最近有学员给出一段令人匪夷所思的JavaScript代码(据说是某某大厂面试题),废话少说,上代码:
var a = 10; { a = 99; function a() { } a = 30; } console.log(a);
这段代码运行结果是99,也就是说,a = 99将a的值重新设为99,而由于后面使用a定义了一个函数,a = 30其实是修改的a函数,或者干脆说,函数a将变量a覆盖了,所以在a函数的后面再也无法修改变量a的值了,因为变量a已经不存在了,ok,这段代码的输出结果好像可以解释得通,下面再看一段代码:
var a = 10; { function hello() { a = 99; function a() { } a = 30; } hello(); } console.log(a);
大家可以猜猜,这段代码会输出什么结果呢?10?99?30?,答案是10。也就是说,hello函数压根就没有修改全局变量a 值,那么这是为什么呢?
根据我们前面的结论,当执行到a = 99时,覆盖变量a的值,然后执行函数a的定义代码,接下来执行a = 30,将函数a改成了变量a,这个解释似乎也没什么问题,但是,问题就是,与第1段代码的输出不一样。第1段代码修改了全局变量a的值,第2段代码没有修改全局变量a的值,这是为什么呢?
现在思考3分钟........
其实吧,别看这道题很简单,可能有很多程序员都能蒙对答案,反正就这几种可能,一共就3个数,蒙对的可能性是33.3333%,但如果让你详细解释其中的原因呢?这恐怕没有多少程序员能清楚地解释其中的原理,现在就让我来给出一个天衣无缝的解答:
尽管前面给出的两段代码并不复杂,但这里面隐藏的信息量相当的大。在正式解答之前,先给出一些知识点:
1. 执行级代码块和非执行级代码块
这里介绍一下两种代码块的区别:
执行级代码块,顾名思义,就是在定义代码块的同时就执行了,看下面的代码:
{ var a = 1; var b = 2; console.log(a + b); }
这段代码,在解析的同时就会执行,输出3。
而非执行级代码块,就是在定义时不执行,只有在调用时才执行,很显然,函数代码块属于非执行级代码块,案例如下:
function add() { var a = 1; var b = 2; console.log(a + b); }
如果给执行级代码块套上一个函数头,就成了上面的样子,如果只有add函数,函数体是永远也不会执行的,除非使用下面的代码调用add函数。
add();
那么这两种代码块有什么区别呢?先看他们的区别:
1. 执行级代码块中的变量和函数自动提升作用域
2. 如果有局部符号,执行级代码块会优先进行作用域提升,而非执行级代码块,会优先考虑局部符号
估计刚看到这两点区别,很多同学有点懵,下面我就来挨个解释下。
(1)执行级代码块中的变量和函数自动提升作用域
先给出一个例子:
{ var a = 1; var b = 2; function sub() { return a - b } } console.log(a + b); // 输出3 console.log(sub()); // 输出-1
在这段代码中,a和b都使用了var声明变量,说明这两个变量是块的局部变量,那么为什么在块外面还能访问呢?这就是执行级代码块的作用域提升。如果在块外有同名的符号,需要注意如下几点:
符号只有用var定义的变量和函数可以被覆盖,类和用let、const定义的变量不能被覆盖,会出现重复声明的异常。代码如下:
var a = 14; function b() { } { var a = 1; var b = 2; function sub() { return a - b } } console.log(a + b); // 输出3 console.log(sub()) // 输出-1
很明显,全局变量a和全局函数b被块内部的a和b覆盖了,所以输出的结果还是3和-1。
let a = 14; class b{} { var a = 1; var b = 2; function sub() { return a - b } } console.log(a + b); console.log(sub())
执行这段代码,会抛出如下图所示的异常:
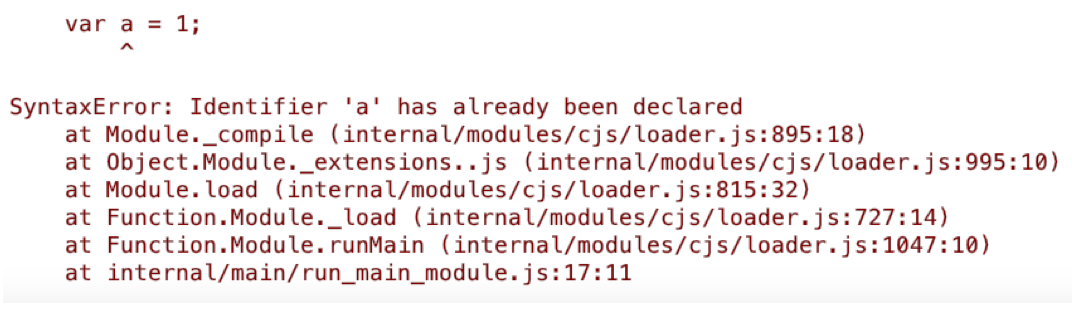
这说明用let声明的变量已经被锁死在顶层作用域中,不可被其他作用域的变量替换。如果将let a = 14注释掉,会抛出如下图的异常:
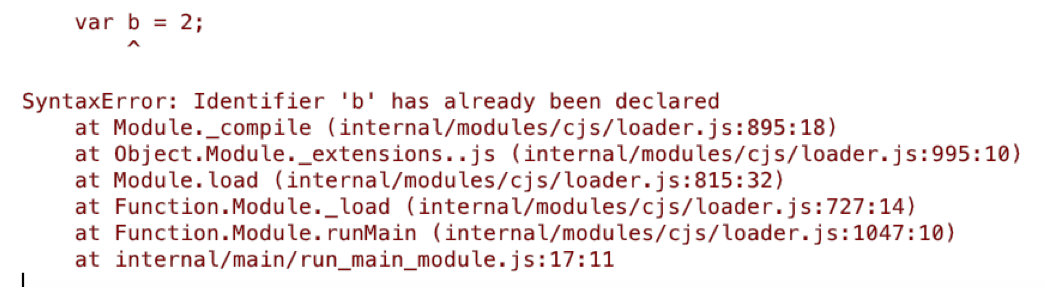
这说明类b也被锁死在顶层作用域中,不可被其他作用域的变量替换。
相对于可执行级代码块,非可执行级代码块就不会进行作用域提升,看如下代码:
function myfun() { var a = 1; var b = 2; } console.log(a + b);
执行这段代码,会抛出如下图的异常:

很明显,是变量a没有定义。
(2)如果有局部符号,执行级代码块会优先进行作用域提升,而非执行级代码块,会优先考虑局部符号,看下面的解释。
先上代码:
执行级代码块
var a = 100 { a = 10; function a() { } a = 20; } console.log(a); // 输出10
非执行级代码块
var a = 100 { function hello() { a = 10; function a() { } a = 20; } hello(); } console.log(a); // 输出100
这两段代码,前面的修改了变量a,输出10,后面的没有修改变量a,输出100,这是为什么呢?
这是由于执行级代码块会优先进行作用域提升,先看第1段代码,按着规则,会优先用块中的a覆盖全局变量a,所以a就变成10了。然后声明了a函数,所以a = 20其实是覆盖了局部函数a。其实这个解释咋一看没什么问题,不过仔细推敲,还是有很多漏洞。例如,既然a = 10优先提升作用域,难道a = 20就不能优先提升作用域吗?将 a = 10覆盖,变成20,为什么最后输出的结果还是10呢?函数a难道不会提升作用域,将变量a覆盖吗?这些疑问会在后面一一解开。
再看第2段代码,非执行级代码块会优先考虑局部变量,所以hello函数中的a会将函数a覆盖,而不是全局变量a覆盖,所以hello函数中的两次对a赋值,都是处理的局部符号a,而不是全局符号a。这个解释咋一看也没啥问题,但仔细推敲,也会有一些无法解释的。例如,a = 10是在函数a前面的语句,为啥会考虑在a = 10后面定义的函数a呢?这些疑问会在后面一一解开。
2. 多遍扫描
什么叫多遍扫描呢?这里的扫描指的是对JavaScript源代码进行扫描。因为你要运行JavaScript代码,肯定是要扫描JavaScript文件的所有内容的。不过不同类型的编程语言,扫描的次数不同。对于动态语言(如JavaScript、Python、PHP等),至少要扫描一遍(这句话当我没说,肯定要至少扫描一遍,否则要执行空气吗!),对于静态编程语言(如Java、C#,C++),至少要扫描2遍,通常是3遍以上。关于静态语言的分析问题,以后再写文章描述。这里主要讨论动态语言。
早期的动态语言(如ASP),通常会扫描一遍,但现在很多动态语言(如JavaScript、Python等),都是至少扫描2遍。现在先看看扫描1遍和扫描2遍有啥区别。
先看看在什么情况下只需要扫描1遍:
对于函数、类等语法元素与定义顺序有关的语言就只需要扫描1遍。那么什么是与定义顺序有关呢?也就是说,在使用某个函数、类之前必须定义,或者说,函数、类必须在使用前定义。例如,下面的代码是合法的。
function hello() { } hello()
这是因为hello函数在使用之前就定义了。而下面的代码在运行时会抛出异常。这是因为在调用hello函数之前没有定义hello函数。
hello() // hello函数是在使用之后定义的 function hello() { }
那么在什么情况下需要至少扫描2遍呢?
对于函数、类等语法元素与定义顺序无关的语言必须至少扫描2遍。这是因为第1遍需要确定语法元素(函数、类等)的定义,第2遍才是使用这些语法元素。经过测试,JavaScript的代码是与定义顺序无关的,也就是说,下面的代码可以正常运行:
hello() function hello() { }
很显然,JavaScript解析器至少对代码扫描了2次。对于动态语言(如JavaScript),通常是一边扫描一边执行的(并不像Java这样的静态语言,扫描时并不执行,直到生成.class文件后才通过JVM执行)。一般第1遍负责执行定义代码(如定义函数、类等),第2遍负责执行其他代码。现在就让我们看看JavaScript的这2遍扫描都做了什么。
先给出结论:JavaScript的第1遍扫描只处理函数和类定义(当然,还有可能处理其他的定义,但本文只讨论函数和类),JavaScript的第2遍扫描负责处理其他代码。但函数和类的处理方式是不同的(见后面的解释)。
结论是给出了,下面给出支持这个结论的证据:
看下面的代码:
hello() function hello() { console.log('hello') }
执行这段代码,会输出hello。很明显,hello函数在调用之后定义。由于读取文件,是顺序进行的,所以如果只扫描一遍代码,在调用hello函数时不可能知道hello函数的存在。因此,唯一的解释就是扫描了2遍。第1遍,先扫描hello函数的定义部分,然后将hello函数的定义保存到当前作用域的符号表中。第2次扫描,调用hello函数时,就会到当前作用域的符号表查询是否存在函数hello,如果存在,调用,不存在,则抛出异常。
那么在第1遍扫描时,处理类和函数的规则是否相同呢?先看下面的代码:
var h = new hello(); // 抛出异常 class hello { }
在运行这段代码时会抛出如下图所示的异常。

从这个异常来看,hello类似乎在第1遍扫描中没处理,将hello类的定义放到最前面就可以了,代码如下:
class hello { } var h = new hello(); // 正常创建类的实例
现在看下面的代码:
var p1 = 10 { p1 = 40; class p1{} p1 = 50; }
执行这段代码,会抛出如下图的异常:

很明显,错误指向了p1 = 40,而不是class p1{}。假设第1遍扫描没有处理类p1,那么的2遍扫描肯定是按顺序执行的,就算出错,也应该是class p1{}的位置,那么为何是p1 = 40的位置呢?元芳你怎么看!
元芳:唯一的合理解释就是在第2遍扫描到p1 = 40时,JavaScript解析器已经知道了p1的存在,这就是p1类。那么p1类肯定是在第1遍处理了,只是处理方法与函数不同,只是将p1类作为符号保存到符号表中,在使用p1类时并没有检测当前作用域的符号表,因此,只能在使用类前定义这个类。由于这个规则限制的比较严,所以不排除以后JavaScript升级时支持与位置无关的类定义,但至少现在不行。
这就是在第1遍扫描时函数与类的处理方式。
在第2遍扫描就会按部就班执行其他代码了,这一点在以后分析,下面先看其他知识点。
3. 下面哪段代码会抛出异常
先来做这道题:
第1段代码:
var a = 99; function a() { } console.log(a)
第2段代码:
{ var a = 99; function a() { } console.log(a) }
第3段代码:
{ a = 99; function a() { } console.log(a) }
第4段代码:
function hello() { var a = 99; function a() { } console.log(a) } hello();
现在思考3分钟......
答案是第2段代码会抛出如下图的异常,其他3段代码都正常执行,并输出正确的结果。
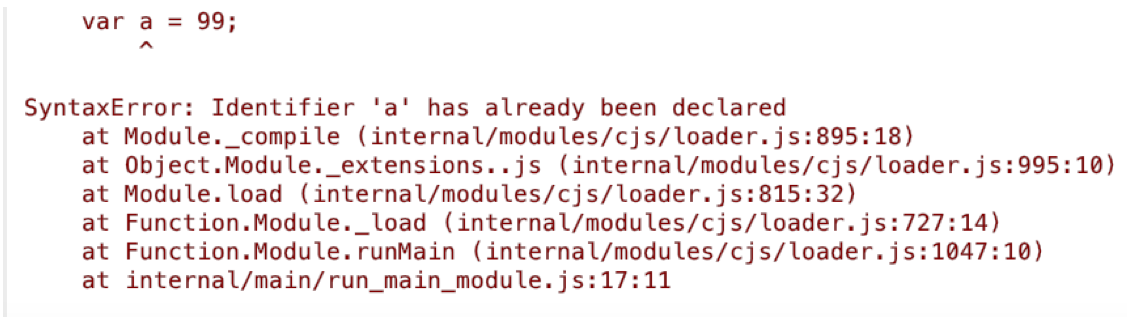
那么这是为什么呢?
先来解释第1段代码:
var a = 99; function a() { } console.log(a)
在这段代码中,变量a和函数a都位于顶级作用域中,所以就不存在提升作用域的问题了。当第1遍扫描时,函数a被保存到符号表中。第2遍扫描时,执行到var a = 99时,会发现函数a已经在当前作用域了,所以在同一个作用域中,后面处理的符号会覆盖前面的同名符号,所以函数a就被变量a覆盖了。因此,会输出99。
现在来解释第4段代码:
function hello() { var a = 99; function a() { } console.log(a) } hello();
第1遍扫描,hello函数和a函数都保存到当前作用域的符号表中了(这两个函数在不同的作用域)。第2遍扫描,执行var a = 99时,由于这是非执行级代码块,所以不存在作用域提升的问题。而且变量a用var声明,就说明这是hello函数的局部变量,而函数a已经在第1遍扫描中获得了,所以在执行到var a = 99时,js解析器已经知道了函数a的存在,由于变量a和函数a都在同一个作用域,所以可以覆盖。因此,这段代码也输出99。
接下来看第2段和第3段代码:
第2段代码
{ var a = 99; // 抛出异常 function a() { } console.log(a) }
第3段代码
{ a = 99; // 正常执行 function a() { } console.log(a) }
这两段代码的唯一区别是a是否使用了var定义。这就要根据执行级代码块的规则了。
1. 定义变量使用var。如果发现块内有同名函数或类定义,会抛出重定义异常
2. 未使用var定义变量。遇到同名函数,函数将被永久覆盖,如果遇到同名类,会抛出如下异常:
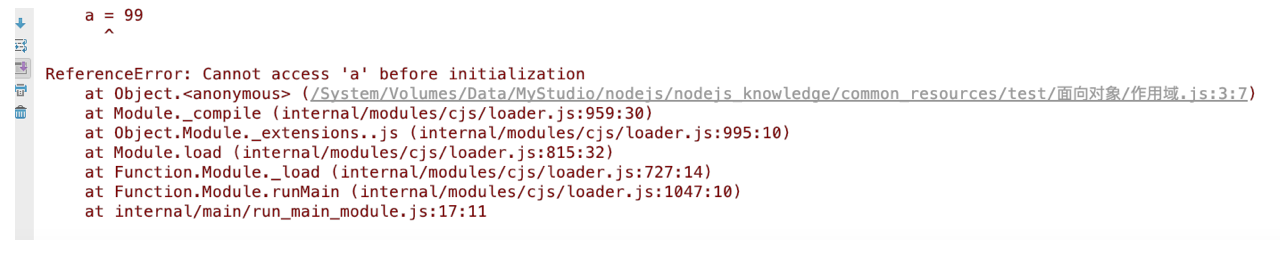
估计是JavaScript的规范比较乱,而且Class是后来加的,规则没定好,本来类和函数应该有同样的效果的,结果....,这就是js的代码容易让人发狂的原因。在Java、C#中是绝对不会有这种情况发生的。
好了,该分析的都分析了,现在就来具体分析下本文刚开始的代码吧。
第1遍扫描:
var a = 10; // 不处理 { a = 99; // 不处理 function a() { // 提升作用域到顶层作用域 } a = 30; // 不处理 } console.log(a); // 不处理
到现在为止,第1遍扫描结束,得到的结果只是在顶级作用域中添加了一个函数a。
第2遍扫描:
// 在第2遍扫描时,其实已经发现在第1遍扫描中存在一个顶层的函数a(作用域被提升的),所以这个变量a其实是覆盖了第1遍扫描时的a函数 // 所以说,不是函数a覆盖了变量a,而是变量a覆盖了函数a。也就是说,当执行到这时,函数a已经被干掉了,以后再也没函数a什么事了 var a = 10; { a = 99; // 提升作用域,将a的值设为99,在这时还没有局部函数a呢! // 在第2遍扫描时仍然处理,由于第1遍扫描,只扫描函数,所以是没有顶级变量a的,因此,会将函数a提升到顶级作用域 // 而第2遍扫描,由于存在顶级变量a,所以这个函数a会作为局部函数处理,这是执行级代码块的规则 function a() { } a = 30; // 实际上替换的是局部函数a } console.log(a); // 第2遍执行这条语句,输出99
第2遍扫描结束,执行console.log(a)后会输出99。
现在看另外一段代码:
第1遍扫描:
var a = 10; // 不处理 { function hello() { // 提升到顶级作用域 a = 99; // 不处理 function a() { // 添加到hello函数作用域的符号表中 } a = 30; // 不处理 } hello(); // 不处理 } console.log(a); // 不处理
第2遍扫描:
var a = 10; // 定义顶层变量a { function hello() { // 提升到顶级作用域 a = 99; // 如果是非执行级代码块,会优先考虑局部同名符号,如局部函数a,因此,这里实际上覆盖的是函数a,而不是全局变量10 function a() { // 在非执行级代码块中,只在第1遍扫描中处理内嵌函数,第2遍扫描不处理,所以这是函数a已经被a=99覆盖了 } a = 30; // 覆盖a = 99 在hello函数内部,a的最终值是30 } hello(); // 执行 } console.log(a); // 输出10
好了,现在大家清楚为什么最开始给出的两段代码,一个修改了全局变量a,一个没修改全局变量a的原因了吧。就是可执行级代码块和非可执行级代码块在处理作用域提升问题上的差异造成的。其实这么多编程语言,只有JavaScript有这些问题,这也是js太灵活导致的,这就是要自由而付出的代价:让某些程序的执行结果难以琢磨!
