3.1、分片查询方式
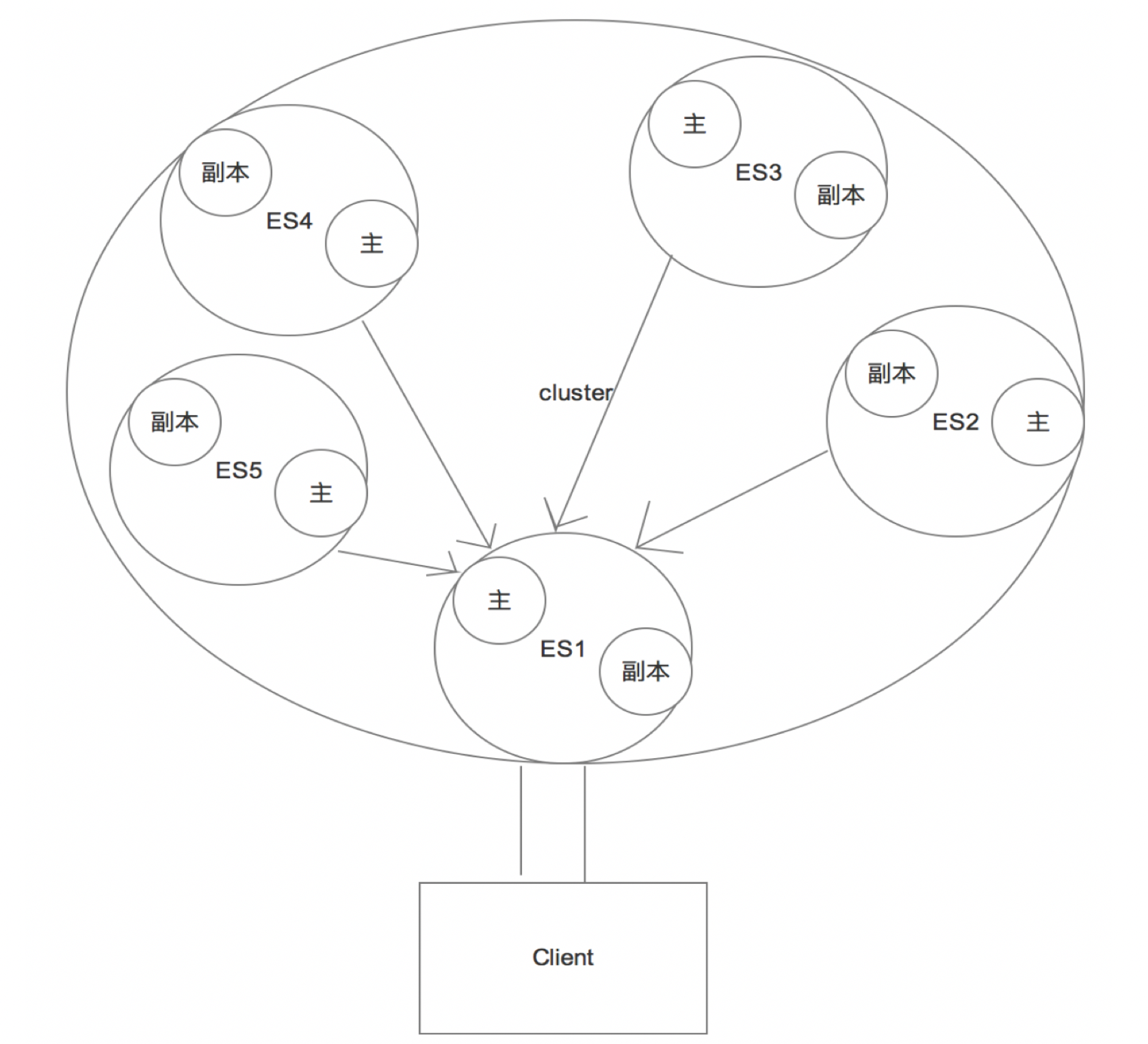

但是问题来了,当我们的客户端做查询的时候,程序会向主分片发送请求还是副本发送请求?
还是说直接去集群上随机找一台机器查询,还是在这个机器里面在随机的找到分片和副本查询?
【注意】:
默认情况下是随机查询的
这种随机的方式其实效率并不高,
1查询阶段
(1):客户端发送一个检索请求给node3,此时node3会创建一个空的优先级队列并且配置好分页参数from与size。
(2):node3将检所请求发送给index中的每一个shard(primary 和 replica),每一个在本地执行检索,并将结果添加到本地的优先级队列中;
(3):每个shard返回本地优先级序列中所记录的_id与score值,并发送node3。Node3将这些值合并到自己的本地的优先级队列中,并做全局的排序。
2获取阶段
(1):node 3获取了所有待检索数据的定位之后,发送一个mget的请求给与数据相关的shard。
(2):每个收到node 3的get请求的shard将读取相关文档_source中的内容,并将它们返回给node 3。
(3):当node 3获取到了所有shard返回的文档后,node 3将它们合并成一条汇总的结果,返回给客户端。

我们通过上面的查询方式可以了解到,如果我们直接将客户端定位到指定的机器上查询,就少去了中间的来回复制的步骤,这样在检索大量数据的时候,网络的IO也得到了提升
其实,在elasticsearch的查询阶段,我们可以做很多的优化措施,比如控制我们的分片查询方式:
Es会将数据均衡的存储在分片中,我们可以指定es去具体的分片或节点中查询从而进一步的实现es极速查询。 1:randomizeacross shards 随机选择分片查询数据,es的默认方式 2:_local 优先在本地节点上的分片查询数据然后再去其他节点上的分片查询,本地节点可以减少跨网络的IO问题,但有可能造成负载不均问题 3:_primary 只在主分片中查询不去副本查 4:_primary_first 优先在主分片中查,如果主分片挂了则去副本查 5:_only_node[已经被移除] 只在指定id的节点中的分片中查询 6:_prefer_node 优先在指定你给节点中查询 7:_shards 在指定分片中查询 8:_only_nodes 可以自定义去指定的多个节点查询,es不提供此方式需要改源码。
/** * 分片查询方式 * */ @Test public void searchType(){ SearchRequestBuilder builder = client.prepareSearch("school").setTypes("student"); SearchResponse searchResponse = builder.setQuery(QueryBuilders.matchQuery("name", "于谦")) // .setPreference("_local") // .setPreference("_primary") // .setPreference("_only_nodes:*") // .setPreference("_prefer_nodes:jnrN6IYURTKYPE_ZYQqFDg") // .setPreference("_shards:0,1,2")//TODO 可以提高查询效率 // .setPreference("randomizeacross") .get();//指定查询方式 SearchHits hits = searchResponse.getHits(); System.out.println("查询的结果数量有"+hits.getTotalHits()+"条"); System.out.println("结果中最高分:"+hits.getMaxScore()); // 遍历每条数据 Iterator<SearchHit> iterator = hits.iterator(); while(iterator.hasNext()){ SearchHit searchHit = iterator.next(); System.out.println("所有的数据JSON的数据格式:"+searchHit.getSourceAsString()); System.out.println("每条得分:"+searchHit.getScore()); // 获取每个字段的数据 System.out.println("id:"+searchHit.getSource().get("id")); System.out.println("name:"+searchHit.getSource().get("name")); System.out.println("age:"+searchHit.getSource().get("age")); System.out.println("**********************************************"); for(Iterator<SearchHitField> ite = searchHit.iterator(); ite.hasNext();){ SearchHitField next = ite.next(); System.out.println(next.getValues()); } } }