. 词法分析
1.1 词法记号及属性
词法记号、模式、词法单元
记号名 词法单元列举 模式的非形式描述
if if 字符i,f
for for 字符f,o,r
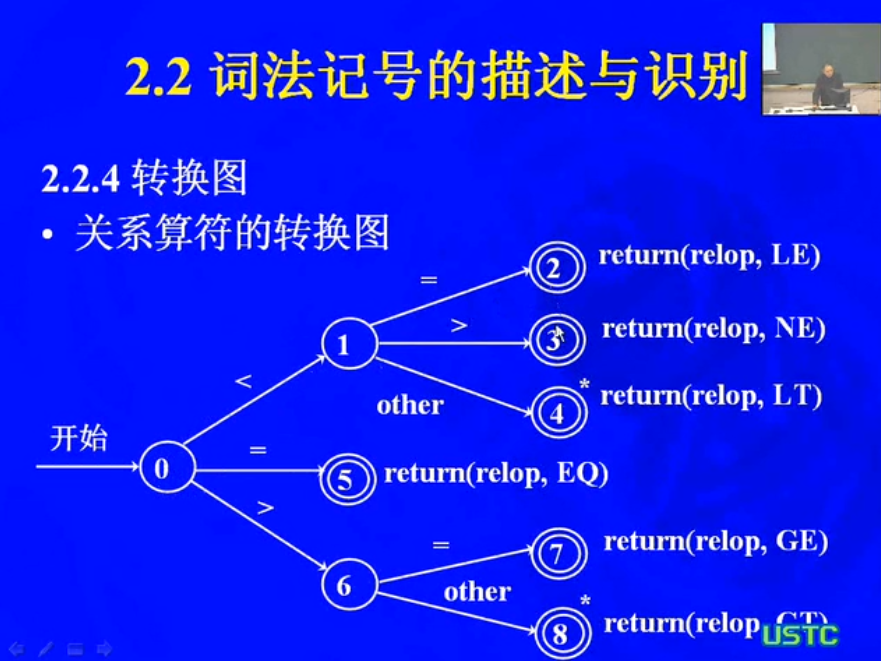
relation <,<=,=,... <或<=或=或...
id sum,count,D5 由字母开头的字母数字串
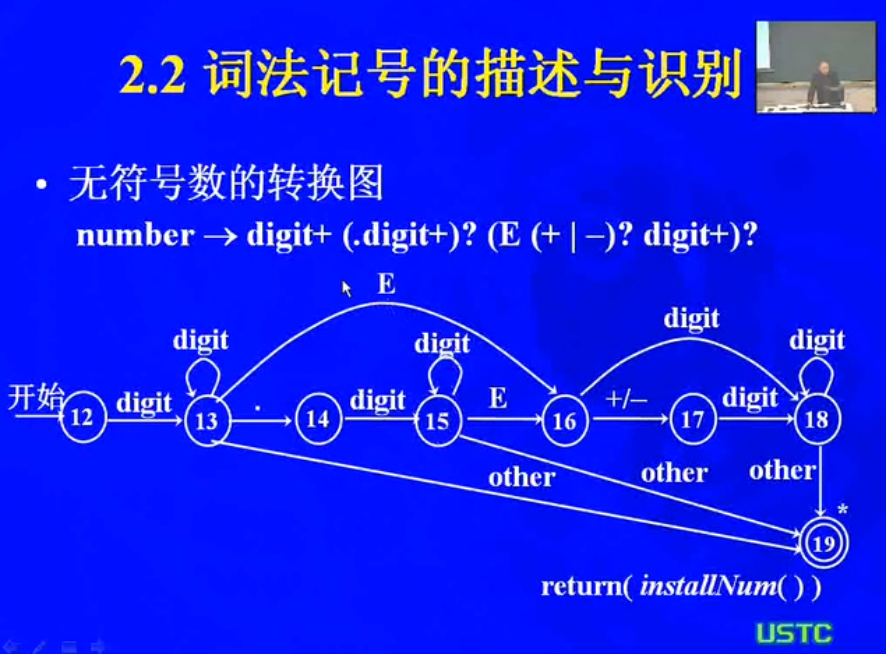
number 3.1,10,2.8 E12 任何数值常数
literal “seg.error” 引号“和”之间任意不含引号本身的字符串
历史上词法定义中的一些问题
---- 忽略空格带来的困难
DO 8 I = 3.75 等同于 DO8I=3.75
DO 8 I = 3,75
---- 关键字不保留
IF THEN THEN THEN=ELSE; ELSE ...
---- 关键字、保留字和标准标识符的区别
保留字是语言预先确定了含义的词法单元
标准标识符也是预先确定了含义的标识符,但程序可以重新声明它的含义
词法记号的属性
position = initial + rate * 60 的记号和属性值:
<id,指向符号表中position条目的指针>
<assign_op>
<id,指向符号表中initial条目的指针>
<add_op>
<id,指向符号表中rate条目的指针>
<mul_op>
<number,整数值60>
词法错误
---- 词法分析器对源程序采取非常局部的观点
---- 例:难以发现下面的错误
fi(a == f(x))....
---- 在实数是“数字串.数字串”格式写,可以发现下面的错误
123.x
---- 紧急方式的错误恢复
删掉当前若干个字符,直到能读出正确的记号
---- 错误修补
进行增、删、替换和交换字符的尝试
1.2 词法记号的描述与识别
串和语言
---- 字母表:符号的有限集合,例如:Σ = {0,1}
---- 串:符号的有穷序列,例如:0100,ε
---- 语言:字母表上的一个串集
{ε,0,00,000,...},{ε},Φ
---- 句子:属于语言的串
串的运算
---- 连接(积) xy, se = es = s
---- 幂 s0为e,si为si-1s(i>0)
语言的运算
---- 并运算:L∪M = {s|s∈L或s∈M}
---- 连接:LM={st|s∈L且t∈M}
----幂运算:L0是{e},Li是Li-1L
---- 闭包:L*=L0∪L1∪L2∪...
---- 正闭包:L+=L1∪L2∪...
正规式:
正规式用来表示简单的语言,叫做正规集
正规式 定义的语言 备注
e {e}
a {a} a∈Σ
(r)|(s) L(r)∪L(s) r和s是正规式
(r)(s) L(r)∪L(s) r和s是正规式
(r)* (L(r))* r是正规式
(r) L(r) r是正规式
((a)(b)*)|(c)可以写成ab*|c,如果按照定义了优先级可以按照这种形式写出。
其他例子:
---- a|b {a,b}
----- (a|b)(a|b) {aa,ab,ba,bb}
----- aa|ab|ba|bb {aa,ab,ba,bb}
---- a* 由字母a构成的所有串集
---- (a|b)* 有a和b构成的所有串集
*表示重复若干次
正规定义
---- 对正规式的命名,使表示简介



?---可以有可以没有,+表示可选择。

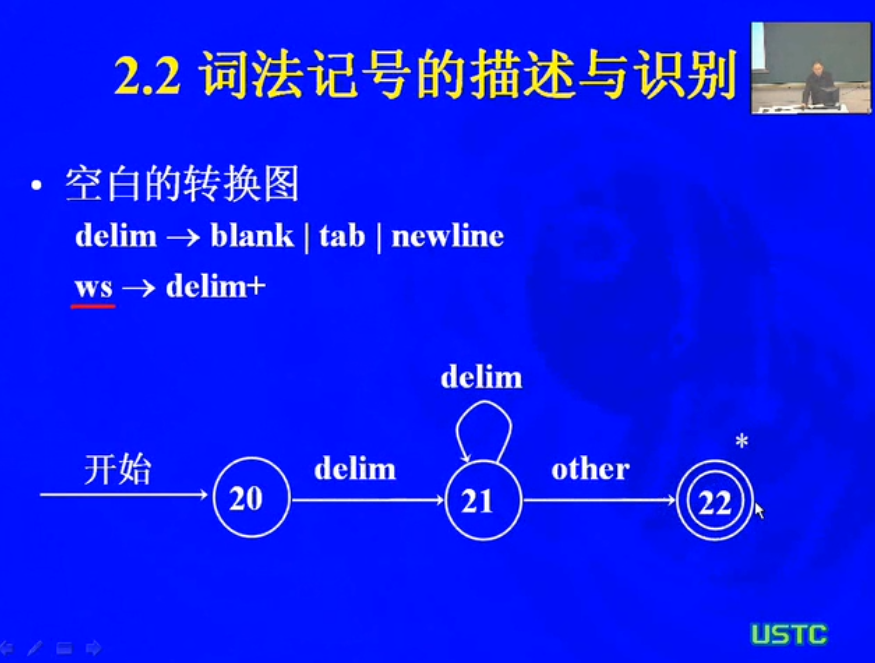
ws,white space ,若干个空白符
转换图

1.3 有限自动机
不确定的有限自动机NFA
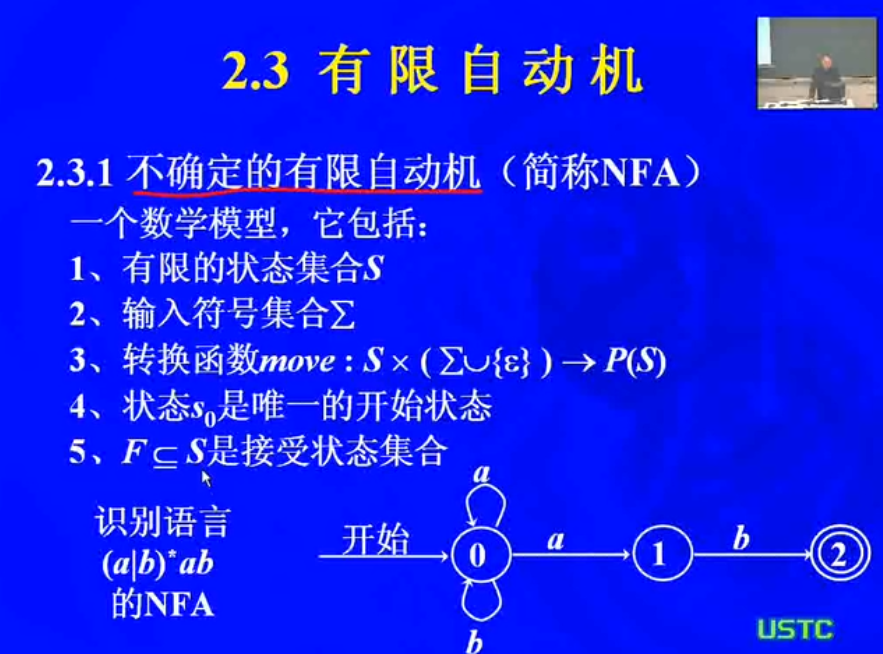
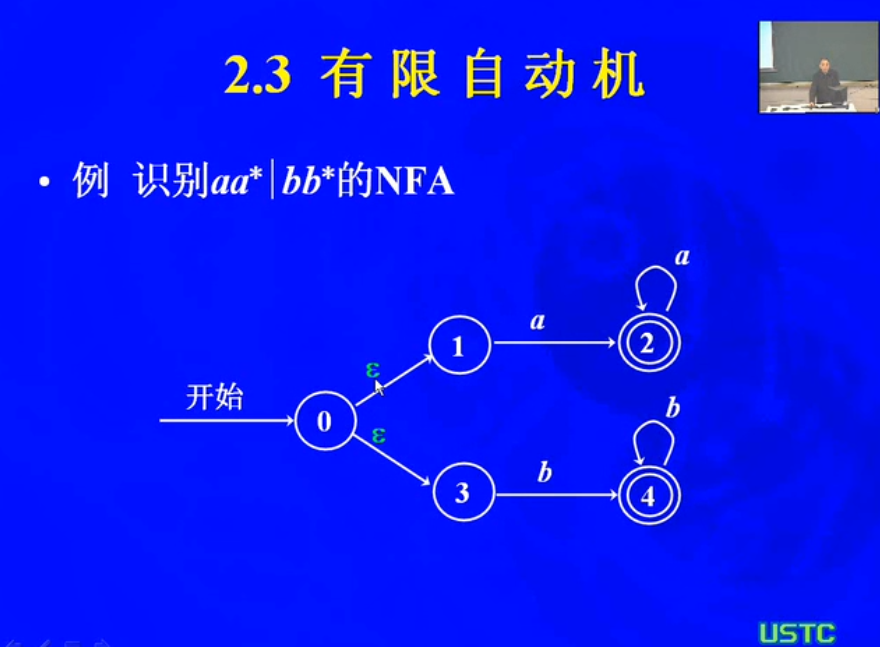
1.4 确定的有限自动机DFA
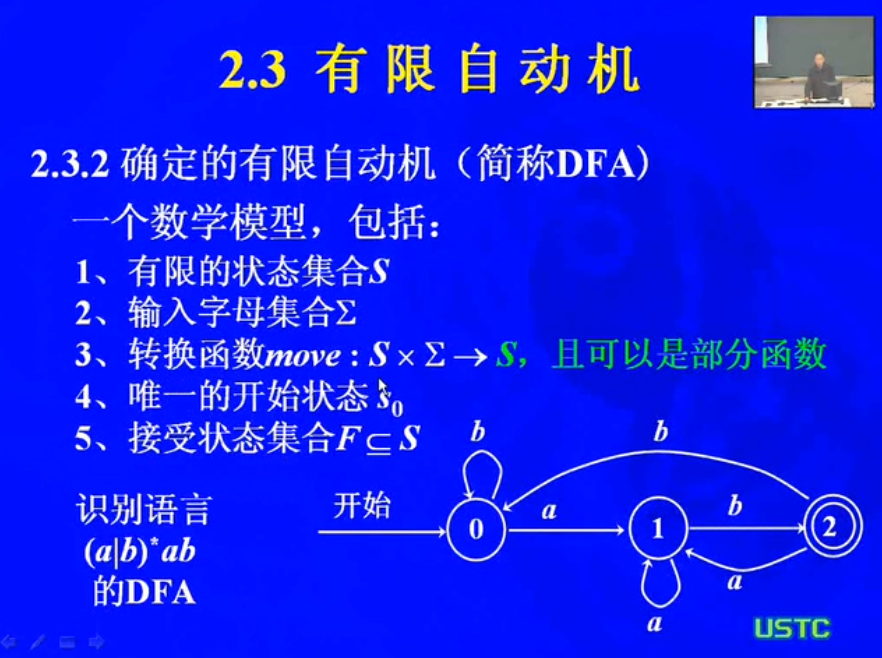
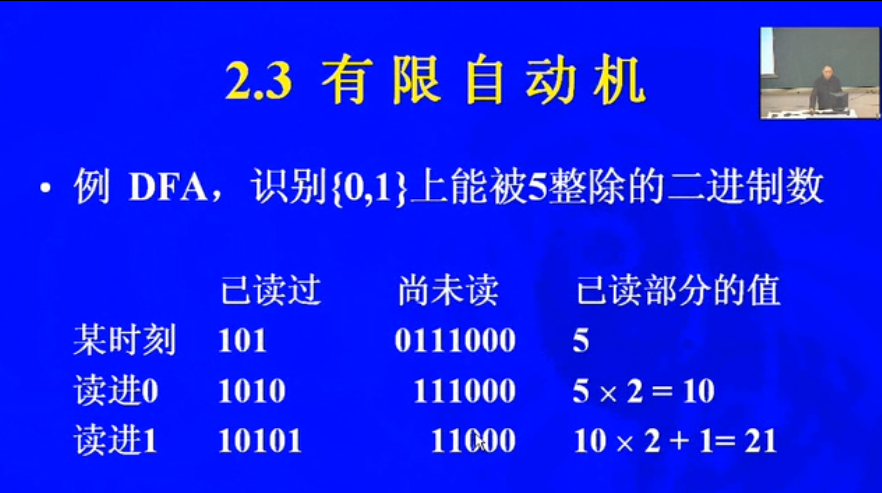
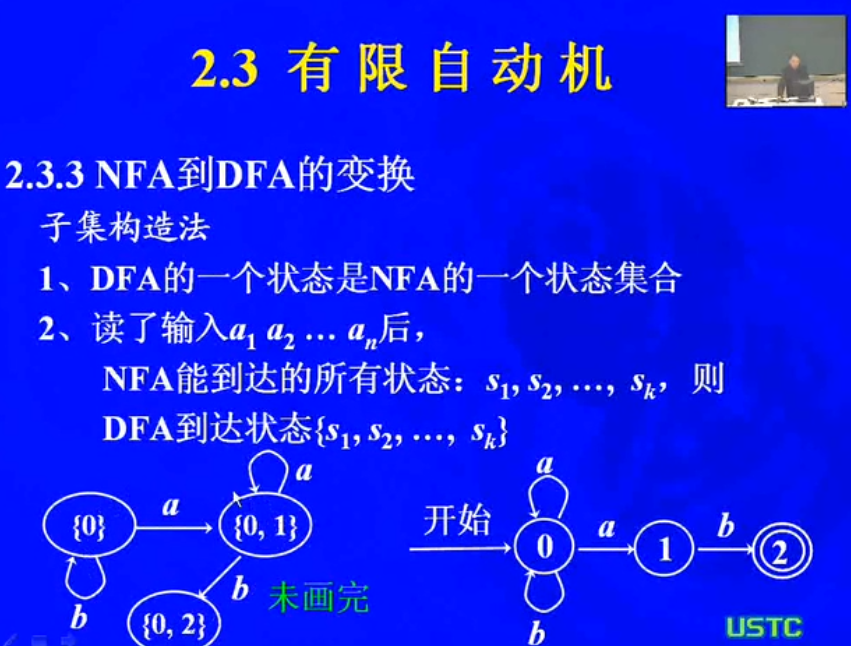
NFA到DFA的变化
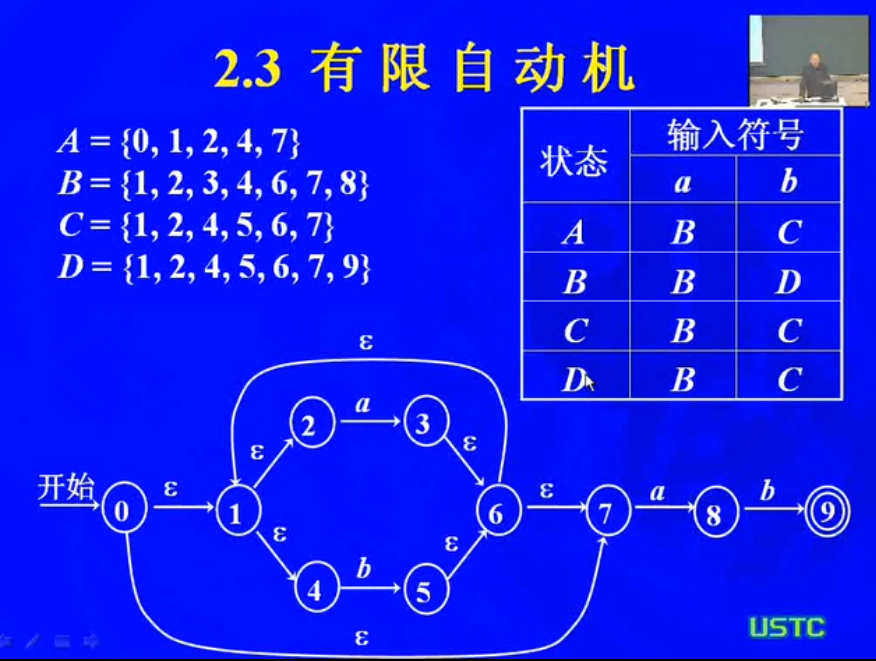
一种算法示意如下:

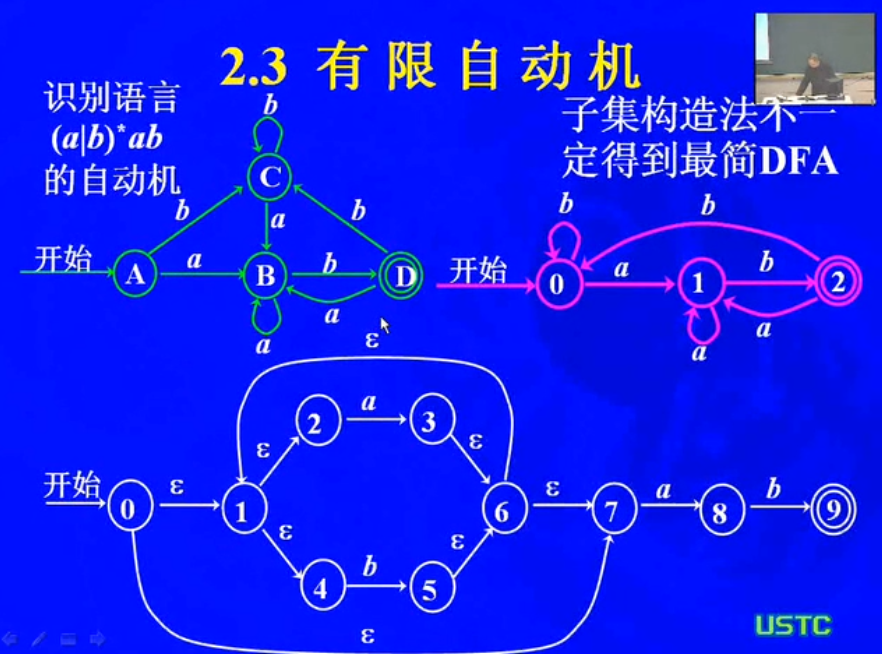
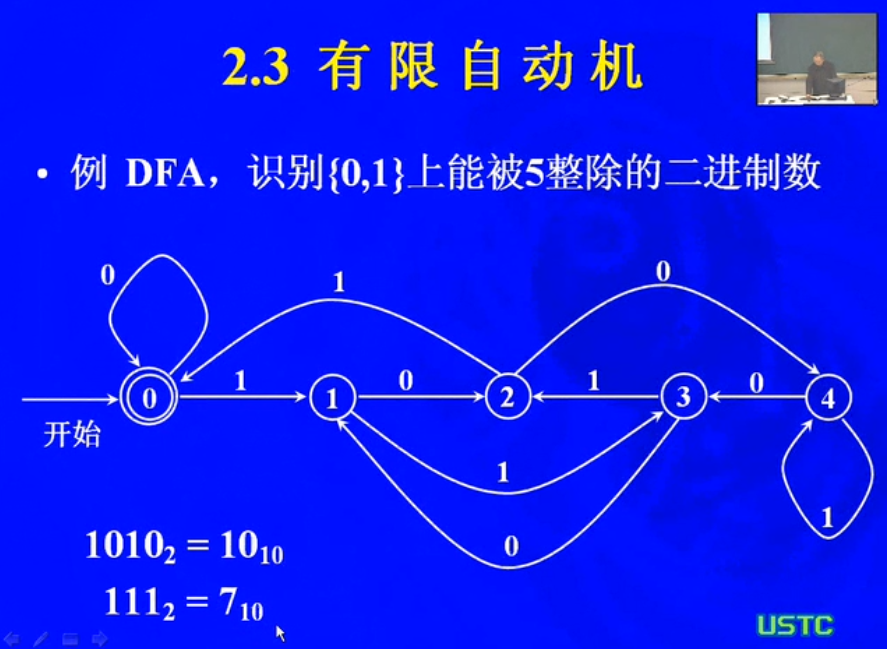
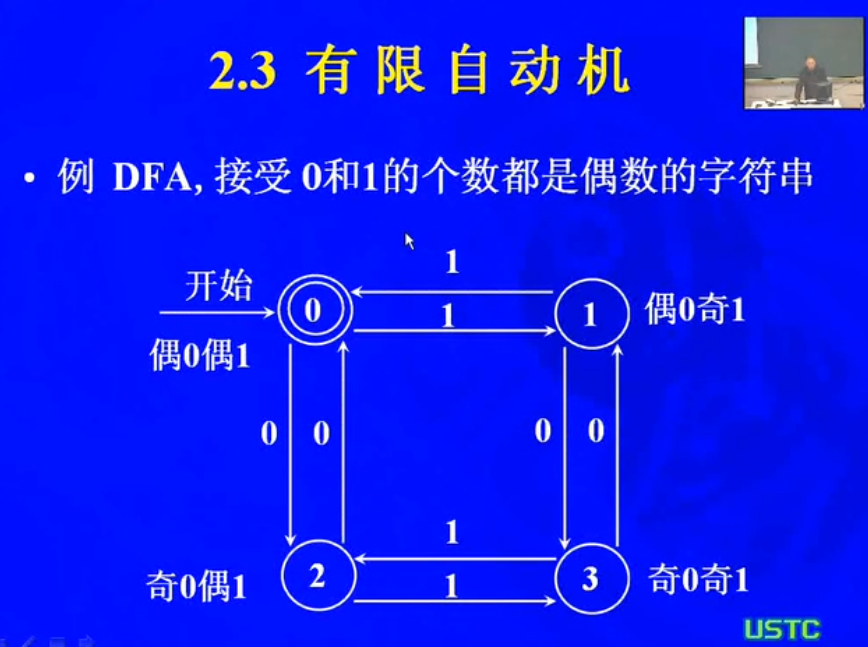
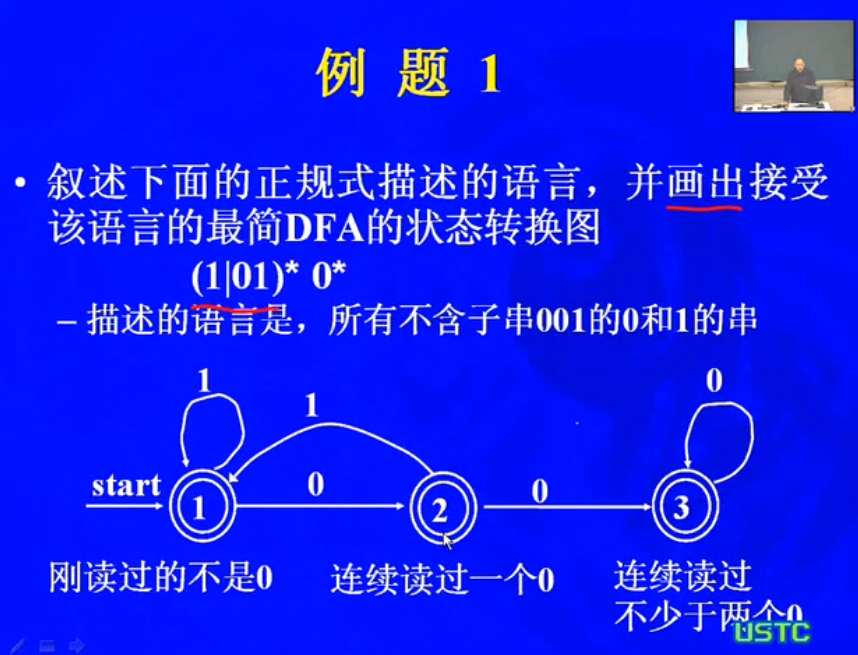
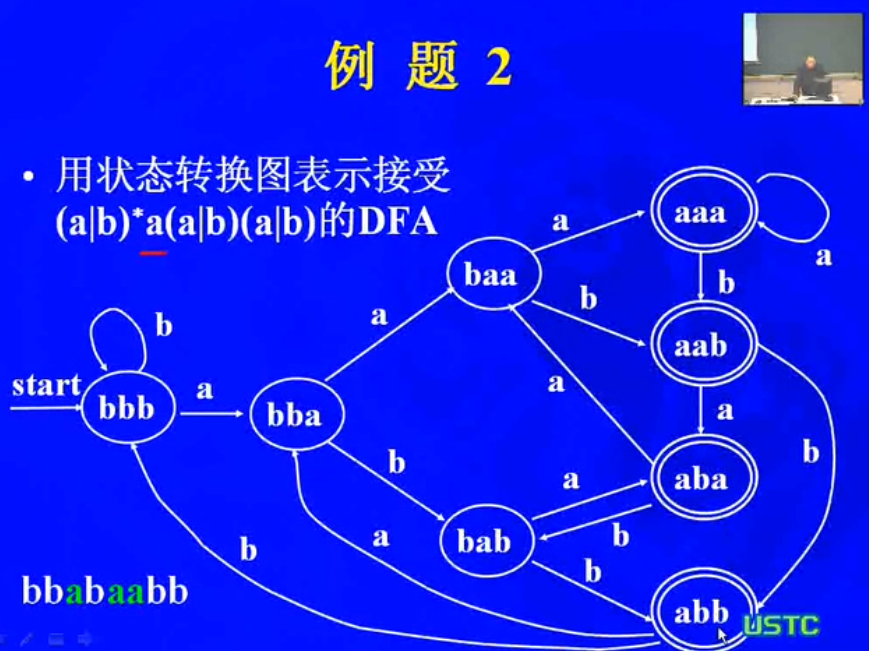
例题:





本章总结:
* 词法单元。词法分析器扫描源程序并输出一个由词法单元组成的序列。这些词法通常会逐个传送给语法分析器。有些词法单元只包含一个词法单元名,而其他词法单元还有一个关联的词法值,它给出了在输入中找到的这个词法单元的某个实例的有关信息。
* 词素。每次词法分析器向语法分析器返回一个词法单元时,该词法单元都有一个关联的词素,即该词法单元所代表的输入字符串。
* 缓冲技术。为了判断下一个词素在何处结束,常常需要预先扫描输入字符。因此,词法分析器往往需要对输入字符进行缓冲。可以使用两个技术来加速输入扫描过程:循环使用一对缓冲区,以及在每个缓冲区末尾放置特殊的哨兵标记符。该字符可以通过词法分析器已经达到了缓冲区末尾。
* 模式。每个词法单元都有一个模式,它描述了什么样的字符序列可以组成对应的词法单元的词素。那些和一个给定模式匹配的字的集合称为该模式的语言。
* 正则表达式。这些表达式常用于描述模式。正则表达式是从单个字符开始,通过并7连接、Kleene闭包、“重复多次”等运算符构造得到。
* 正则定义。多个语言的复杂集合,比如用以描述一个程序设计语言所有词法单元的多个模式常常是通过正则定义来描述的。一个正则定义是一个语句序列,其中每个语句定义了一个表示某正则表达式的变量。定义一个变量的正则表达式时可以使用已经定义过的变量。
* 扩展的正则表达式表达法。为使正则式更易于表达模式,一些附加的运算符可以作为缩写在正则表达式中使用。比如+(一个或多个)、?(零个或一个)以及字符类,由特定字符集中单个字符组成的字符串的集合。
* 状态转换图。一个词法分析器的行为经常可以用一个状态转换图来描述。它由多个状态。它同时具有多条从一个状态到另一个状态的转换。每个转换都指明了下一个可能的输入字符,该字符将使用词法分析器来改变当前状态。
* 有穷自动机(有限自动机)。他是状态转换图的形式化表达。它指明了一个开始状态、一个或多个接受撞题,以及状态集、输入字符集和状态间的转换集合。接受状态表明已发现了和某个词法单元对应的词素。与状态转换图不同,有穷自动机既可以在输入字符上执行转换,亦可以在空输入上执行转换。
* 确定有穷自动机。一个确定有穷自动机是一种特殊的有穷自动机。他的任何一个状态对于任意一个输入符号有且只有一种转换。
* 不确定有穷自动机。不是确定有穷自动机的自动机称为不确定的。NFA通常要比确定有穷自动机更容易设计。
* 模式表达方法之间的转换。我们可以把任意一个正则表达式转换为一个大小基本相同的NFA,这个NFA是不的语言和该正则表达式识别相同。更进一步,任何NFA都可转换为一个代表相同模式的DFA,虽然在最坏的情况下自动机的大小会以指数级增长,但是在常见的程序设计语言中尚未碰到这些情况。
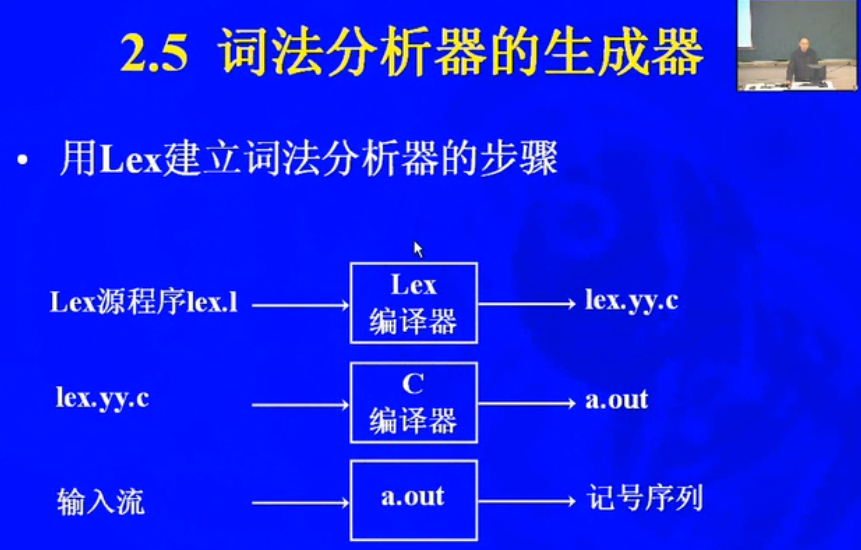
* Lex。有一系列的软件系统,包括Lex和Flex,可以作为生成词法分析器的工具。用户通过扩展的正则表达式来描述各种词法单元的模式。Lex将这些表达式转化为词法分析器。这些分析器实质上是一个可以识别所有模式的确定有穷自动机。
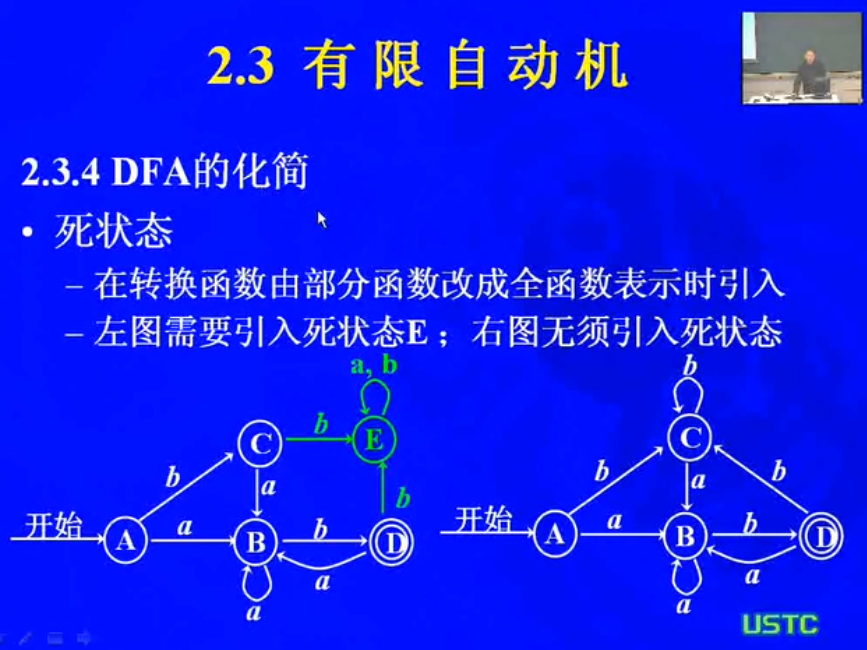
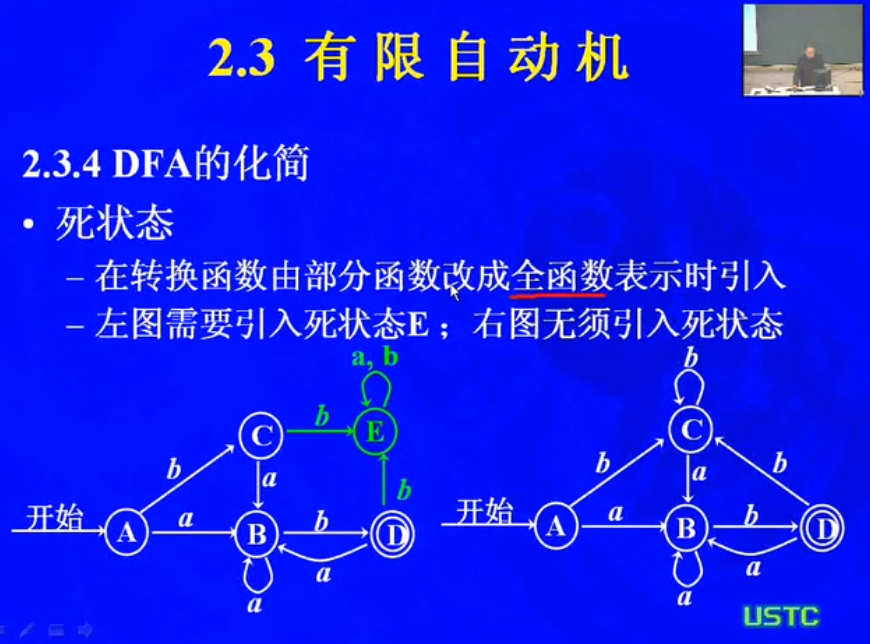
* 有穷自动机的最小化。对于每一个DFA,都存在一个接受同样语言的最小状态DFA。步进如此,一个给定语言的最少状态DFA是唯一的。