App就能认出当地地标,App能智能识别你的食物并给出相应的卡路里熟知、提醒食物过敏......
你认为,NPU会像当年FPU之于CPU一样,成为移动Soc芯片的标准吗?不妨在评论中发表自己的看法。
1、NPU
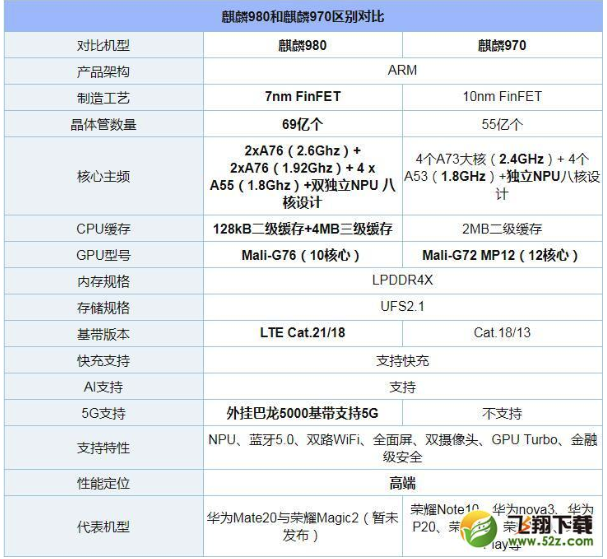
麒麟980的独立NPU相比麒麟970也有所升级,其配备双两个NPU单元,算力更强,支持人脸识别、物体识别、物体检测、图像分割、智能翻译等AI场景,并有更高精度的深度网络,具备更佳的实时性。
2、内存支持
麒麟980虽然和麒麟970一样,均支持LPDDR4X内存,不过麒麟980支持目前最高的LPDDR4X 2133Mhz高频内存,带宽可达34.1GB/s,相比麒麟970有所提升。
至于内存方面,则与麒麟970保存不变,依然是支持UFS 2.1。
3、视频解码
视频解码,麒麟980配备了新的第四代ISP,而且是双单元配置,相比麒麟970解码速度号称提升达46%,同时支持4K60fps视频解码、4K30fps视频编码。
3、GPU不同
上一代麒麟970内置的Mali-G72 MP12 12核心设计,主频为746Mhz。而新一代麒麟980则内置的是Mali-G76 10核心设计,主频为720Mhz。
表面上看,麒麟980的核心数和频率都有所降低,但事实上其用的是新一代更先进架构的Mali-G76,相比G72性能其实明显更强了。按照华为官方宣布的数据,其图像性能最高提升达到46%。
4、基带不同
新一代麒麟980基带版本为LTE Cat.21/18,相比麒麟970的Cat.18/13,提升了一个档次。麒麟980移动网络最高速率达到1.4Gbps,目前全网最快。它支持4x4 MIMO、三个20Hz载波聚合、256-QAM等特性。
另外,随着5G网络将于明显开启商用,麒麟980支持外挂巴龙5000基带实现对5G网络的支持。而上一代麒麟970则不支持5G网络,即便外挂基带也可能不支持。
参考:http://www.eefocus.com/mcu-dsp/408822