https://www.cnblogs.com/fanling999/p/5857122.html
一、相关性矩阵计算:
[1] 加载数据:
>data = read.csv("231-6057_2016-04-05-ZX_WD_2.csv",header=FALSE)
说明:csv格式的数据,header=FALSE 表示没有标题,即数据从第一行开始。
[2] 查看导入数据的前几行,
>head(data)

[3] 删除数据的7,8列,都是0
>data = data[1:6]
>head(data)
[4] 计算相关性矩阵(可以自己指定采用的方法,"pearson", "kendall", "spearman")
>cor_matr = cor(data)
>cor_matr

二 相关系数的显著性水平(Correlation significance levels (p-value))
使用Hmisc 包,不仅可以计算相关性矩阵,还可以计算对应的显著性水平
[1] 安装包 Hmisc (依赖包也会一并安装,lib代表安装包的路径)
>install.packages("Hmisc",lib="E:/Program Files/R/R-3.3.0/library/")
[2] 加载包
>library(Hmisc)
[3] 计算相关性和显著水平 (as.matrix(data) 表示将data转换成矩阵)
>rcorr(as.matrix(data))
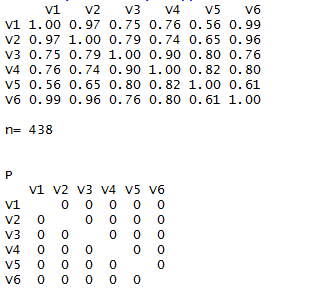
输出说明:
r :第一个矩阵为相关性矩阵
n : 处理数据的总记录数(行数)
P : 显著性水平矩阵(越小说明越显著)
三、可视化相关性分析
- symnum() function
- corrplot() function to plot a correlogram
- scatter plots
- heatmap
[1] 使用 symnum() 函数实现可视化 (cor_matr 是我们上文中cor()函数计算出来的相关性矩阵)
>symnum(cor_matr)

符号说明:在输出的最后一行,说明了符号的意义,例如 [0.9 , 0.95) 这个区间使用 * 表示。其他符号类似
[2] 使用 corrplot() 函数实现可视化(这里需要使用到corrplot包,没有安装的需要安装)
> library(corrplot)
>corrplot(cor_matr, type="upper", order="hclust", tl.col="black", tl.srt=45)
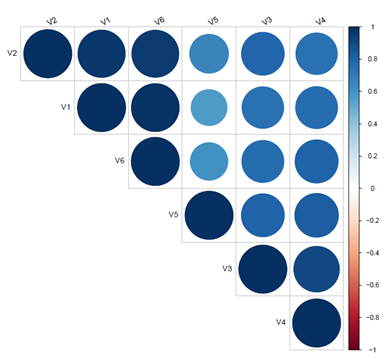
输出说明:用不同颜色表示了相关性的强度,根据最右边的颜色带来看,越接近蓝色说明相关性越高。其中圆形的大小也说明了行惯性的大小。
[3] 使用 PerformanceAnalytics 包进行可视化
>library(PerformanceAnalytics)
>chart.Correlation(data,histogram = TRUE,pch=19)
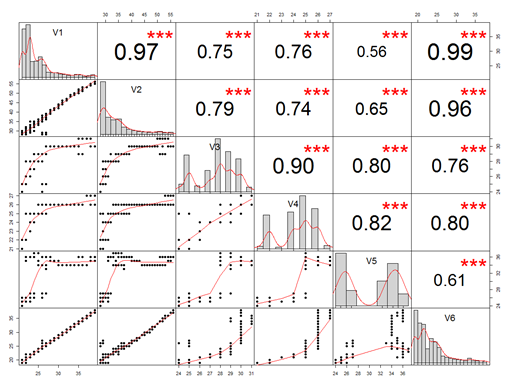
输出说明:
-
- 对角线给出了变量自身的分布
- 下三角形(对角线的左下方),给出了两个属性的散点图,可以看到第二行第一列的散点图显示出v1和v2具有很高的线性相关性
- 上三小形(对角线的右上方),数字表示连个属性的相关性值,型号表示显著程度(星星越多表明越显著)
[4] heatmap 可视化
>col = colorRampPalette(c("blue", "white", "red"))(20)
>heatmap(x = cor_matr, col = col, symm = TRUE)
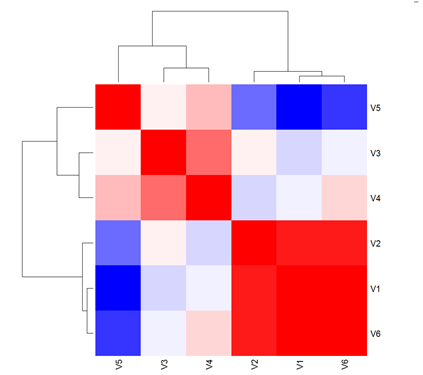
说明:第一行是制作调色板,红色表示相关性最高。第二行参数说明,x: 相关性矩阵(前文已经计算),col: 调色板,symm: 以对称矩阵的形式显示(可以看到画出来的图是中心对称的,不过前提是输入的矩阵是方阵)
参考:
[1] Correlation matrix : A quick start guide to analyze, format and visualize a correlation matrix using R software
[2] Significance of the Correlation Coefficient
http://janda.org/c10/Lectures/topic06/L24-significanceR.htm
[3] Installing R packages