本文爬取的字段,项目名称,发布时间,项目周期,应用领域,最低报价,最高报价,技术类型
1,items中定义爬取字段。
import scrapy class KaiyuanzhongguoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() name = scrapy.Field() publishTime = scrapy.Field() cycle = scrapy.Field() application = scrapy.Field() budgetMinByYuan = scrapy.Field() budgetMaxByYuan = scrapy.Field() ski = scrapy.Field()
2, 爬虫主程序
# -*- coding: utf-8 -*- import scrapy import json from kaiyuanzhongguo.items import KaiyuanzhongguoItem class KyzgSpider(scrapy.Spider): name = 'kyzg' # allowed_domains = ['www.xxx.com'] base_url = 'https://zb.oschina.net/project/contractor-browse-project-and-reward?pageSize=10¤tPage=' start_urls = ['https://zb.oschina.net/project/contractor-browse-project-and-reward?pageSize=10¤tPage=1'] def parse(self, response): result = json.loads(response.text) totalpage = result['data']['totalPage'] for res in result['data']['data']: item = KaiyuanzhongguoItem() item['name'] = res['name'] item['publishTime'] = res['publishTime'] item['cycle'] = res['cycle'] item['application'] = res['application'] item['budgetMinByYuan'] = res['budgetMinByYuan'] item['budgetMaxByYuan'] = res['budgetMaxByYuan'] skillList = res['skillList'] skill = [] item['ski'] = '' if skillList: for sk in skillList: skill.append(sk['value']) item['ski'] = ','.join(skill) yield item for i in range(2,totalpage+1): url_info = self.base_url+str(i) yield scrapy.Request(url=url_info,callback=self.parse)
3,数据库设计
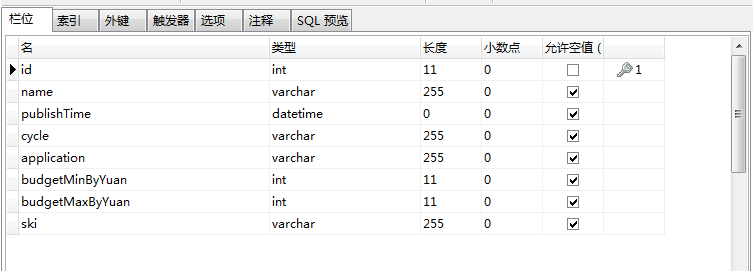
4,pipelines.py文件中写入mysql数据库
# 写入mysql数据库 import pymysql class KaiyuanzhongguoPipeline(object): conn = None mycursor = None def open_spider(self, spider): self.conn = pymysql.connect(host='172.16.25.4', user='root', password='root', db='scrapy') self.mycursor = self.conn.cursor() def process_item(self, item, spider): print(':正在写数据库...') sql = 'insert into kyzg VALUES (null,"%s","%s","%s","%s","%s","%s","%s")' % ( item['name'], item['publishTime'], item['cycle'], item['application'], item['budgetMinByYuan'], item['budgetMaxByYuan'], item['ski']) bool = self.mycursor.execute(sql) self.conn.commit() return item def close_spider(self, spider): print('写入数据库完成...') self.mycursor.close() self.conn.close()
5,settings.py文件中设置请求头和打开下载管道
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36' ITEM_PIPELINES = { 'kaiyuanzhongguo.pipelines.KaiyuanzhongguoPipeline': 300, }
6,运行爬虫
scrapy crawl kyzg --nolog
7,查看数据库是否写入成功

done。