简介
Memcached是一个高性能的分布式的内存对象缓存系统,目前全世界不少人使用这个缓存项目来构建自己大负载的网站,来分担数据库的压力,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。
MemCache的工作流程如下:先检查客户端的请求数据是否在memcached中,如有,直接把请求数据返回,不再对数据库进行任何操作;如果请求的数据不在memcached中,就去查数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存一份到memcached中(memcached客户端不负责,需要程序明确实现);每次更新数据库的同时更新memcached中的数据,保证一致性;当分配给memcached内存空间用完之后,会使用LRU(Least Recently Used,最近最少使用)策略加上到期失效策略,失效数据首先被替换,然后再替换掉最近未使用的数据。
Memcached是以守护程序(监听)方式运行于一个或多个服务器中,随时会接收客户端的连接和操作。默认监听端口为11211。
在 Memcached中可以保存的item数据量是没有限制的,只要内存足够 。
Memcached单进程在32位系统中最大使用内存为2G,若在64位系统则没有限制,这是由于32位系统限制单进程最多可使用2G内存,要使用更多内存,可以分多个端口开启多个Memcached进程,最大30天的数据过期时间,设置为永久的也会在这个时间过期,常量REALTIME_MAXDELTA 60*60*24*30控制。
最大键长为250字节,大于该长度无法存储,常量KEY_MAX_LENGTH 250控制.
单个item最大数据是1MB,超过1MB数据不予存储,常量POWER_BLOCK 1048576进行控制.但一般都是存储一些文本,如新闻列表等等,这个值足够了
memcached 用 slab allocator 机制来管理内存(在本专题的后续文章中会专门说这个内存机制的).它是默认的slab大小最大同时连接数是200,通过 conn_init()中的freetotal进行控制,最大软连接数是1024,通过
settings.maxconns=1024 进行控制跟空间占用相关的参数:settings.factor=1.25, settings.chunk_size=48, 影响slab的数据占用和步进方式。
memcached是一种无阻塞的socket通信方式服务,基于libevent库,由于无阻塞通信,对内存读写速度非常之快。
memcached分服务器端和客户端,可以配置多个服务器端和客户端,应用于分布式的服务非常广泛。
memcached作为小规模的数据分布式平台是十分有效果的。
memcached是键值一一对应,key默认最大不能超过128个字节,value默认大小是1M,也就是一个slabs,如果要存2M的值(连续的),不能用两个slabs,因为两个slabs不是连续的,无法在内存中 存储,故需要修改slabs的大小,多个key和value进行存储时,即使这个slabs没有利用完,那么也不会存放别的数据。
memcached已经可以支持C/C++、Perl、PHP、Python、Ruby、Java、C#、Postgres、Chicken Scheme、Lua、MySQL和Protocol等语言客户端。
应用场景
使用Memcache的网站一般流量都是比较大的,为了缓解数据库的压力,让Memcache作为一个缓存区域,把部分信息保存在内存中,在前端能够迅速的进行存取。并且通过memcache的时效expire特性,还可以更简单的完成一些功能,我总结如下:
应用场景一: 缓解数据库压力,提高交互速度。
在开发中不管是基于框架的面向对象开发,还是面向过程开发,数据模型一定是要经过封装后再使用的,这样我们就可以对程序做统一处理,比如在程序开发初期,我们没用memcache或者redis来做缓存,我们把从数据库里面取数据统统使用query($sql)方法来读数据;
/**
* 数据库查询伪代码,仅仅是提供一个思路
* @param string $sql sql语句,比如select * form sc_users;
* @param int $expire 缓存失效时间
* @param int $type 1直接从数据库里面读取,0先走缓存,再走数据库
* @return {[type]} [description]
*/
public function query($sql,$expire=300,$type=0){
if($type == 1){
return '直接从数据库里面取出来';
}
$key = md5($sql); //以md5后的sql作为key
$result = $this -> mem -> get($key);
//如果缓存里面没有
if(empty($result)){
$data = '从数据库里面取到数据';
//放入缓存
$this -> mem -> add($key,$data,MEMCACHE_COMPRESSED,$expire); //$data是个数组,所以要序列化压缩一下
return $data;
}
//如果有的话就直接返回;
return $result;
}
它的一个总原则是将经常需要从数据库读取的数据缓存在memcached中。这些数据也分为几类:
一、经常被读取并且实时性要求不强可以等到自动过期的数据。例如网站首页最新文章列表、某某排行等数据。也就是虽然新数据产生了,但对用户体验不会产生任何影响的场景。
这类数据就使用典型的缓存策略,设置一过合理的过期时间,当数据过期以后再从数据库中读取。当然你得制定一个缓存清除策略,便于编辑或者其它人员能马上看到效果。
二、经常被读取并且实时性要求强的数据。比如用户的好友列表,用户文章列表,用户阅读记录等。
这类数据首先被载入到memcached中,当发生更改(添加、修改、删除)时就清除缓存。在缓存的时候,我将查询的SQL语句md5()得到它的 hash值作为key,结果数组作为值写入memcached,并且将该SQL涉及的table_name以及hash值配对存入memcached中。 当更改了这个表时,我就将与此表相配对的key的缓存全部删除。
三、统计类缓存,比如文章浏览数、网站PV等
此类缓存是将在数据库的中来累加的数据放在memcached来累加。获取也通过memcached来获取。但这样就产生了一个问题,如果memcached服务器down 掉的话这些数据就有可能丢失,所以一般使用memcached的永固性存储,这方面新浪使用memcachedb。
四、活跃用户的基本信息或者某篇热门文章。
此类数据的一个特点就是数据都是一行,也就是一个一维数组,当数据被update时(比如修改昵称、文章的评论数),在更改数据库数据的同时,使用Memcache::replace替换掉缓存里的数据。这样就有效了避免了再次查询数据库。
五、session数据
使用memcached来存储session的效率是最高的。memcached本身也是非常稳定的,不太用担心它会突然down掉引起session数据的丢失,即使丢失就重新登录了,也没啥。
六、冷热数据交互
在做高访问量的sns应用,比如贴吧和论坛,由于其数据量大,往往采用了分表分库的策略,但真正的热数据仅仅是前两三页的100条数据,这时,我们就可以把这100条数据,在写进数据库之后,同时作为memcache的缓存热数据来使用。
通过以上的策略数据库的压力将会被大大减轻。检验你使用memcached是否得当的方法是查看memcached的命中率。有些策略好的网站的命中率可以到达到90%以上。后续本专题也会讨论一下memcache的分布式算法,提高其命中率;
应用场景二: 秒杀功能。
其实,本场景严格的说应该也属于场景一,单独拎出来说是由于其广泛的应用性。
一个人下单,要牵涉数据库读取,写入订单,更改库存,及事务要求, 对于传统型数据库来说,压力是巨大的。
可以利用 memcached 的 incr/decr 功能, 在内存存储 count 库存量, 秒杀 1000 台每人抢单主要在内存操作,速度非常快,抢到 count < =1000 的号人,得一个订单号,这时再去另一个页面慢慢支付。
应用场景三:中继 MySQL 主从延迟数据
MySQL 在做 replication 时,主从复制之间必然要经历一个复制过程,即主从延迟的时间.
尤其是主从服务器处于异地机房时,这种情况更加明显.
比如facebook 官方的一篇技术文章,其加州的主数据中心到弗吉尼亚州的主从同步延期达到70ms;
考虑如下场景:
①: 用户 U 购买电子书 B, insert into Master (U,B);
②: 用户 U 观看电子书 B, select 购买记录[user=’A’,book=’B’] from Slave.
③: 由于主从延迟,第②步中无记录,用户无权观看该书.
这时,可以利用 memached 在 master 与 slave 之间做过渡(如下图):
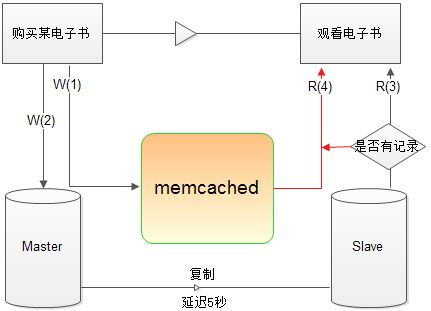
①: 用户 U 购买电子书 B, memcached->add(‘U:B’,true)
②: 主数据库 insert into Master (U,B);
③: 用户 U 观看电子书 B, select 购买记录[user=’U’,book=’B’] from Slave.
如果没查询到,则 memcached->get(‘U:B’),查到则说明已购买但 Slave 延迟.
④: 由于主从延迟,第②步中无记录,用户无权观看该书.
不适用memcached的业务场景
- 缓存对象的大小大于1MB
Memcached本身就不是为了处理庞大的多媒体(large media)和巨大的二进制块(streaming huge blobs)而设计的。 - key的长度大于250字符(所以我们把一些key先md5再存储)。
- 应用运行在不安全的环境中Memcached为提供任何安全策略,仅仅通过telnet就可以访问到memcached。如果应用运行在共享的系统上,需要着重考虑安全问题。
- 业务本身需要的是持久化数据。
Memcache的安全
只说一下思路:
把memcached的端口给禁止掉(这时只能本ip访问),让其他ip的使用者只能通过对外开放的80端口访问PHP脚本文件,再通过PHP的脚本文件去访问memcache;
iptables -a input -p 协议 -s 可以访问ip -dport 端口 -j ACCEPT
扩展阅读
Memcache应用场景介绍,说明[zz]:
http://www.cnblogs.com/literoad/archive/2012/12/23/2830178.html