目录
1.三次作业思路
2.三次作业bug回顾
3.代码度量分析
4.踩过的坑
5.互测与对拍
一.作业思路整理
第一次作业
第一次作业比较简单,对表达式进行标准化处理,将幂函数系数和指数显式的表示出来,用正则提取后,再用hashmap存储幂函数的系数和指数即可(用hashmap存储每一项还可以合并同类项,让输出结果比较短,能够拿到不错的性能分)。
第二次作业
同第一次思路,标准化处理表达式,显式表示出每一项的三个指数和常系数,用正则提取,在存每一项时,我将幂指数、sin指数、cos指数封装到了一个类,并将这个类作为key,项的常系数作为value存入hashmap里边(需要重写这个类的哈希函数int hashCode()和相等性判定函数boolean equals(Object obj))
第三次作业
因为正则不支持自嵌套,导致这一次的作业的难点在于解析表达式,建立对象。

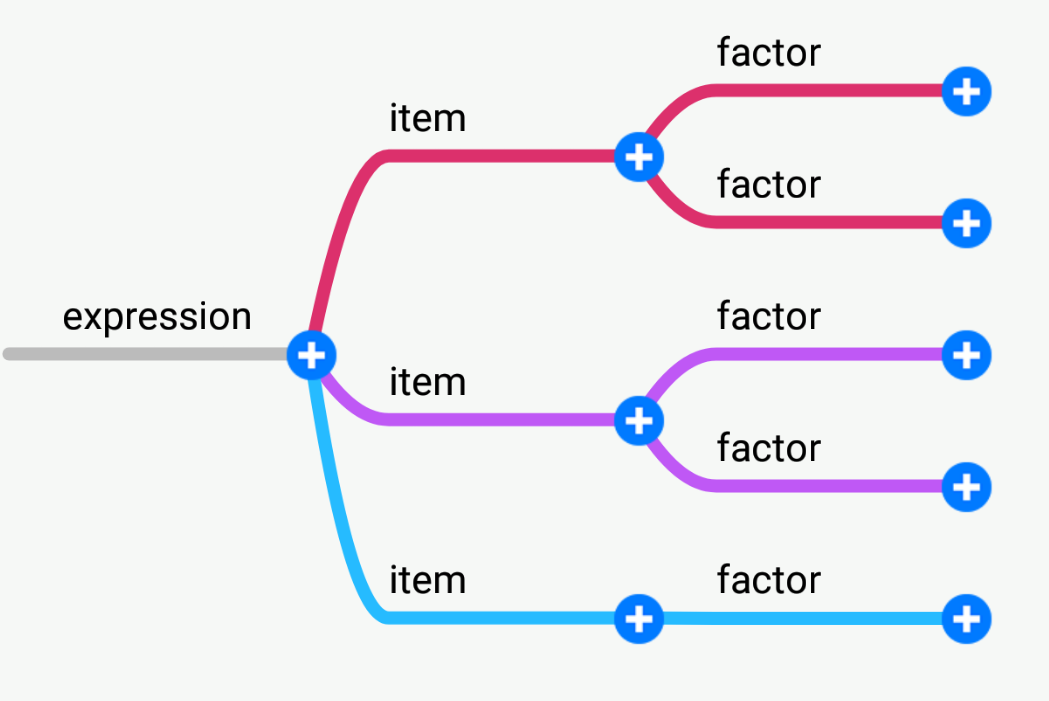
我的思路就是将输入字符串按照词法单元进行切割,存入列表中,从左到右读取切割后的单元。然后对表达式结构进行分层:expr层,item层,factor层,Num层(带符号整数层)
每一层只处理本层应该处理的词法单元:
Expr层处理的词法单元:[+, -]
Item层处理的词法单元:[+,-,*]
Factor层处理的词法单元:[x,^,sin,cos,(,)]
Num层处理的词法单元:[+,-,纯数字]
不可见字符被预处理掉了(不合法的不可见字符在预处理部分报错(WRONG FORMAT))
当遇到非本层应处理的词法单元时,要么进入下一层,要么报错(WRONG FORMAT!);同时在本层处理完毕以后,创建当前层对应的新对象,返回到上一层,存到上一层对象的列表中
这种思路即是即边解析边建立对象
解析无误,则说明输入字符串合法,对象也已建好;否则字符串非法
最后建好的对象构成了树形的结构:
每个类再提供求导和返回自身字符串这两个接口,最后通过链式求导即可得到最后结果
二.bug回顾
第一次作业Bug:
1.当前字符串为空串时,使用了charAt(0)来判断字符串首字符,导致程序直接崩掉。因此在使用charAt(index)方法时一定要保证index<string.lenth
第二次作业Bug:
1.表达式标准化时出错.
表达式是由若干项相加构成(减去一项可以视作加上负的该项,即该项常数系数乘上-1),而每一项可以表示成: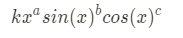
我的做法是将每一项的常系数k, 幂指数a,三角指数b、c显式的表示出来(某一因子不存在则其指数为0,指数省略不写的因子的指数还原为1),再通过正则提取出来。然而-x这种常系数为-1的项我没有处理成-1*x,导致该项常系数没提取出来,默认成了1,最后求导出错。
2.仍是表达式标准化的问题
在对x*x*x*x进行标准化时,我采用了replaceAll方法:

替换的结果是:

可以看到这样的处理并没有将字符串内的所有*x*转化成*x^1*,其实正则是从左到右匹配待替换字符串,当匹配到第一个*x*(第2个字符到第4个字符)时,替换,接着会直接从第五个字符x(上一次成功匹配末尾的下一个字符)开始继续匹配,自然也就匹配不到第二个*x*
这样会导致后续我提取到的x的指数为3,跟着求导就错了,这一Bug显然是由于对replaceAll替换机制的不了解而引发的惨案
3.优化出错.

当出现x^+1*x时会优化成x^+x,然后GG.
第三次作业Bug
1.解析表达式超时
解析表达式采用了有限状态机的方法,没有采用递归下降,导致在解析sin((((((((((((((((x))))))))))))))))这种多层括号嵌套的情况时巨慢无比,超时挂掉。
2.优化炸掉
在优化sin((x-x))^1这类表达式时,先把(x-x)优化成(0),然后就把sin((0))优化成了0,最后输出0^1这种非法的输出
二.代码度量分析
借用了YuQianmian同学博客里对代码复杂度的解释(https://www.cnblogs.com/qianmianyu/p/8698557.html)

第一次作业:
类图:

代码复杂度:
第二次作业:
类图:
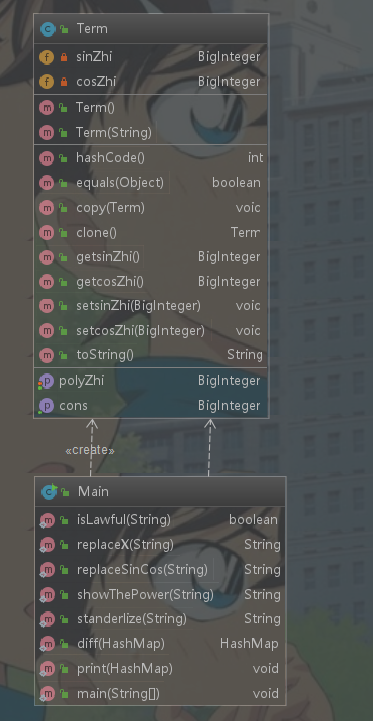
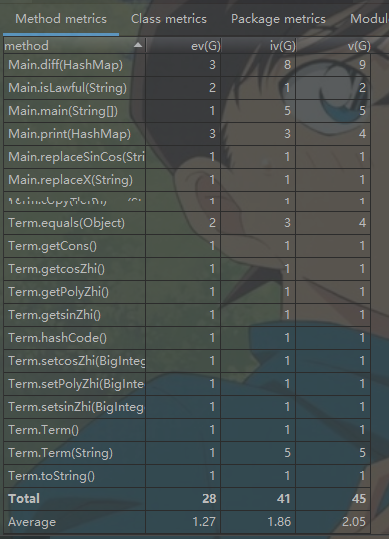
代码复杂度:
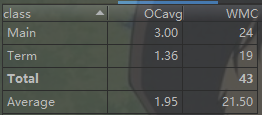
第三次作业:
类图:
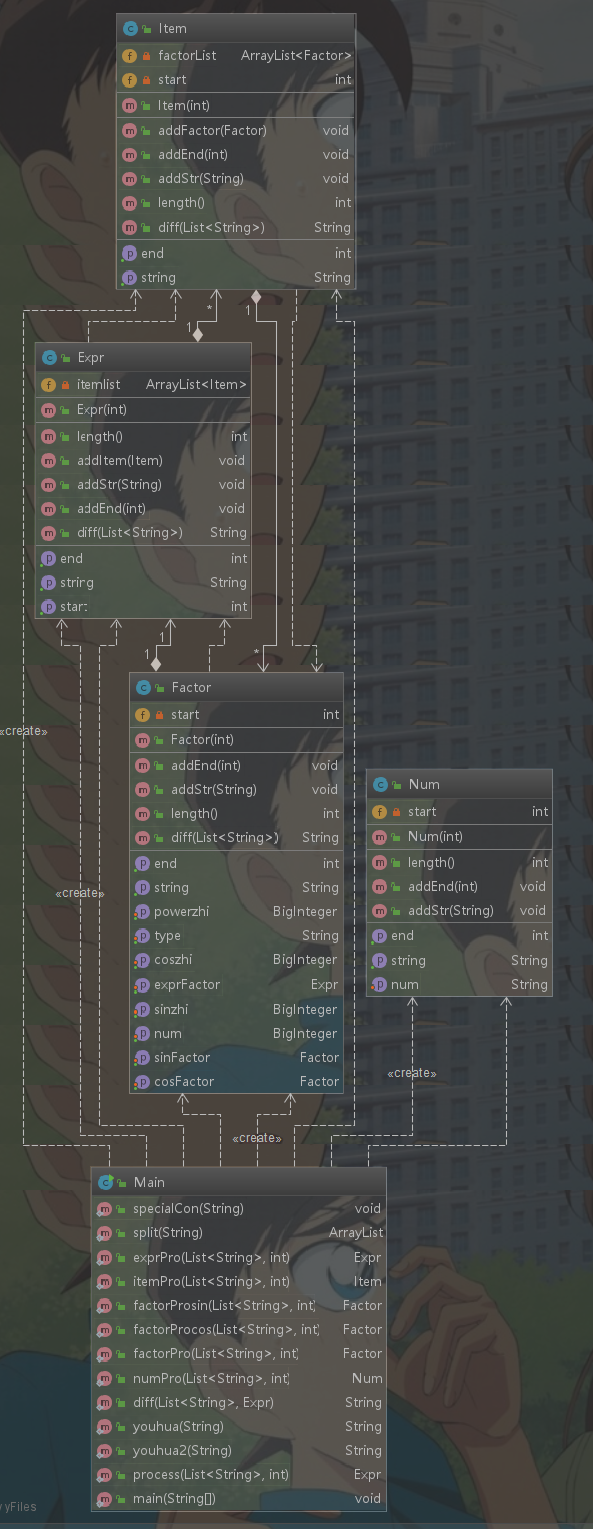
代码复杂度:
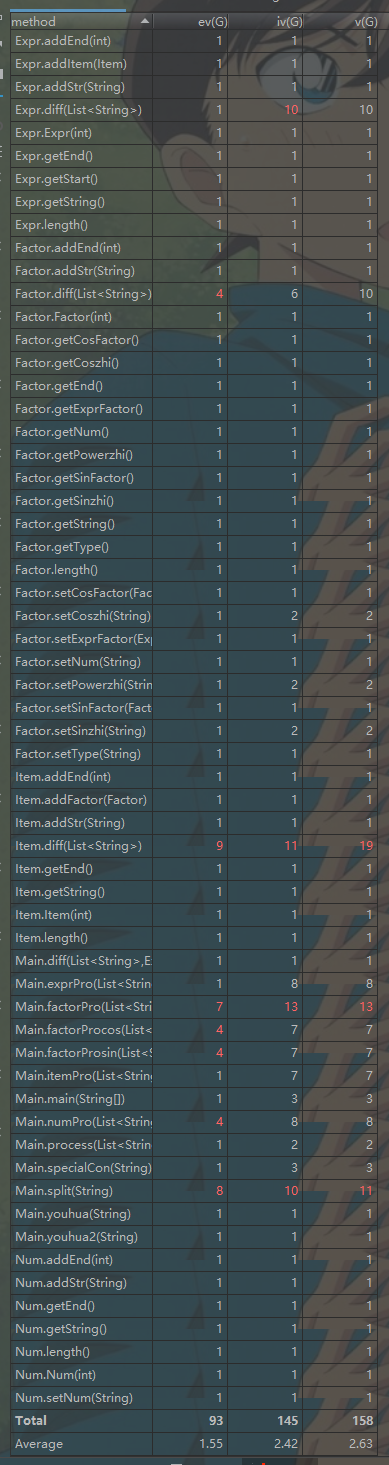
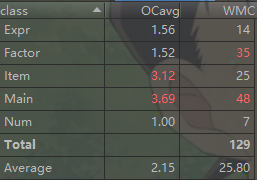
度量分析
前两次作业较简单,在此就分析第三次作业的代码.
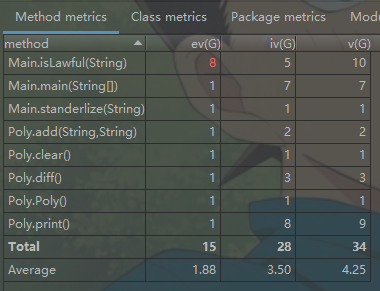
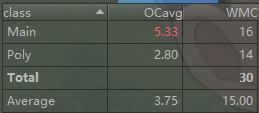
1.第三次作业我采用了分层有限状态机的方法来做,并且把对表达式进行词法单元切割、初步合法性检验、解析表达式时对各层进行处理的方法、优化输出的方法都写到了main类里边,导致了main类代码过长,可读性较差。
2.采用了状态机的方法来做,其实就很不面向对象,很面向过程,其中用到了很多的if_else控制流语句,直接导致好多方法的各项复杂度都偏高,Main类的两项复杂度指标都偏高。
3.item类的diff方法其实加入了优化,导致代码有点冗长,没有将item类的diff和优化分开来做,导致OCavg值偏高。
4.Factor类WMC指标偏高的原因是内部控制流语句偏多,因为我只定义了一个大的Factor类,将各种因子可能要存的信息都存在了大类里边,然后存了变量type来表明因子的种类。因此判断因子种类时用到了较多控制流语句
三.踩过的坑
1.replaceAll的匹配机制不够清楚,详见第二次作业Bug
2.charAt(index)没有事先检验index<string.length,导致程序报错崩掉
3.可变类间用"=="来比其实比较的是类的引用;
4.可变类的赋值"="其实传的是引用.
有时候自己本来想新创建一个对象,想对新对象进行操作,忘了"="传的是引用,导致了对已有的对象进行操作。
eg:Biginteger n1=n2;(n2是已创建的Biginteger对象) //Then Operate n1,balabala...// 并没有达到新创建Biginteger对象的目的
四.互测与对拍
随着代码规模的不断扩大,通过阅读别人代码来发现Bug的效率变得非常低,因此更多的时候我会采用对拍的方式自动化测试,在对拍发现了别人的Bug时再手动分析Bug类型。这样自动化对拍+手动分析bug的方式效果也是非常显著。这种测试策略与待测代码结构无关,但是测试的效果严重依赖于你构造的输入数据(比如我对拍中所用到的MakeData.jar),如果构造的输入数据不够全面,类型不都多,那么很可能会遗漏特定的Bug
eg:你构造的输入的表达式长度限定在50以内,那么就无法覆盖“采用大正则解析过长表达式而导致的爆栈问题”的Bug
所以最好在测试时采用自动划测试+手动构造边界数据测试的策略,这样效果应该会更好些
bat脚本代码:
:loop
%makeData.jar用于产生输入数据,输出到当前文件夹下的in.txt%
%makeData.jar需要自己写产生输入数据的java文件,然后导出jar包%
makeData.jar
%从Altergo工程里导出jar文件,运行jar文件,求导后的表达式就输出到了Altergoout.txt%
java -jar Altergo.jar < in.txt > Altergoout.txt
%calmy.exe是pyinstaller打包python程序后所得的可执行程序,带入x=2计算求导后表达式的值,输出到Altergoans.txt%
calmy.exe < Altergoout.txt > Altergoans.txt
java -jar OO_homework_1.jar < in.txt > myout.txt
calmy.exe < myout.txt >myans.txt
%比较Altergo和我的结果,若一样则回到loop标签处,继续循环;若不一样则打印不同之处,结束程序%
fc /A Altergoans.txt myans.txt
if not errorlevel 1 goto loop
pause
:end
calmy.py源码:
from sympy import *
x=Symbol("x")
s=input()
s=s.replace("^","**")
try:
s=simplify(s)
num=round(s.evalf(subs={x:2}),2)
print(num)
except:
print("WRONG FORMAT!")
jar文件的生成
下载了别人的源码以后,可以通过IDEA导出jar包,具体参见:https://www.cnblogs.com/sonofelice/p/7098520.html
五.Applying Creational Pattern
前两次作业都比较简单,谈不上太多的设计模式。第3次作业难度和复杂度都有了质的上升, 比如factor类其实就可以通过继承来创建sin、cos、幂函数、常数因子四种子类,然后可以用接口来定义每个树节点都会用的几个方法

虽然我没这样做orz,不过要是重构的话大体就按这样的思路来做了