上一篇总结完了顺序表,这一篇要总结的是线性表之中的链表。我将会从以下几点进行总结:
1、为什么要使用链表?
2、链表的存储结构?
3、链表的常用操作代码实现?
1、为什么要使用链表
通过上一篇的学习,我们知道顺序表存在一些问题,主要有以下两个方面。
1、顺序表的长度是固定的,如果超出分配的长度就会造成溢出,如果存放的数据太少就会造成空间浪费。
2、在插入元素和删除元素时(尤其插入和删除的位置不在尾部时),会移动大量的元素,造成性能和效率低下。
基于以上问题,使用链表可以很好地避免顺序表中出现的问题。这也是我们要使用链表的原因。
2、链表的存储结构
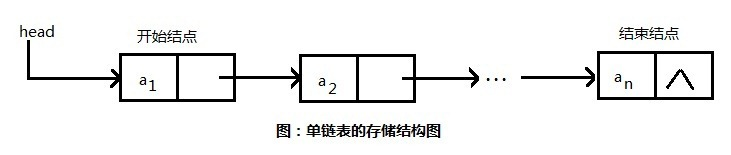
1、从上图可以看出,单链表中的每个节点都包含一个“数据域”和一个“指针域”。“数据域”中包含当前节点的数据,“指针域”中包含下一节点的存储地址。
2、头指针 head 是指向开始节点的,结束节点没有后继节点,所以结束节点的指针域为空,即 null。
3、链表在物理存储结构上不连续,逻辑上连续;大小不固定。
4、根据链表的构造方式的不同可以分为:
- 单向链表
- 单向循环链表
- 双向链表
- 双向循环链表
2-1、单向链表
链表的每个节点中只包含一个指针域,叫做单向链表(即构成链表的每个节点只有一个指向后继节点的指针)
单向链表中每个节点的结构:

2-2、单向循环链表
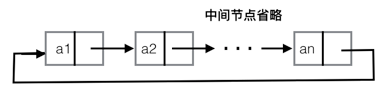
单向循环链表和上面讲的单向链表有点相似,都是通过节点的指针指向它的下一个节点,然后这样连接起来,但不同的地方是单向链表的最后一个节点的指针为null,而单向循环链表的最后一个节点的指针指向的是头节点,这样构成了一个循环的节点的环。下面是单向循环链表的示意图:
2-3、双向链表
听名字可能就能猜到双向链表就是链表的节点包含两个指针,一个指针是指向它的下一个节点,另一个指针指向它的上一个节点。这样双向链表就可以通过第一个节点找到最后一个节点,也可以通过最后一个节点找到第一个节点,双向链表的示意图:

2-4、双向循环链表
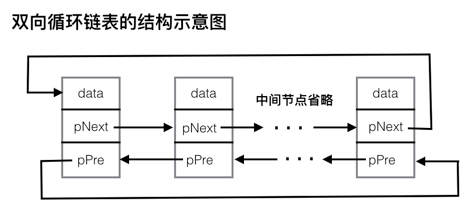
双向循环链表相对于上面的双向链表多了“循环”两个字,我们就可以结合单向循环链表联想到,其实双向循环链表就是双向链表够成了一个环。双向循环链表的示意图:
3、链表的常用操作
链表常用的操作有:(以单向链表为例)
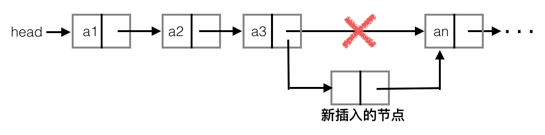
3-1、插入节点
思路:需要循环查找此节点应该插入的位置。所以时间复杂度为O(n)
示意图:
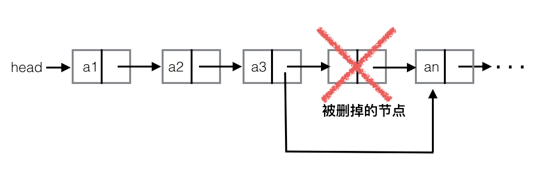
3-2、删除节点
思路:循环查找要删除的节点的位置,所以时间复杂度为O(n)
示意图:
3-3、查找节点
思路:与插入节点和删除节点的方法类似,需要遍历链表中的节点,所以时间复杂度为O(n)
3-4、获取链表的长度
思路:不像顺序表那样连续存储,获取表的长度非常容易;在链表中,数据不是连续存储的,因此需要循环遍历才能求得链表的长度,所以时间复杂度为O(n)
4、链表的常用操作的代码实现
4-1、插入节点
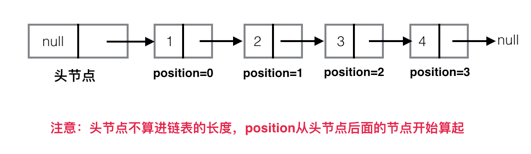
在代码里面用到了一个变量 position,它的含义如下图所示:
注意:
1、头节点不存储数据,它的数据域为null,它的地址域存储了第1个节点的地址
2、头节点不算进链表的长度,position 从头节点后面的节点开始算起
3、每个节点里面分别有数据域和地址域
下面是具体的实现代码:
先创建一个节点类: Node.java
package com.demo; /** * 节点类 */ public class Node { Object element; // 数据域 Node next; // 地址域 // 节点的构造方法 public Node(Object element, Node next) { this.element = element; this.next = next; } // Gettet and Setter public Node getNext() { return this.next; } public void setNext(Node next) { this.next = next; } public Object getElement() { return this.element; } public void setElement(Object element) { this.element = element; } }
注意每个节点里面分别有数据域和地址域!
定义链表类:MyLinkedList.java
package com.demo; /** * 自己定义的一个链表类 */ public class MyLinkedList { // 头节点 private Node headNode; // 用来遍历链表的临时节点 private Node tempNode; // 链表的初始化方法 public MyLinkedList() { // 初始化时,链表里面只有1个节点,所以这个节点的地址域为null Node node = new Node("王重阳", null); // 头节点不存储数据,它的数据域为null,它的地址域存储了第1个节点的地址 headNode = new Node(null, node); } /** * 1、插入节点:时间复杂度为O(n) * @param newNode 需要插入的新节点 * @param position 这个变量的范围可以从0到链表的长度,注意不要越界。 * 头节点不算进链表的长度, * 所以从头节点后面的节点开始算起,position为0 */ public void insert(Node newNode, int position) { // 通过position变量,让tempNode节点从头节点开始遍历,移动到要插入位置的前一个位置 tempNode = headNode; int i = 0; while (i < position) { tempNode = tempNode.next; i++; } newNode.next = tempNode.next; tempNode.next = newNode; } // 遍历链表,打印出所有节点的方法 public void showAll() { tempNode = headNode.next; while (tempNode.next != null) { System.out.println(tempNode.element); tempNode = tempNode.next; } System.out.println(tempNode.element); } }
测试类:TestMyLinkedList.java
package com.demo; public class TestMyLinkedList { public static void main(String[] args) { MyLinkedList myLinkedList = new MyLinkedList(); Node newNode1 = new Node("欧阳锋", null); Node newNode2 = new Node("黄药师", null); Node newNode3 = new Node("洪七公", null); myLinkedList.insert(newNode1, 0); myLinkedList.insert(newNode2, 0); myLinkedList.insert(newNode3, 0); myLinkedList.showAll(); } }
运行结果:
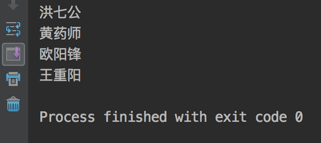
王重阳是初始化的节点,之后又往链表里插入了3个节点。注意它们插入的位置和打印出来的顺序!
4-2、删除节点
在 MyLinkedList.java 中添加删除节点的方法
/** * 2、删除节点:时间复杂度为O(n) * @param position */ public void delete(int position) { // 这里同样需要用tempNode从头开始向后查找position tempNode = headNode; int i = 0; while (i < position) { tempNode = tempNode.next; i++; } tempNode.next = tempNode.next.next; }
测试代码:TestMyLinkedList.java
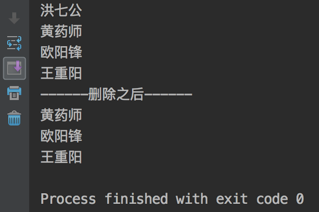
package com.demo; public class TestMyLinkedList { public static void main(String[] args) { MyLinkedList myLinkedList = new MyLinkedList(); Node newNode1 = new Node("欧阳锋", null); Node newNode2 = new Node("黄药师", null); Node newNode3 = new Node("洪七公", null); myLinkedList.insert(newNode1, 0); myLinkedList.insert(newNode2, 0); myLinkedList.insert(newNode3, 0); myLinkedList.showAll(); myLinkedList.delete(0); System.out.println("------删除之后------"); myLinkedList.showAll(); } }
运行结果:
4-3、查找节点
在 MyLinkedList.java 中添加查找节点的方法
/** * 3、查找节点:时间复杂度为O(n) * @param position * @return 返回查找的节点 */ public Node find(int position) { // 这里同样需要用tempNode从头开始向后查找position tempNode = headNode; int i = 0; while (i < position) { tempNode = tempNode.next; i++; } return tempNode.next; }
测试代码:TestMyLinkedList.java
package com.demo; public class TestMyLinkedList { public static void main(String[] args) { MyLinkedList myLinkedList = new MyLinkedList(); Node newNode1 = new Node("欧阳锋", null); Node newNode2 = new Node("黄药师", null); Node newNode3 = new Node("洪七公", null); myLinkedList.insert(newNode1, 0); myLinkedList.insert(newNode2, 0); myLinkedList.insert(newNode3, 0); myLinkedList.showAll(); System.out.println("----查找position为2的节点----"); Node result = myLinkedList.find(2); System.out.println(result.element); } }
运行结果:
4-4、获取链表的长度
在 MyLinkedList.java 中添加方法
/** * 4、获取链表的长度:时间复杂度为O(n) * @return */ public int size() { tempNode = headNode.next; int size = 0; while (tempNode.next != null) { size = size + 1; tempNode = tempNode.next; } size = size + 1; // tempNode的地址域为null时,size记得加上最后一个节点 return size; }
测试代码:TestMyLinkedList.java
package com.demo; public class TestMyLinkedList { public static void main(String[] args) { MyLinkedList myLinkedList = new MyLinkedList(); Node newNode1 = new Node("欧阳锋", null); Node newNode2 = new Node("黄药师", null); Node newNode3 = new Node("洪七公", null); myLinkedList.insert(newNode1, 0); myLinkedList.insert(newNode2, 0); myLinkedList.insert(newNode3, 0); myLinkedList.showAll(); System.out.println("----------"); System.out.println("链表的长度为:" + myLinkedList.size()); } }
运行结果:

5、总结
1、链表插入和删除一个元素的时间复杂度均为O(n),另外,链表读取一个数据元素的时间复杂度也为O(n)
2、顺序表和单链表的比较:
①顺序表:
优点:主要优点是读取元素的速度较快,以及内存空间利用效率高;
缺点:主要缺点是需要预先给出顺序表的最大元素个数,而这通常很难准确做到。当实际的元素个数超过了预先给出的个数,会发生异常。另外,顺序表插入和删除操作时需要移动较多的数据元素。
②单链表:
优点:主要优点是不需要预先给出最大元素个数。另外,单链表插入和删除操作时不需要移动数据元素;
缺点:主要缺点是每个节点都需要分为地址域和数据域,因此单链表的空间利用率略低于顺序表。另外,单链表读取一个元素的时间复杂度为O(n) ;而顺序表读取一个元素的时间复杂度为O(1)
欢迎转载,但请保留文章原始出处