1、针对pandas在对读取超过上G的数据时速度较慢,并且即使读取后,可能由于文件过大使用pandas的方法导致死机的情况较多。
2、vaex属于DataFrame的一个扩展性,针对大型文件的处理,特别好用,其机理是采用“映射”的方式,并不把数据直接读取到内存里面。其相关的介绍和使用教程,API等可在官网查找到:https://vaex.io/docs/api.html#vaex.from_csv。其中的方法和纯Pandas的相似,有些几乎一样的。
3、实际应用:
这里举一个简单:比如我现在有一个将近6G的csv文件,来自于期货螺纹钢(rb),2016年到现在的数据,文件比较大,我们要对这个数据进行清洗,针对数据的datetime,分解成Data(格式:YYYY/MM/DD)和Time(格式:HH:MM:SS)的样式,其中last_price存为Price,成交量volume存出为Volume。然后对比后存储为csv文件。过程就是一个简单的数据清洗。
第一步:读取原始csv文件并存储为vaex的hdf5的数据结构,并读取出来
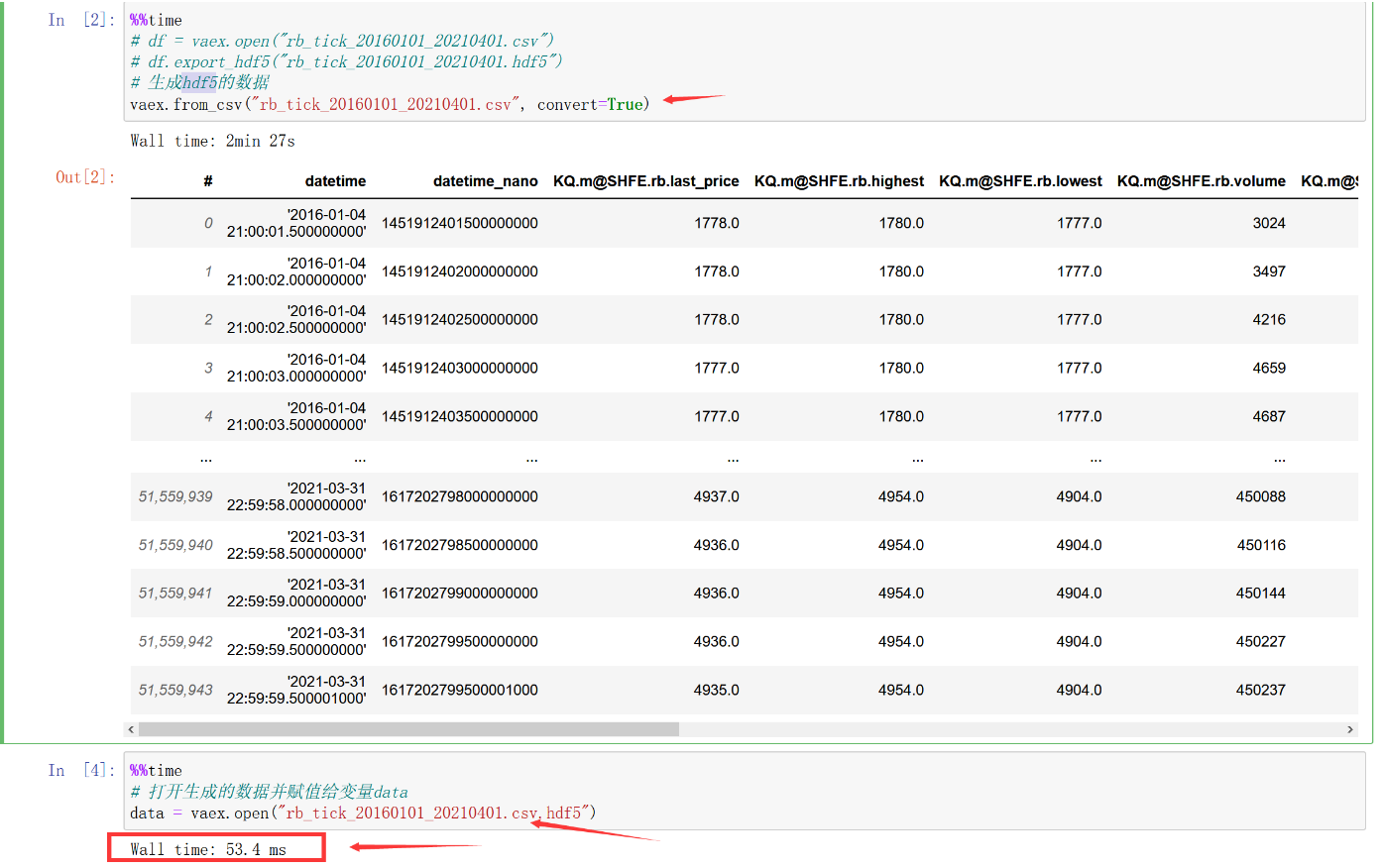
此时我们可以看到文件夹里面生成了一个hdf5数据结构,打开速度也是非常快的,当日你也可以试一下Pandas会让你慢的崩溃。

第二步:查看数据信息
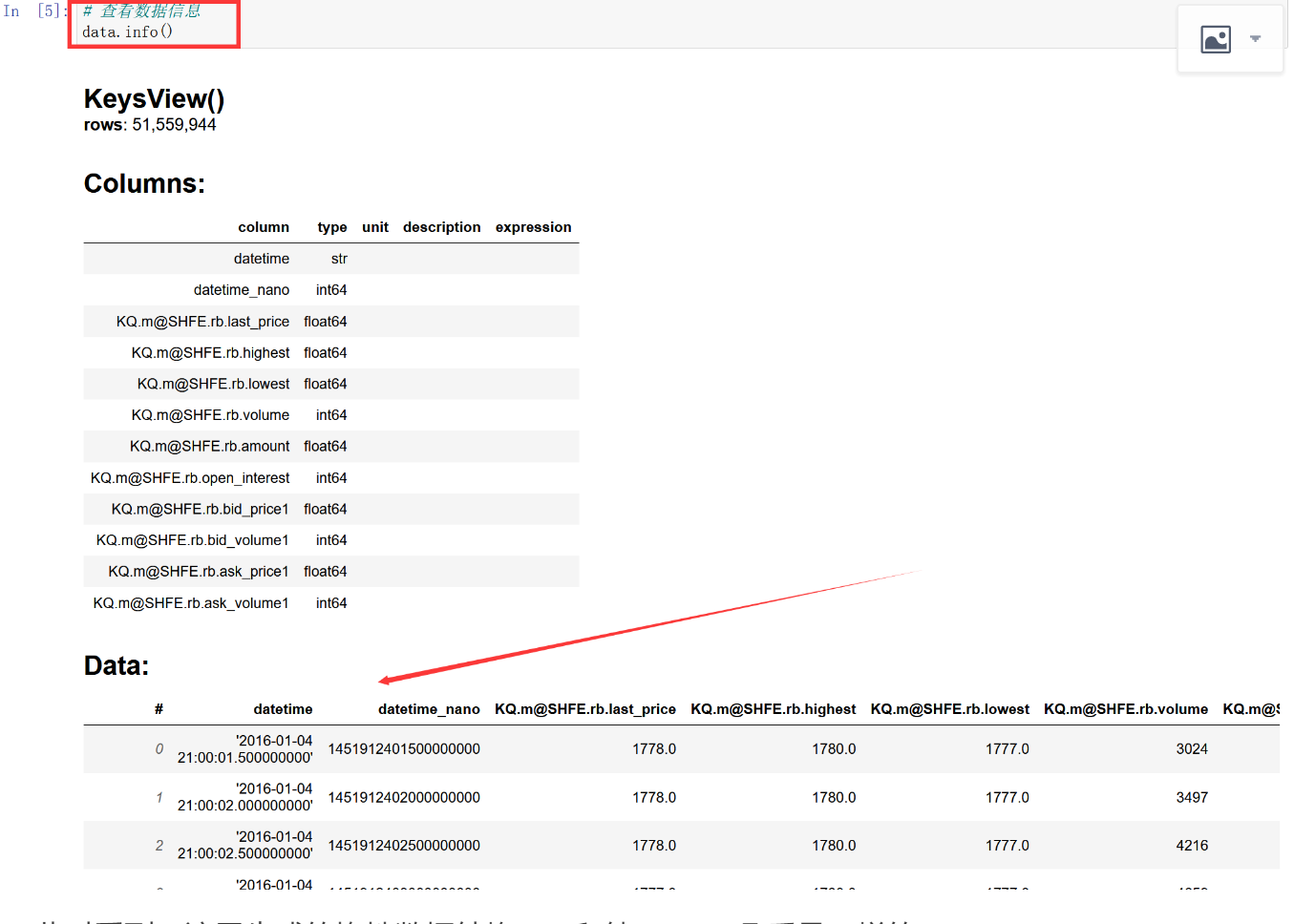
此时看到,这里生成的惰性数据结构hdf5和纯Pandas几乎是一样的。
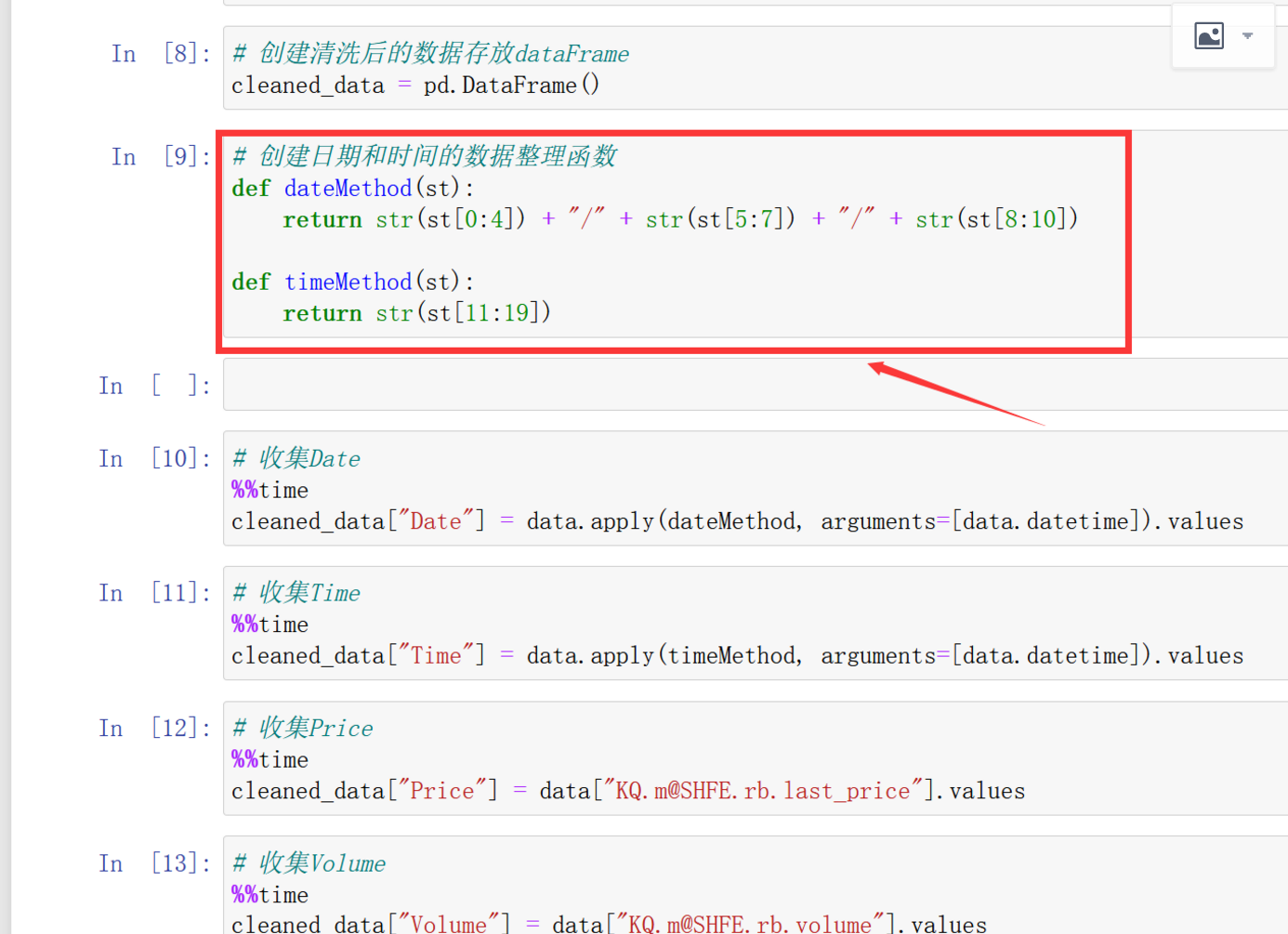
第三步:增加两个处理字符的方法,下面apply的方法和纯Pandas略有不一样,此时要注意。并打印清洗后的DataFrame数据结果:
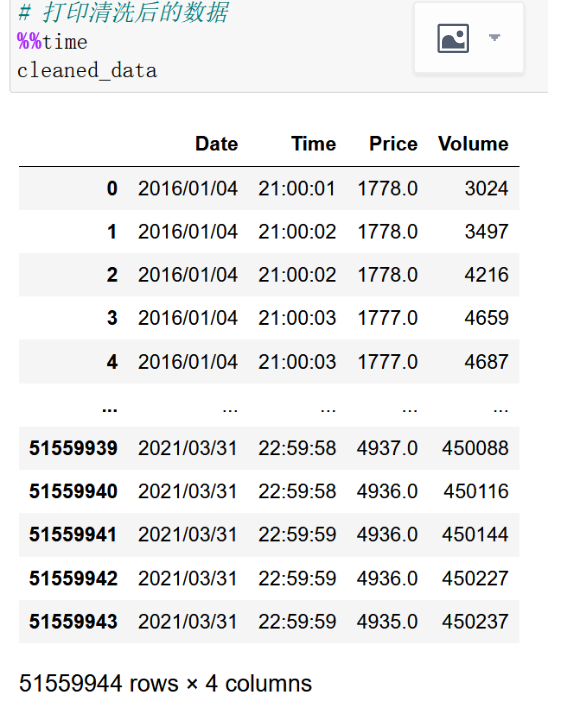
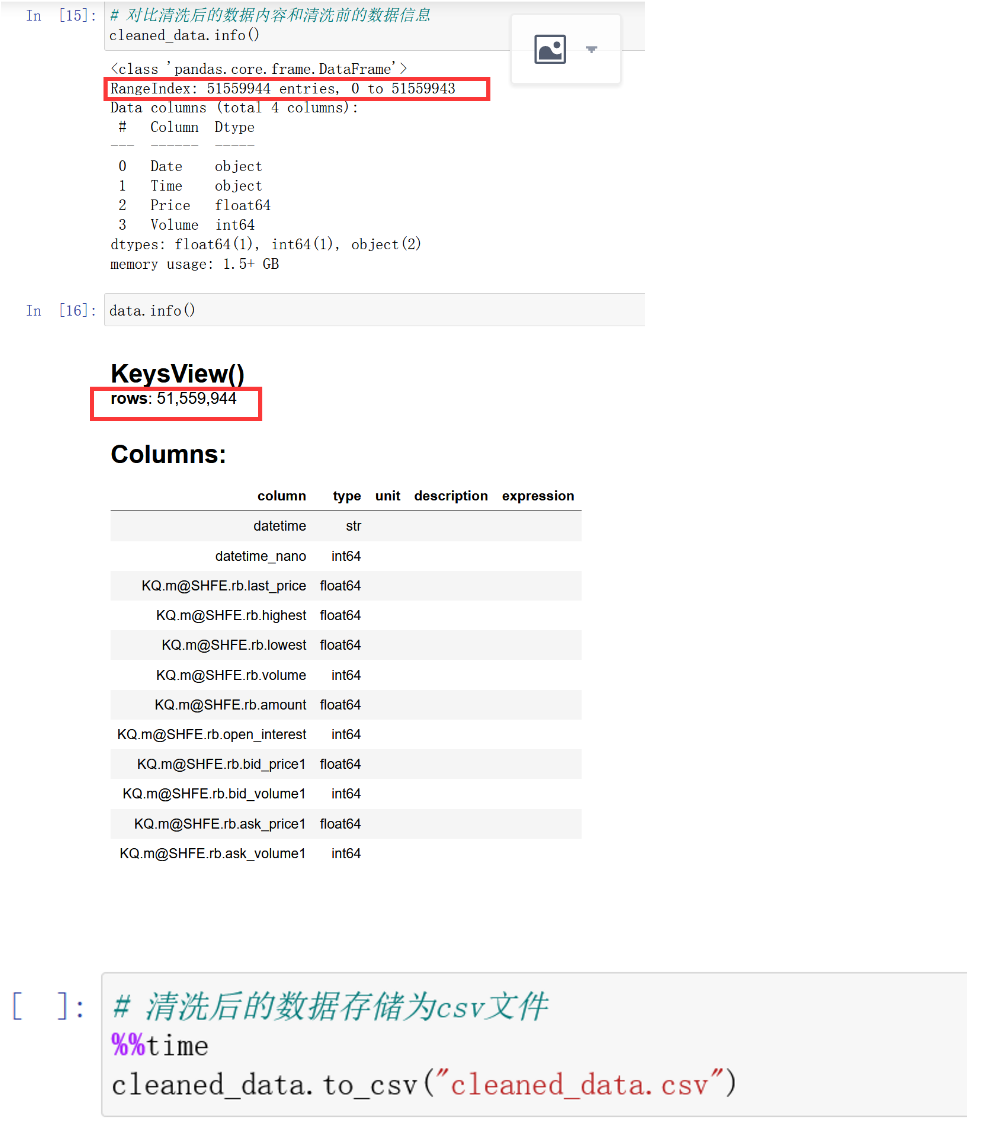
第四步:查看清洗后数据的信息,对比,然后存储为csv文件。
对比后数据行数一致
4、源码:
import pandas as pd
import vaex
# df = vaex.open("rb_tick_20160101_20210401.csv")
# df.export_hdf5("rb_tick_20160101_20210401.hdf5")
# 生成hdf5的数据
vaex.from_csv("rb_tick_20160101_20210401.csv", convert=True)
# 打开生成的数据并赋值给变量data
data = vaex.open("rb_tick_20160101_20210401.csv.hdf5")
# 查看数据信息
data.info()
# 创建清洗后的数据存放dataFrame
cleaned_data = pd.DataFrame()# 查看数据信息
# 创建日期和时间的数据整理函数
def dateMethod(st):
return str(st[0:4]) + "/" + str(st[5:7]) + "/" + str(st[8:10])
def timeMethod(st):
return str(st[11:19])
# 收集Date
cleaned_data["Date"] = data.apply(dateMethod, arguments=[data.datetime]).values
# 收集Time
cleaned_data["Time"] = data.apply(timeMethod, arguments=[data.datetime]).values
# 收集Price
cleaned_data["Price"] = data["KQ.m@SHFE.rb.last_price"].values
# 收集Volume
cleaned_data["Volume"] = data["KQ.m@SHFE.rb.volume"].values
# 打印清洗后的数据
cleaned_data
# 对比清洗后的数据内容和清洗前的数据信息
cleaned_data.info()
data.info()
# 清洗后的数据存储为csv文件
cleaned_data.to_csv("cleaned_data.csv")
5、建议安装vaex在纯python环境下,不容易出错。