进程与线程的描述
一个进程至少会创建一个线程,多个线程共享一个程序进程的内存。程序的运行最终是靠线程来完成操作的。线程的数量跟CPU核数有关,一个核最多能发出两个线程。线程的操作主要分为:一:给CPU进行程序命令的执行。二:IO的操作(读取或输出数据)或者请求网络数据。
IO复用形成原因
如果一个I/O流进来,我们就开启一个进程处理这个I/O流。那么假设现在有一百万个I/O流进来,那我们就需要开启一百万个进程一一对应处理这些I/O流(——这就是传统意义下的多进程并发处理)。思考一下,一百万个进程,你的CPU占有率会多高,这个实现方式及其的不合理。所以人们提出了I/O多路复用这个模型,一个线程,通过记录I/O流的状态来同时管理多个I/O,可以提高服务器的吞吐能力
IO模型
阻塞IO模型
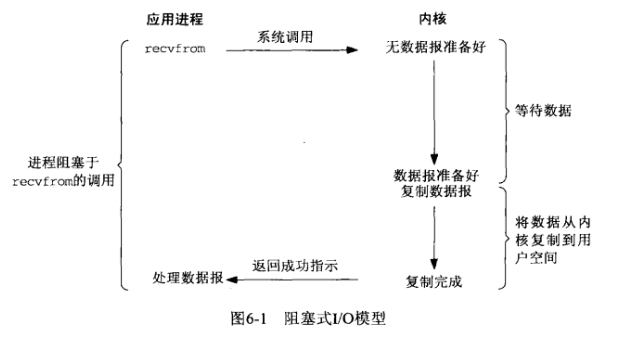
非阻塞IO模型
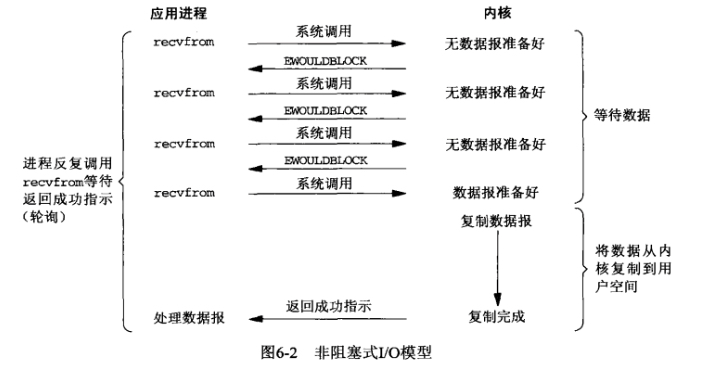
IO复用模型
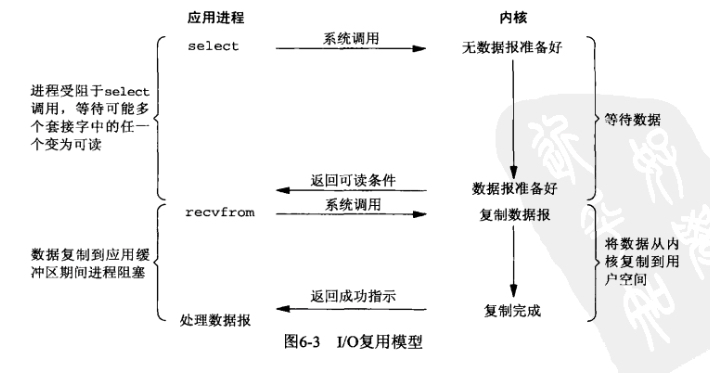
信号驱动式IO模型
异步IO模型

多路复用的实现有多种方式:select、poll、epoll
select
调用过程
a. 从用户空间将fd_set拷贝到内核空间
b. 注册回调函数
c. 调用其对应的poll方法
d. poll方法会返回一个描述读写是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
e. 如果遍历完所有的fd都没有返回一个可读写的mask掩码,就会让select的进程进入休眠模式,直到发现可读写的资源后,重新唤醒等待队列上休眠的进程。如果在规定时间内都没有唤醒休眠进程,那么进程会被唤醒重新获得CPU,再去遍历一次fd。
f. 将fd_set从内核空间拷贝到用户空间
优缺点
缺点:两次拷贝耗时、轮询所有fd耗时,支持的文件描述符太小
优点:跨平台支持
poll
调用过程(与select完全一致)
优缺点
优点:连接数(也就是文件描述符)没有限制(链表存储)
缺点:大量拷贝,水平触发(当报告了fd没有被处理,会重复报告,很耗性能)
epoll
epoll的ET与LT模式
LT:延迟处理,当检测到描述符事件通知应用程序,应用程序不立即处理该事件。那么下次会再次通知应用程序此事件。
ET:立即处理,当检测到描述符事件通知应用程序,应用程序会立即处理。
ET模式减少了epoll被重复触发的次数,效率比LT高。我们在使用ET的时候,必须采用非阻塞套接口,避免某文件句柄在阻塞读或阻塞写的时候将其他文件描述符的任务饿死
调用过程
a. 当调用epoll_wait函数的时候,系统会创建一个epoll对象,每个对象有一个evenpoll类型的结构体与之对应,结构体成员结构如下。
rbn,代表将要通过epoll_ctl向epll对象中添加的事件。这些事情都是挂载在红黑树中。
rdlist,里面存放的是将要发生的事件
b. 文件的fd状态发生改变,就会触发fd上的回调函数
c. 回调函数将相应的fd加入到rdlist,导致rdlist不空,进程被唤醒,epoll_wait继续执行。
d. 有一个事件转移函数——ep_events_transfer,它会将rdlist的数据拷贝到txlist上,并将rdlist的数据清空。
e. ep_send_events函数,它扫描txlist的每个数据,调用关联fd对应的poll方法去取fd中较新的事件,将取得的事件和对应的fd发送到用户空间。如果fd是LT模式的话,会被txlist的该数据重新放回rdlist,等待下一次继续触发调用。
优缺点
优点:
- 没有最大并发连接的限制
- 只有活跃可用的fd才会调用callback函数
- 内存拷贝是利用mmap()文件映射内存的方式加速与内核空间的消息传递,减少复制开销。(内核与用户空间共享一块内存)
只有存在大量的空闲连接和不活跃的连接的时候,使用epoll的效率才会比select/poll高
总结
IO分两阶段:
1.数据准备阶段 2.内核空间复制回用户进程缓冲区阶段
一般来讲:阻塞IO模型、非阻塞IO模型、IO复用模型(select/poll/epoll)、信号驱动IO模型都属于同步IO,因为阶段2是阻塞的(尽管时间很短)。只有异步IO模型是符合POSIX异步IO操作含义的,不管在阶段1还是阶段2都可以干别的事。