1,爬取指定用户发表的文章前50页,不足50页则全部爬取,提取标题,摘要,文章链接,提交详情;
代码如下:
import pymssql import requests from lxml import etree import re import time headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } # 博客园我的文章(标题,摘要,文章链接,提交详情) # 连接sql server数据库 conn = pymssql.connect(host='127.0.0.1', user='sa', password='root', database='a', charset='utf8') cursor = conn.cursor() # 创建数据表id设为主键自增 cursor.execute(""" if object_id('years','U') is not null drop table years create table years( id int not null primary key IDENTITY(1,1), title varchar(500), descs varchar(500), href varchar(500), postDesc varchar(500) ) """) conn.commit() # 插入数据的函数 def insert_sqlserver(data): cursor.executemany( "insert into years(title,descs,href,postDesc) VALUES(%s,%s,%s,%s)",data ) conn.commit() # 爬取数据的函数 def get_all(url): try: res = requests.get(url,headers=headers) response = etree.HTML(res.text) titles = response.xpath('//a[@class="postTitle2"]/text()') descs = response.xpath('//div[@class="c_b_p_desc"]/text()') hrefs = response.xpath('//a[@class="c_b_p_desc_readmore"]/@href') postdescs = response.xpath('//div[@class="postDesc"]/text()') data = [] for title,desc,href,postdesc in zip(titles,descs,hrefs,postdescs): # 追加要使用小括号,不能使用中括号,sql server提示只接受元组类型 data.append((title.strip(),desc.strip(),href.strip(),postdesc.strip())) if not data: return None print(data) insert_sqlserver(data) return True except Exception as e: print(e) if __name__ == '__main__': for i in range(1,50): # 在此输入要爬取用户胡主页url,页数用格式化输入 url = 'https://www.cnblogs.com/jiyu-hlzy/default.html?page={}'.format(i) if not get_all(url): break # 设置等待时间,减少服务器压力,做一个善良的爬虫 time.sleep(2) print('爬取完成') conn.close()
数据库展示:
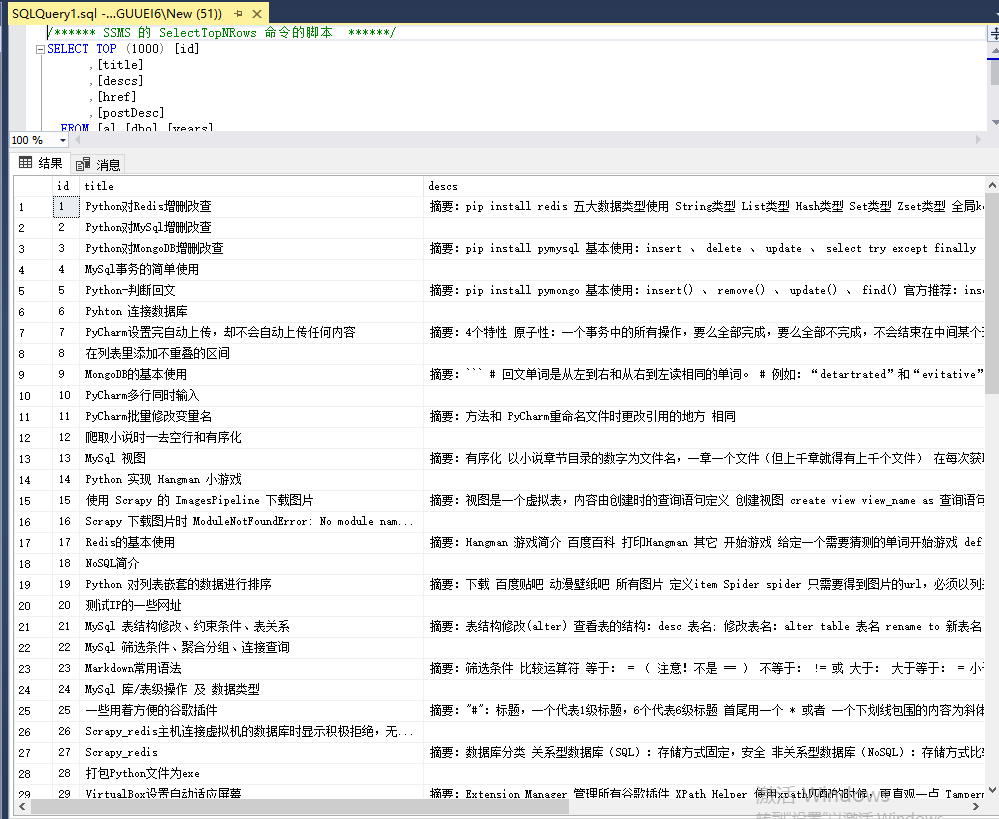
2,爬取用户指定标签的所有文章内容,提取标题,内容,发表时间,阅读量,评论量:
代码如下:
import requests import pymssql from lxml import etree import re """ 标题,内容,发表时间,阅读量,评论量。 """ headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' } # 连接sql server数据库 conn = pymssql.connect(host='127.0.0.1', user='sa', password='root', database='a', charset='utf8') cursor = conn.cursor() cursor.execute(""" if object_id('pk','U') is not null drop table pk create table pk( id int not null primary key IDENTITY(1,1), title varchar(500), contents text, create_time varchar(500), view_count varchar(500), comment_count varchar(500) ) """) conn.commit() # 写入数据库 def insert_sqlserver(data): cursor.executemany( "insert into pk(title,contents,create_time,view_count,comment_count) VALUES(%s,%s,%s,%s,%s)",data ) conn.commit() # 获取数据 def get_all(url): res = requests.get(url,headers=headers) response = etree.HTML(res.text) # 获取详情页路由 detail_urls = response.xpath('//a[@class="entrylistItemTitle"]/@href') # 获取点赞/评论数量 # postfootss = response.xpath('//p[@class="postfoot"]/text()') view_counts = re.findall('阅读 ((.*?))',res.text,re.S) comment_counts = re.findall('评论 ((.*?))',res.text,re.S) # print(detail_urls) data = [] for detail_url,view_count,comment_count in zip(detail_urls,view_counts,comment_counts): res = requests.get(detail_url,headers=headers) response = etree.HTML(res.text) title = response.xpath('//a[@id="cb_post_title_url"]/text()')[0] content = response.xpath('//div[@id="cnblogs_post_body"]')[0] div_str = etree.tounicode(content,method='html') create_time = response.xpath('//span[@id="post-date"]/text()')[0] data.append((title.strip(),div_str.strip(),create_time.strip(),view_count.strip(),comment_count.strip())) print(title.strip(),create_time.strip(),view_count.strip(),comment_count.strip()) # print(data) # print(type(data[0])) insert_sqlserver(data) if __name__ == '__main__': # 在此输入指定标签的url url = 'https://www.cnblogs.com/vuenote/category/1266651.html' get_all(url)
数据库展示:

done