一直想整个爬虫玩玩,之前用Java试过...的确是术业有专攻啊,Python写起爬虫来更加方便
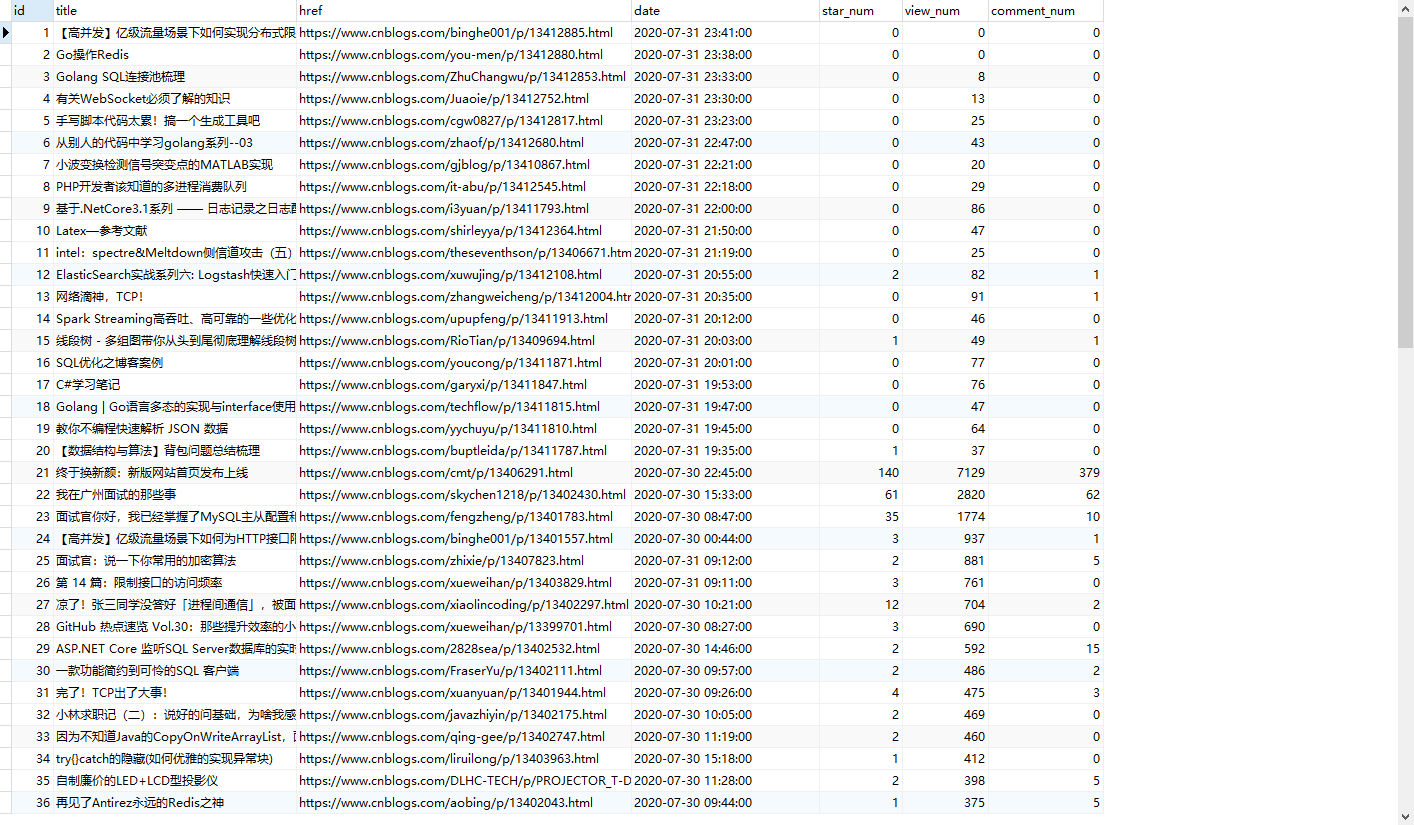
今天的成果:
main文件
主要的方法都封装在了spider-cnblogs里了,这里主要传递一个url,待会代码贴在后边

spider-cnblogs
大致的思路是这样的,先用requests发送请求,然后使用BeautifulSoup进行html解析,(推荐使用CSS选择器的方式获取想要的内容),解析完成后持久化到数据库,这里使用了阿里云的ECS,里面安装了一个MySQL。
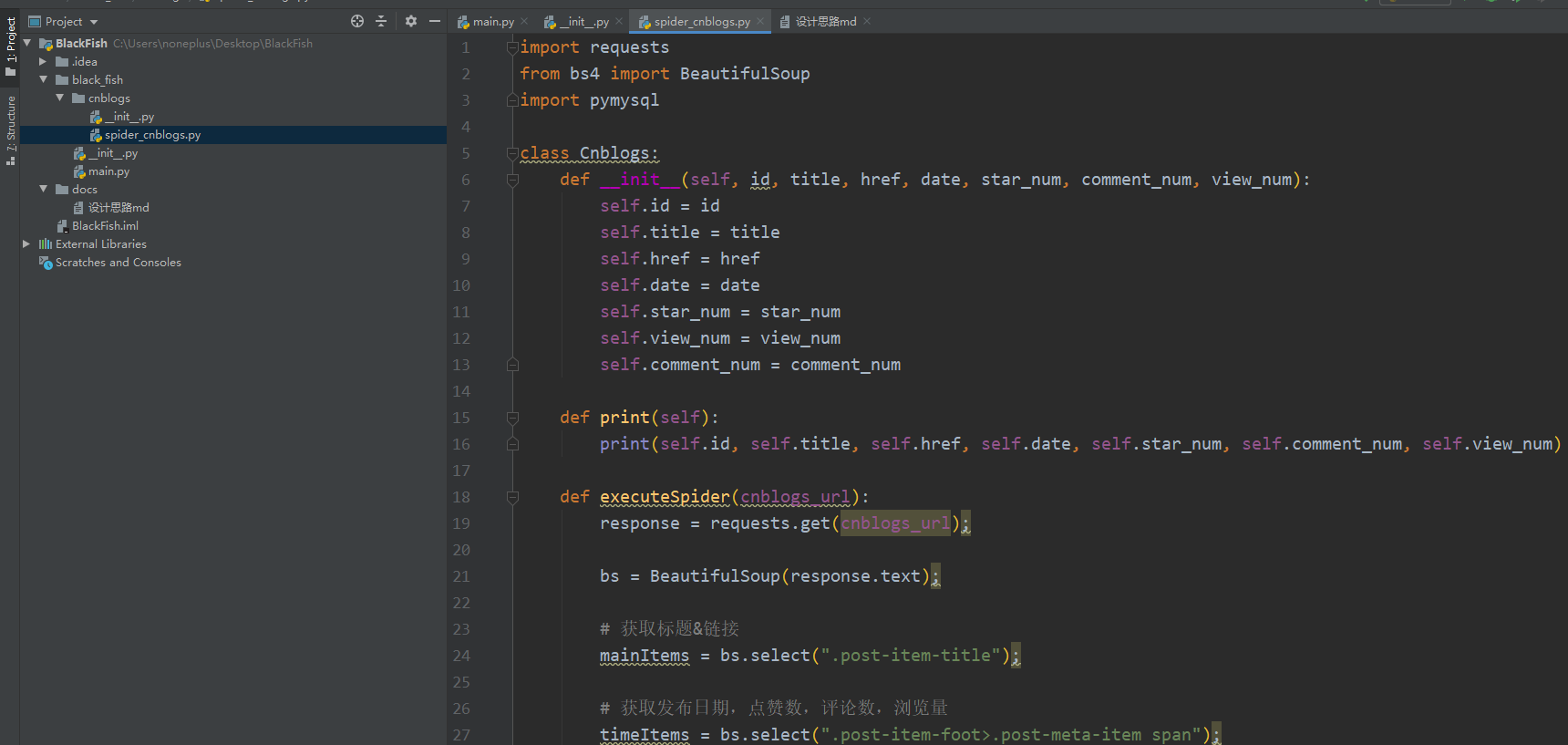
代码
main.py
from black_fish.cnblogs.spider_cnblogs import Cnblogs
if __name__ == '__main__':
# index,48,候选
Cnblogs.executeSpider("https://www.cnblogs.com")
Cnblogs.executeSpider("https://www.cnblogs.com/aggsite/topviews")
Cnblogs.executeSpider("https://www.cnblogs.com/candidate/")
spider-cnblogs
import requests
from bs4 import BeautifulSoup
import pymysql
class Cnblogs:
def __init__(self, id, title, href, date, star_num, comment_num, view_num):
self.id = id
self.title = title
self.href = href
self.date = date
self.star_num = star_num
self.view_num = view_num
self.comment_num = comment_num
def print(self):
print(self.id, self.title, self.href, self.date, self.star_num, self.comment_num, self.view_num)
def executeSpider(cnblogs_url):
response = requests.get(cnblogs_url);
bs = BeautifulSoup(response.text);
# 获取标题&链接
mainItems = bs.select(".post-item-title");
# 获取发布日期,点赞数,评论数,浏览量
timeItems = bs.select(".post-item-foot>.post-meta-item span");
t_list = []
for t_index, timeItem in enumerate(timeItems):
t_list.append(timeItem.string)
db = pymysql.connect("47.103.6.247", "username", "password", "black_fish_db")
cursor = db.cursor()
sql = "insert into cnblogs(title, href, date, star_num, comment_num, view_num) value(%s,%s,%s,%s,%s,%s)"
for m_index, main_item in enumerate(mainItems):
cnblog = Cnblogs(0, main_item.string, main_item.attrs['href'],
t_list[m_index * 4], int(t_list[m_index * 4 + 1]), int(t_list[m_index * 4 + 2]),
int(t_list[m_index * 4 + 3]))
val = (cnblog.title, cnblog.href, cnblog.date, cnblog.star_num, cnblog.comment_num, cnblog.view_num)
print(val)
cursor.execute(sql, val)
db.commit()
db.close()