前言
最近在学习MySQL的存储引擎和索引的知识。看了许多篇介绍MyISAM和InnoDB的索引的例子,都能理解。
像这张索引图:
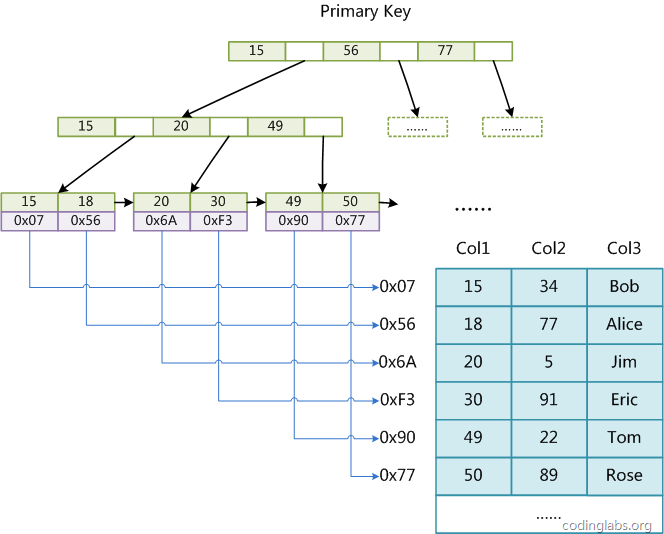
PS:该图来自大神张洋的《MySQL索引背后的数据结构及算法原理》一文。
但许多文章讲述的都是单列索引,我很好奇联合索引对应的结构图是怎样的。
疑惑:联合索引的结构是怎样的
比方说联合索引 (col1, col2,col3),我知道在逻辑上是先按照col1进行排序再按照col2进行排序最后再按照col3进行排序。因此如果是select * from table where col1 = 1 and col3 = 3的话,只有col1的索引部分能生效。但是其物理结构上这个联合索引是怎样存在的,我想不懂。
解答:联合索引的结构
上网查阅了许多资料,总算有点眉目了。
假设这是一个多列索引(col1, col2,col3),对于叶子节点,是这样的:
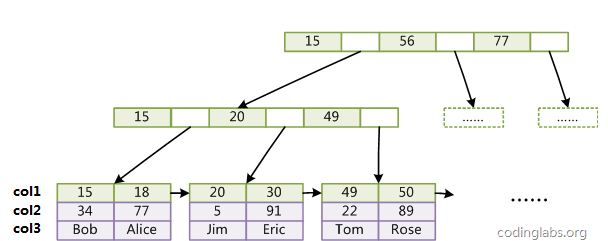
PS:该图改自《MySQL索引背后的数据结构及算法原理》一文的配图。
也就是说,联合索引(col1, col2,col3)也是一棵B+Tree,其非叶子节点存储的是第一个关键字的索引,而叶节点存储的则是三个关键字col1、col2、col3三个关键字的数据,且按照col1、col2、col3的顺序进行排序。
配图可能不太让人满意,因为col1都是不同的,也就是说在col1就已经能确定结果了。自己又画了一个图(有点丑),col1表示的是年龄,col2表示的是姓氏,col3表示的是名字。如下图:
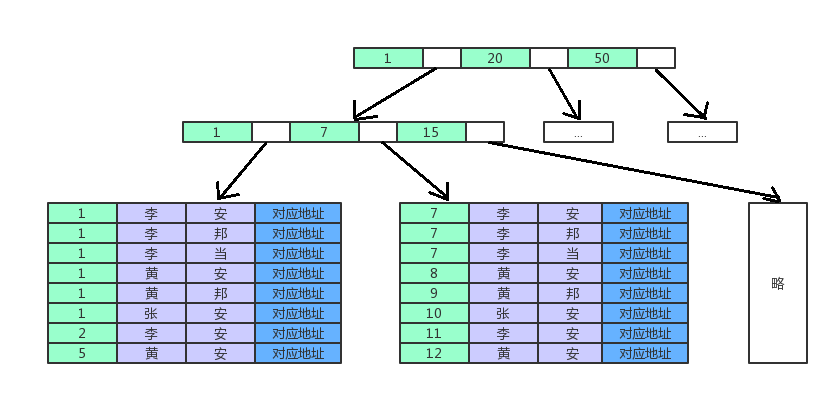
PS:对应地址指的是数据记录的地址。
如图,联合索引(年龄, 姓氏,名字),叶节点上data域存储的是三个关键字的数据。且是按照年龄、姓氏、名字的顺序排列的。
因此,如果执行的是:
select * from STUDENT where 姓氏='李' and 名字='安';
或者
select * from STUDENT where 名字='安';
那么当执行查询的时候,是无法使用这个联合索引的。因为联合索引中是先根据年龄进行排序的。如果年龄没有先确定,直接对姓氏和名字进行查询的话,就相当于乱序查询一样,因此索引无法生效。因此查询是全表查询。
如果执行的是:
select * from STUDENT where 年龄=1 and 姓氏='李';
那么当执行查询的时候,索引是能生效的,从图中很直观的看出,age=1的是第一个叶子节点的前6条记录,在age=1的前提下,姓氏=’李’的是前3条。因此最终查询出来的是这三条,从而能获取到对应记录的地址。
如果执行的是:
select * from STUDENT where 年龄=1 and 姓氏='黄' and 名字='安';
那么索引也是生效的。
而如果执行的是:
select * from STUDENT where 年龄=1 and 名字='安';
那么,索引年龄部分能生效,名字部分不能生效。也就是说索引部分生效。
因此我对联合索引结构的理解就是B+Tree是按照第一个关键字进行索引,然后在叶子节点上按照第一个关键字、第二个关键字、第三个关键字…进行排序。
最左原则
而之所以会有最左原则,是因为联合索引的B+Tree是按照第一个关键字进行索引排列的。
有助于理解联合索引的一个例子
from csdn论坛:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
最后
这样的解释,参考过别人的文章,自己也有思考过,但并不能确定实际上的结构就是这种。但是,也算是学到了许多东西,像是明白了为什么会有最左原则的存在。
原文链接