(一)什么是B-Tree、B+Tree、B*Tree?what?
(1)B-Tree
1.0 是一种多路搜索树(并不是二叉的)
①任意非叶子节点最多有M个儿子;且M>2;
②根结点的儿子数为[2,M];
③除根结点以外的非叶子结点的儿子数为[M/2, M];
④每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
⑤非叶子结点的关键字个数=指向儿子的指针个数-1;
⑥非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
⑦非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
⑧所有叶子结点位于同一层; eg:M=3
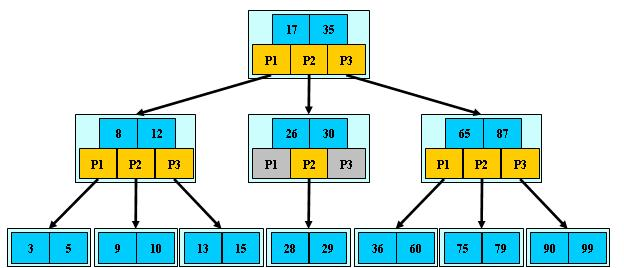
2.0 B-tree的特性:
①关键字集合分步在整棵树中;
②任何一个关键字出现且只出现在一个节点中;
③搜索有可能在非叶子结点结束;
④其搜索性能等价于在关键字全集内做一次二分查找;
⑤自动层次控制;
B-tree搜索,从根结点开始--->对结点内的关键字(有序)序列进行二分查找,如果命中则结束;否则进入关键字所属范围的儿子结点。重复,直到所对应的儿子指针为空,或已经是叶子结点。
(2)B+Tree
1.0 是B-Tree的变体,也是一种多路搜索树;
定义基本与B-Tree同,除了:
①非叶子结点的 子树指针=关键字数相同;
②非叶子结点的子树指针P[i],指向关键字值属于 [K[i], K[i+1]) 的子树(B-树是开区间);
③ 为所有叶子结点增加一个链指针;
④所有关键字都在叶子结点出现; eg:(M=3)
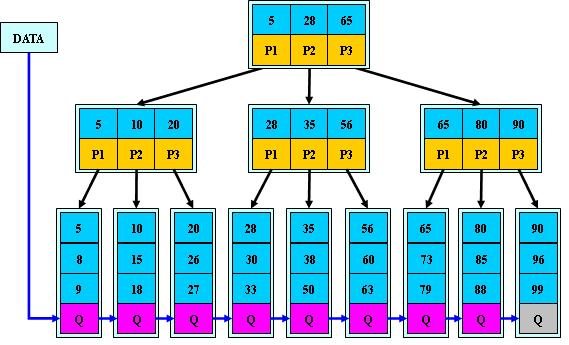
2.0 B+tree树的特性:
①所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
②不可能在非叶子结点命中;
③非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于存储(关键字)数据的数据层;
④更适合文件索引系统;
(3) B*Tree
1.0 是B+Tree的变体,在B+Tree的非根和非叶子结点再增加指向兄弟的指针;
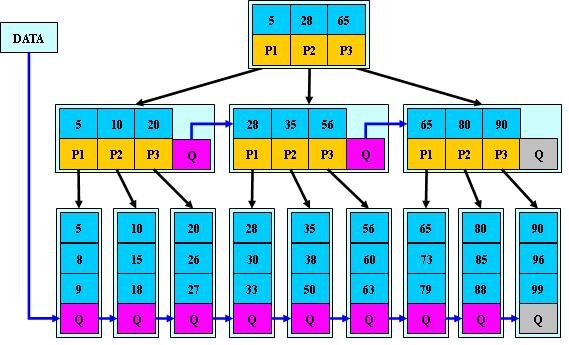
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3
(代替B+树的1/2);
4.0 为什么选用B+/-Tree
①一般来说,索引本身也很大,不可能全部存储在内存中---->因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
②简单点说说内存读取,内存是由一系列的存储单元组成的,每个存储单元存储固定大小的数据,且有一个唯一地址。当需要读内存时,将地址信号放到地址总线上传给内存,内存解析信号并定位到存储单元,然后把该存储单元上的数据放到数据总线上,回传。
③写内存时,系统将要写入的数据和单元地址分别放到数据总线和地址总线上,内存读取两个总线的内容,做相应的写操作。
④内存存取效率,跟次数有关【跟顺序无关】,先读取A数据还是后读取A数据不会影响存取效率。
而磁盘存取就不一样了,磁盘I/O涉及机械操作。磁盘是由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘须同时转动)。磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不动,磁盘转动,但磁臂可以前后动,用于读取不同磁道上的数据。磁道就是以盘片为中心划分出来的一系列同心环(如图标红那圈)。磁道又划分为一个个小段,叫扇区,是磁盘的最小存储单元。
磁盘读取时,系统将数据逻辑地址传给磁盘,磁盘的控制电路会解析出物理地址,即哪个磁道哪个扇区。于是磁头需要前后移动到对应的磁道,消耗的时间叫寻道时间,然后磁盘旋转将对应的扇区转到磁头下,消耗的时间叫旋转时间。所以,适当的操作顺序和数据存放可以减少寻道时间和旋转时间。
为了尽量减少I/O操作,磁盘读取每次都会预读,大小通常为页的整数倍。即使只需要读取一个字节,磁盘也会读取一页的数据(通常为4K)放入内存,内存与磁盘以页为单位交换数据。因为局部性原理认为,通常一个数据被用到,其附近的数据也会立马被用到。
B-Tree:如果一次检索需要访问4个节点,数据库系统设计者利用磁盘预读原理,把节点的大小设计为一个页,那读取一个节点只需要一次I/O操作,完成这次检索操作,最多需要3次I/O(根节点常驻内存)。数据记录越小,每个节点存放的数据就越多,树的高度也就越小,I/O操作就少了,检索效率也就上去了。
B+Tree:非叶子节点只存key,大大滴减少了非叶子节点的大小,那么每个节点就可以存放更多的记录,树更矮了,I/O操作更少了。所以B+Tree拥有更好的性能。