一、机器学习介绍
机器通过统计学算法,对大量的历史数据进行学习从而生成经验模型,利用经验模型指导业务。
机器学习常见分类

1.监督学习
监督学习( Supervised learning ) : 利用一组已知类别的样本来训练模型,使其达到性能要求。其特点为输入数据(训练数据)均有个明确的标识或结果 (标签)。即我们提供样例 "教"计算机如何学习。
有监督学习算法主要包括分类、回归等。
例如(分类、回归):

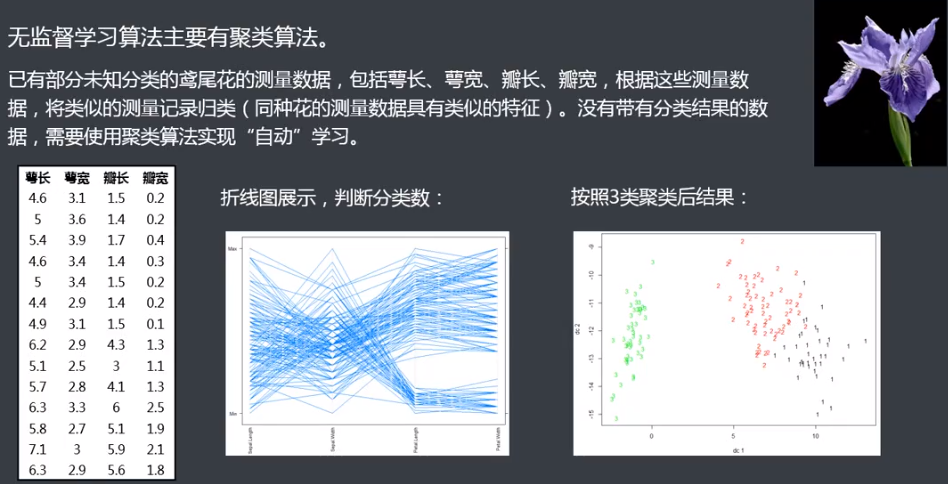
2.无监督学习
无监督学习( Unsupervised learning ) : 从无标记的训练数据中推断结论。其特点为输入数据(训练数据)不存在明确的标识或结果(标签)。常见的无监督学习为聚类,即发现隐藏的模式或者对数据进行分组。即计算机根据我们提供的材料"自动”学习,给定数据,寻找隐藏的结构或模式。
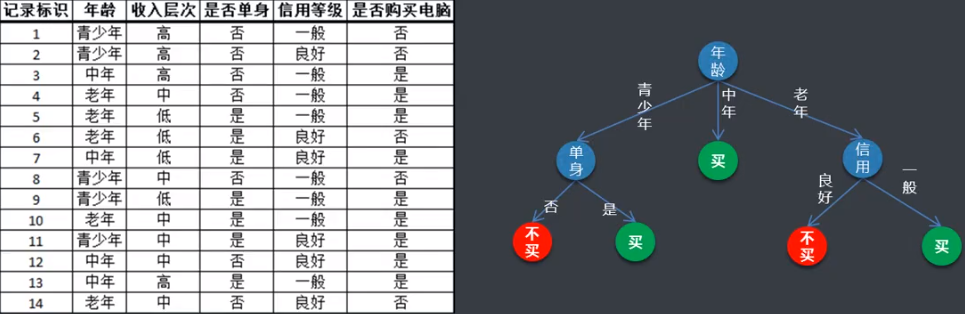
例如:
机器学习应用案例
个性化推荐引擎(淘宝推荐系统)、蚂蚁芝麻信用、光学文字识别...
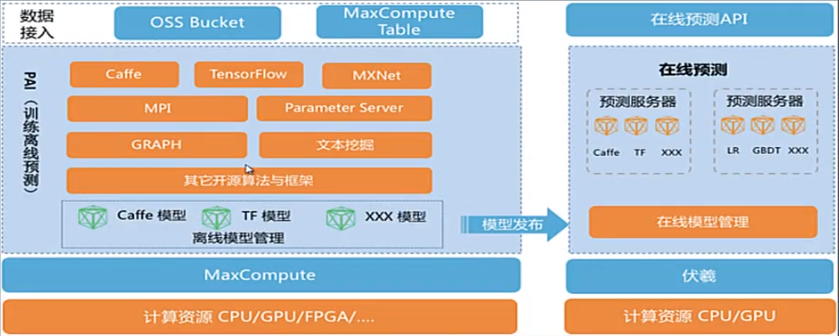
二、阿里云机器学习PAI平台
阿里云机器学习平台PAI是基于MaxCompute提供数据处理、建模、离线预测、在线预测等服务的大型机器学习平台,为算法开发者提供了丰富的MPI、PS、 BSP等编程框架和数据存取接口,同时提供了基于Web的可视化控制台,降低了使用门槛。
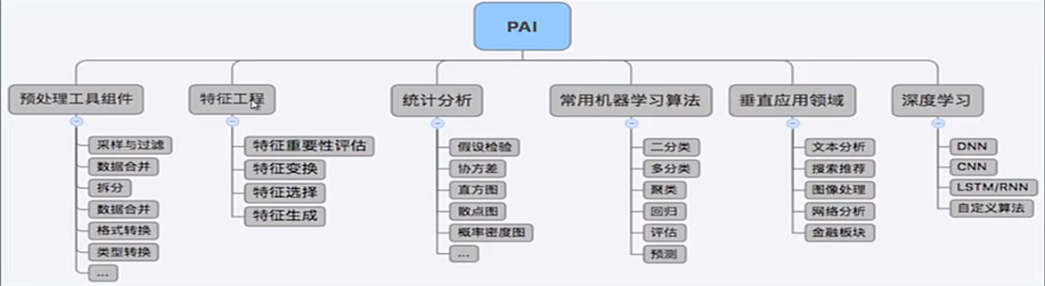
PAI支持的算法
PAI深度学习框架
离线模型、在线预测
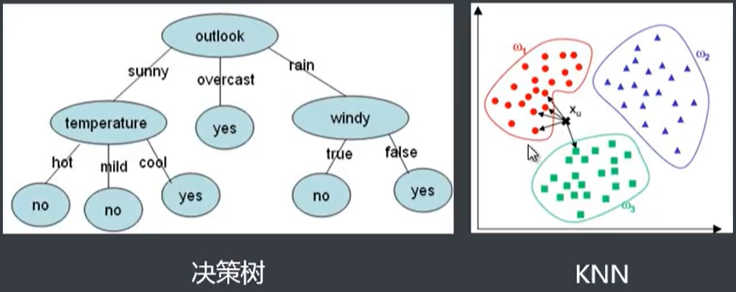
三、分类算法 KNN
分类算法通过对已知类别训练集的分析,从中发现分类规则,以此预测新数据的类别。分类算法的应用非常广泛,银行风险评估、客户类别分类、文本检索和搜索引擎分类、安全领域中的入侵检测以及软件项目中的应用等。
按原理分类:
■基于统计的:如贝叶斯分类
■基于规则的:如决策树算法
■基于神经网络的:神经网络算法
■基于距离的: KNN ( K最近邻)
常用评估指标:
■精确率:预测结果与实际结果的比例
■召回率:预测结果中某类结果的正确覆盖率
■F1-Score :统计量,综合评估分类模型,取值在0-1之间
KNN

实现步骤




KNN优点
■原理简单,容易理解,容易实现
■重新训练代价较低
■时间、空间复杂度取决于训练集(一般不算太大)
KNN缺点
■KNN属于lazy learning算法,得到结果的及时性差
■k值对结果影响大(试想下k=1和k=N的极端情况)
■不同类记录相差较大时容易误判
■样本点较多时,计算量较大
■相对于决策树,结果可解释性不强
应用流程
四、聚类算法 K-Means
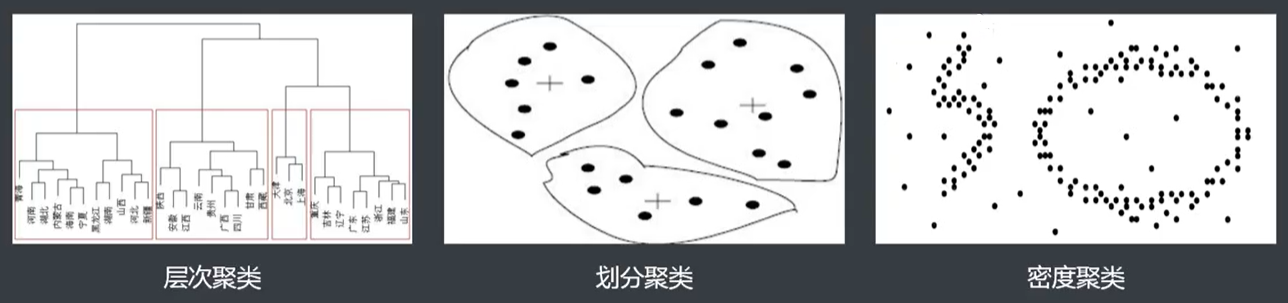
聚类:就是将相似的事物聚集在一起 ,而将不相似的事物划分到不同的类别的过程。它是一种探索性的分析,不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。
常见算法:
层次聚类、划分聚类、基于密度的聚类
K-Means

实现步骤

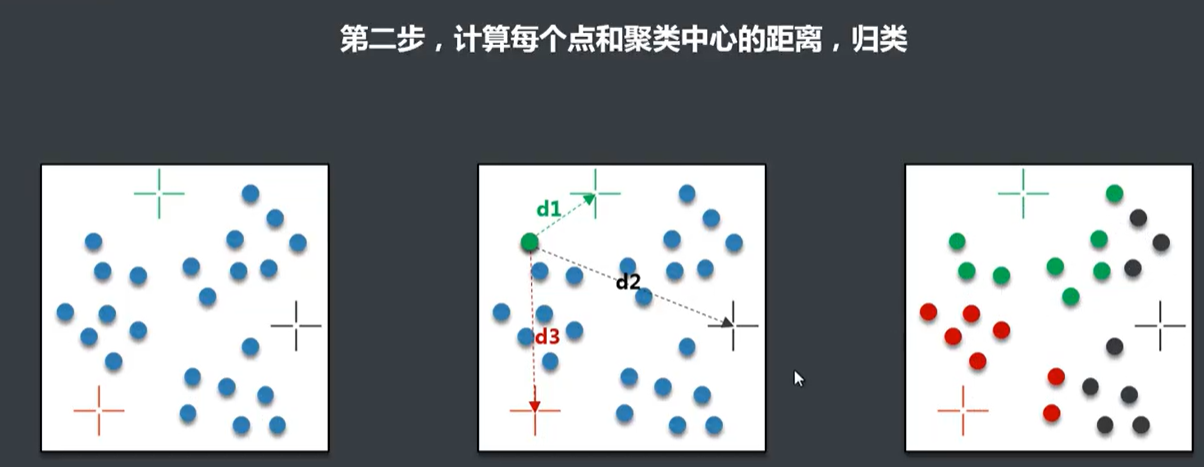
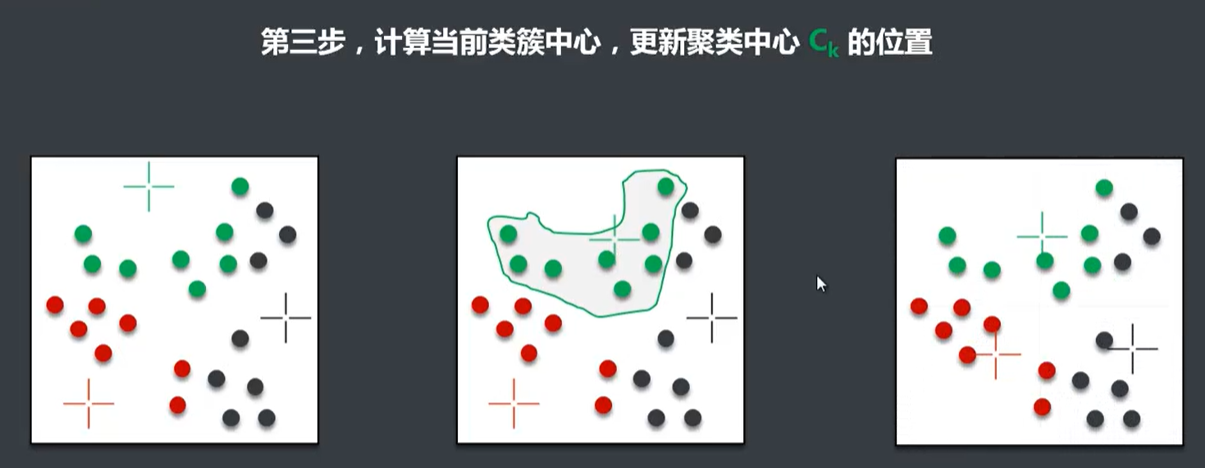
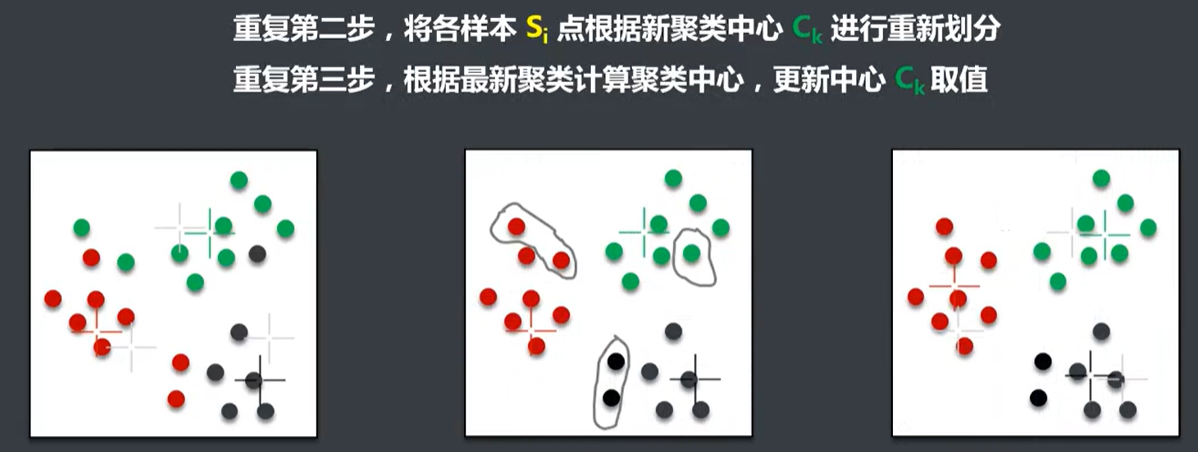
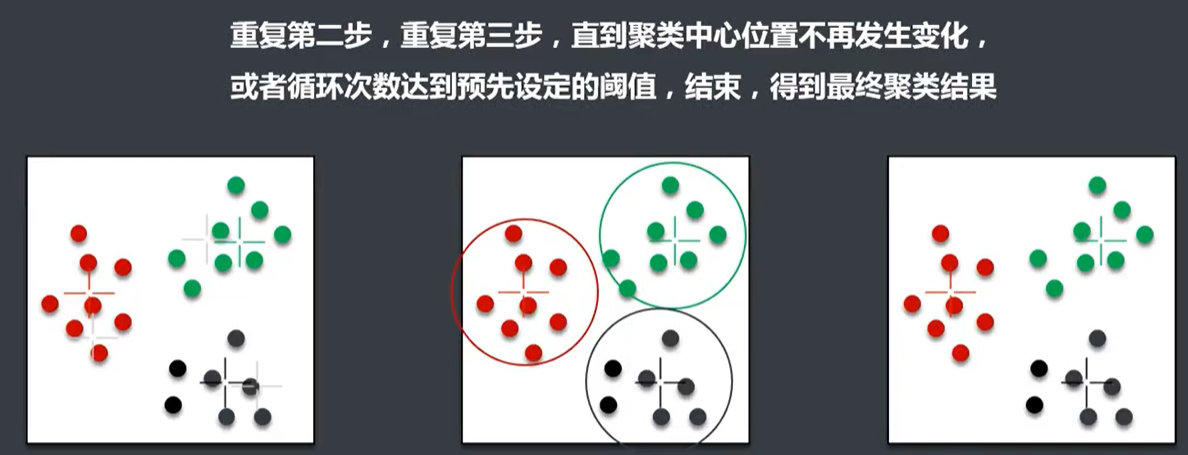

K-Means优点
■原理简单,容易理解,容易实现
■聚类结果容易解释
■聚类结果相对较好
K-Means缺点:
■分类个数k需要事先指定,且指定的k值不同,聚类结果相差较大
■初始的k个类簇中心对最终结果有影响,选择不同,结果可能会不同
■能识别的类簇仅为球状,非球状的聚类效果很差
■样本点较多时,计算量较大
■对异常值敏感,对离散值需要特殊处理
应用流程

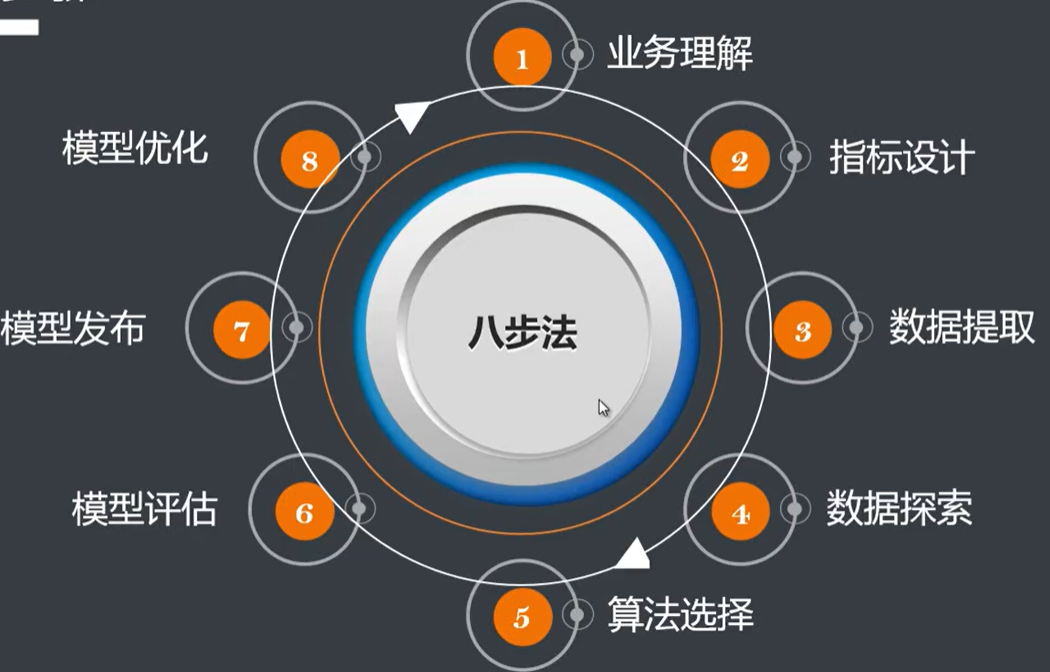
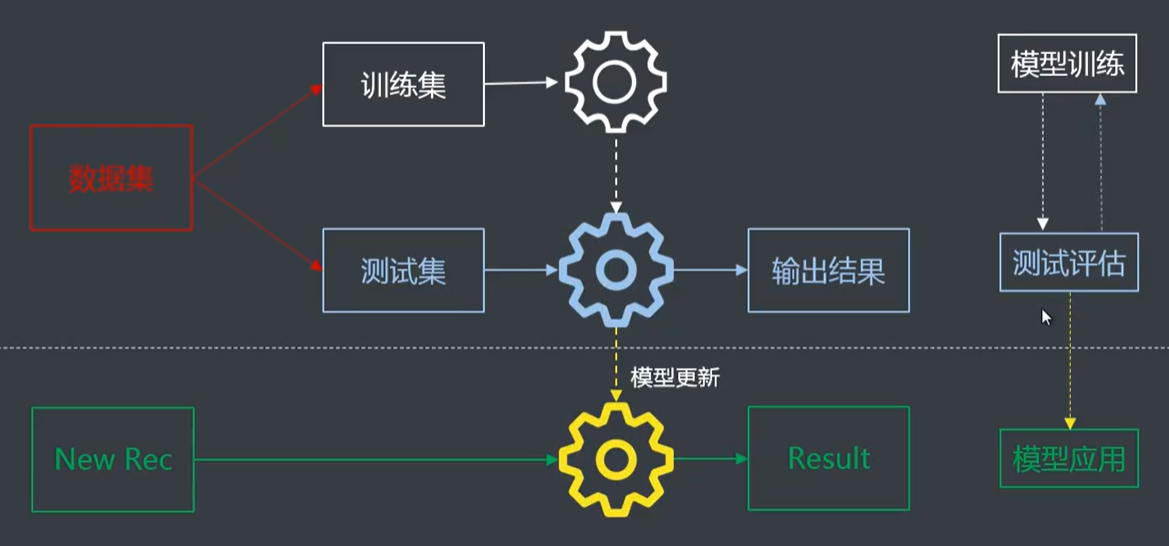
五、机器学习是常用流程
1.CRISP-DM
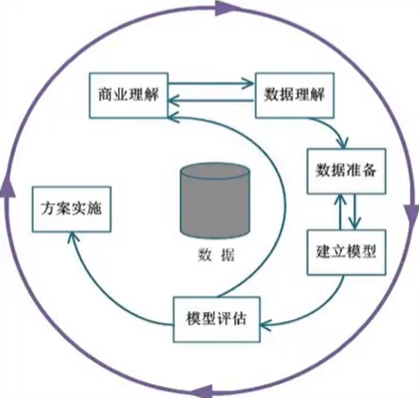
CRISP-DM (cross-industry standard process for data mining),即为”跨行业数据挖掘标准流程"。此KDD过程模型于1999年欧盟机构联合起草。为KDD提供了一个完整的过程描述。
业务理解-- Business Understanding
理解项目目标,理解业务需求,并转换成技术需求
数据理解-- Data Understanding
数据搜集,熟悉数据,识别质量,了解数据大概属性
数据准备-- Data Preparation
构造最终输入数据集,包括选择、转换、清洗等
数据建模-- Modeling
选择、应用不同模型、算法,调整参数到最优
模型评估-- Evaluation
评估模型,确保可完成业务目标
方案实施-- Deployment
2.SEMMA
Sample :数据采样
从总体数据中采样,使用合适的采样方法,同时注意数据质量
Explore :数据探索
通过探索式数据分析、可视化等技术发现数据的特征、特征之间的相互关系和影响等
Modify :问题明确、数据调整、技术选择
将模糊的问题明确化,调整所需数据集,进步明确所需要使用的技术手段
Model :模型研发、知识发现
选择多种合适的算法、模型等技术手段,同时调整、优化相关参数
Assess :模型和知识的解释和评价
评估模型效果,从多个备选结果中选择最合适的,并对模型进行针对业务的解释和应用
3.实施步骤