一、发布订阅
发布订阅:发布者 在一个频道内发布消息,所有订阅该频道的订阅者都可以收到,类似我们的收音机
注意:后订阅者无法查看历史信息

常用命令:
publish channel message #发布命令 publish souhu:tv "hello world" #在souhu:tv频道发布一条hello world 返回订阅者个数 subscribe [channel] #订阅命令,可以订阅一个或多个 subscribe souhu:tv #订阅sohu:tv频道 unsubscribe [channel] #取消订阅一个或多个频道 unsubscribe sohu:tv #取消订阅sohu:tv频道 psubscribe [pattern...] #订阅模式匹配 psubscribe c* #订阅以c开头的频道 unpsubscribe [pattern...] #按模式退订指定频道 pubsub channels #列出至少有一个订阅者的频道,列出活跃的频道 pubsub numsub [channel...] #列出给定频道的订阅者数量 pubsub numpat #列出被订阅模式的数量
二、慢查询
定义:我们配置一个时间,如果查询时间超过了我们设置的时间,那么它就是一个慢查询
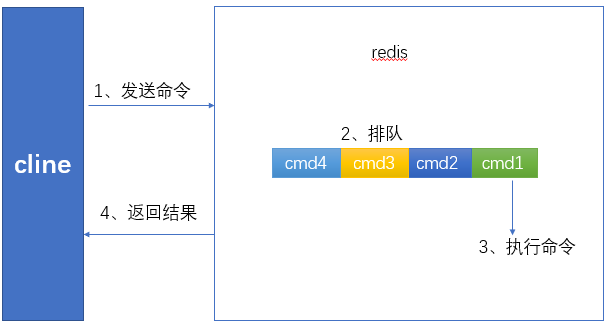
1、生命周期:
慢查询发送在生命周期的第三阶段,也就是执行命令阶段
客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素
2、l慢查询两个配置
slowlog-max-len:慢查询阀值(单位:微秒)
slowlog-log-slower-than=0,记录所有命令
slowlog-log-slower-than <0,不记录任何命令
''' 按照经验: 1 slowlog-max-len 不要设置过大,默认10ms,通常设置1ms 2 slowlog-log-slower-than不要设置过小,通常设置1000左右 '''
(1)配置方法:
#1 默认配置 config get slowlog-max-len=128 Config get slowly-log-slower-than=10000 # 2 修改配置文件,然后重启服务 #3 动态配置 # 设置记录所有命令 config set slowlog-log-slower-than 0 # 最多记录100条 config set slowlog-max-len 100 # 持久化到本地配置文件 config rewrite
(2)三个命令
slowlog get [n] #获取慢查询队列 ''' 日志由4个属性组成: 1)日志的标识id 2)发生的时间戳 3)命令耗时 4)执行的命令和参数 ''' slowlog len #获取慢查询队列长度 slowlog reset #清空慢查询队列
三、Bigmap位图
1、定义
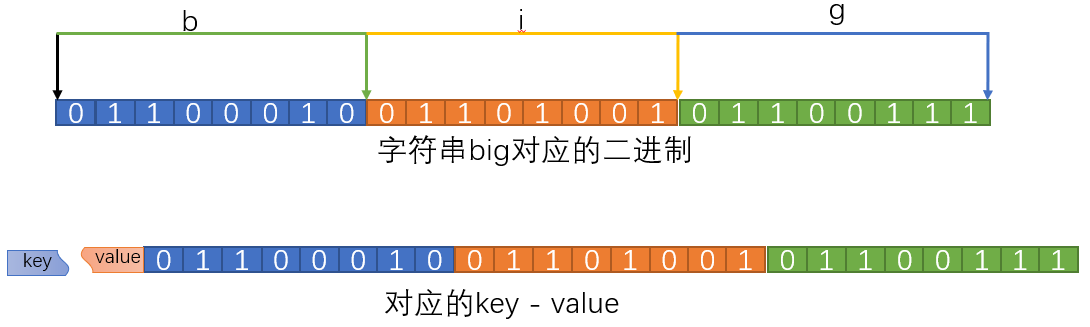
位图就是用每一个二进制位来存放或者标记某个元素对应的值。通常是用来判断某个数据存不存在的,因为是用bit为单位来存储所以Bitmap本身会极大的节省储存空间。
简单讲就是把string类型中value值转化成二进制
2、位图操作命令
set hello big #放入key位hello 值为big的字符串 getbit hello 0 #取位图的第0个位置,返回0 getbit hello 1 #取位图的第1个位置,返回1 如上图 ##我们可以直接操纵位 setbit key offset value #给位图指定索引设置值 setbit hello 7 1 #把hello的第7个位置设为1 这样,big就变成了cig setbit test 50 1 #test不存在,在key为test的value的第50位设为1,那其他位都以0补 bitcount key [start end] #获取位图指定范围(start到end,单位为字节,注意按字节一个字节8个bit为,如果不指定就是获取全部)位值为1的个数 bitop operation destkey key [key...] #做多个Bitmap的and(交集)/or(并集)/not(非)/xor(异或),操作并将结果保存在destkey中 BITOP AND destkey key [key ...] #对一个或多个 key 求逻辑并,并将结果保存到 destkey 。 BITOP OR destkey key [key ...] #对一个或多个 key 求逻辑或,并将结果保存到 destkey 。 BITOP XOR destkey key [key ...] #对一个或多个 key 求逻辑异或,并将结果保存到 destkey BITOP NOT destkey key #对给定 key 求逻辑非,并将结果保存到 destkey 。 #除了 NOT 操作之外,其他操作都可以接受一个或多个 key 作为输入。 # 例子 bitop and test3 test1 test2 #把test1和test2按位与操作,放到test3中 bitpos key targetBit start end #计算位图指定范围(start到end,单位为字节,如果不指定是获取全部)第一个偏移量对应的值等于targetBit的位置 bitpos test 1 #big 对应位图中第一个1的位置,在第二个位置上,由于从0开始返回1,也就是返回第一个1的位置 bitpos test 0 #big 对应位图中第一个0的位置,在第一个位置上,由于从0开始返回0 bitpos test 1 1 2 #返回9:返回从第一个字节到第二个字节之间 第一个1的位置,看上图,为9
3、独立用户统计
(1) 使用set和Bitmap对比
2 1亿用户,5千万独立(1亿用户量,约5千万人访问,统计活跃用户数量)
| 数据类型 | 每个userid占用空间 | 需要存储用户量 | 全部内存量 |
|---|---|---|---|
| set | 32位(假设userid是整形,占32位) | 5千万 | 32位*5千万=200MB |
| bitmap | 1位 | 1亿 | 1位*1亿=12.5MB |
假设有10万独立用户,使用位图还是占用12.5mb,使用set需要32位*1万=4MB
(2)位图也可以应用到打卡
一年打卡,也就365天,相当于365位,相当于46个字节左右,占用内存特别小
4 总结
(1) 位图类型是string类型,最大512M
(2)使用setbit时偏移量如果过大,会有较大消耗
(3) 位图不是绝对好用,需要合理使用
四、Geo地理空间位置
1、作用
存储经纬度,计算两地距离,范围等,主要应用场景:外卖、附近的人
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
2、常用命令
# 设置命令:geoadd key longitude(维度) latitude(经度) member(名字) #增加地理位置信息 127.0.0.1:6379> geoadd china:city 116.28 39.55 beijing #把北京地理信息天津到cities:locations中 127.0.0.1:6379> geoadd china:city 117.12 39.08 tianjin 127.0.0.1:6379> geoadd china:city 114.29 38.02 shijiazhuang 127.0.0.1:6379> geoadd china:city 115.29 38.51 baoding 118.01 39.38 tangshan # 获取命令:geopos key member #获取地理位置信息 127.0.0.1:6379> geopos china:city beijing #返回结果:1) 1) "116.28000229597092" # 维度 # 2) "39.550000724547083" #经度 ''' GEODIST key member1 member2 [unit] #默认unit是密 获取两个给定位置之间的值(最大误差是0.5%) 指定单位的参数 unit 必须是以下单位的其中一个: m 表示单位为米。 km 表示单位为千米。 mi 表示单位为英里。 ft 表示单位为英尺。 注意:计算出的距离会以双精度浮点数的形式被返回。 如果给定的位置元素不存在, 那么命令返回空值。 ''' 127.0.0.1:6379> geodist china:city beijing tianjin "89206.0576" 127.0.0.1:6379> geodist china:city beijing tianjin km "89.2061" 127.0.0.1:6379> geodist china:city beijing tianjin mi "55.4302" #获取指定位置范围内的位置元素 GEORADIUS key longitude(纬度) latitude(经度) radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] ''' WITHCOORD: 将位置元素的经度和维度也一起返回 WITHDIST: 将位置元素和中心之间的距离也返回,单位跟半径单位一样 WITHHASH:以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值 Count count: 获取前count个匹配元素 ''' # 返回(110,42)1000km里的位置元素 127.0.0.1:6379> georadius china:city 110 42 1000 km # 1) "shijiazhuang" # 2) "baoding" # 3) "beijing" 127.0.0.1:6379> georadius china:city 110 42 1000 km withdist #1) 1) "shijiazhuang" # 2) "573.8847" #距离 #2) 1) "baoding" # 2) "593.3522" #3) 1) "beijing" # 2) "594.8120" 127.0.0.1:6379> georadius china:city 110 42 1000 km withcoord withdist #1) 1) "shijiazhuang" # 2) "573.8847" # 3) 1) "114.29000169038773" # 2) "38.019999942510374" #2) 1) "baoding" # 2) "593.3522" # 3) 1) "115.28999894857407" # 2) "38.509999563427989" #3) 1) "beijing" # 2) "594.8120" # 3) 1) "116.28000229597092" # 2) "39.550000724547083" #获取返回的前2个元素 127.0.0.1:6379> georadius china:city 110 42 1000 km count 2 # 1) "shijiazhuang" # 2) "baoding" # 根据成员位置来查找指定半径范围的位置元素 GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] # 该命令与GEORADIUS区别:是用成员位置做中心点,而不是用经纬度,其他参数用法两者一样 127.0.0.1:6379> GEORADIUSBYMEMBER china:city beijing 100 km #1) "beijing" #2) "tianjin"
3、总结:
geo的本质是zset类型,可以用zset命令来删除元素
127.0.0.1:6379> zrem china:city tangshan
(integer) 1
五、HyperLogLog
1、介绍
HyperLogLog 是一种用来做基数统计的算法。它只会根据输入元素来计算基数,而不会储存输入元素本身,不会返回输入的各个元素
HyperLogLog 优点:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
扩展:基数就是不重复的元素,比如数据集 {1, 3, 5, 7, 5, 7, 8}, 它基数集为 {1, 3, 5 ,7, 8},基数就是5
应用场景:百万级别独立用户统计、网站用户访问统计
2、三个命令
#1、向key为变量名的HyperLoglog结构添加数据,可以添加一个或者多个 PFADD key element [element ...] #返回值是1,代表内部被修改了,0则没有修改 127.0.0.1:6379> pfadd log a b c d (integer) 1 # 2、计算变量名key的HyperLoglog结构体中的基数, # 如果key有多个,则求多个key的并集 PFCOUNT key [key ...]
127.0.0.1:6379> pfadd log a b c d #(integer) 1 127.0.0.1:6379> pfcount log #(integer) 4 127.0.0.1:6379> pfadd log1 a e f g #(integer) 1 127.0.0.1:6379> pfcount log log1 #(integer) 7 #3、 多个HyperLoglog合并成一个新的HyperLoglog结构体,相当于并集 PFMERGE destkey sourcekey [sourcekey ...] 127.0.0.1:6379> pfmerge log3 log log1 #OK 127.0.0.1:6379> pfcount log3 #(integer) 7