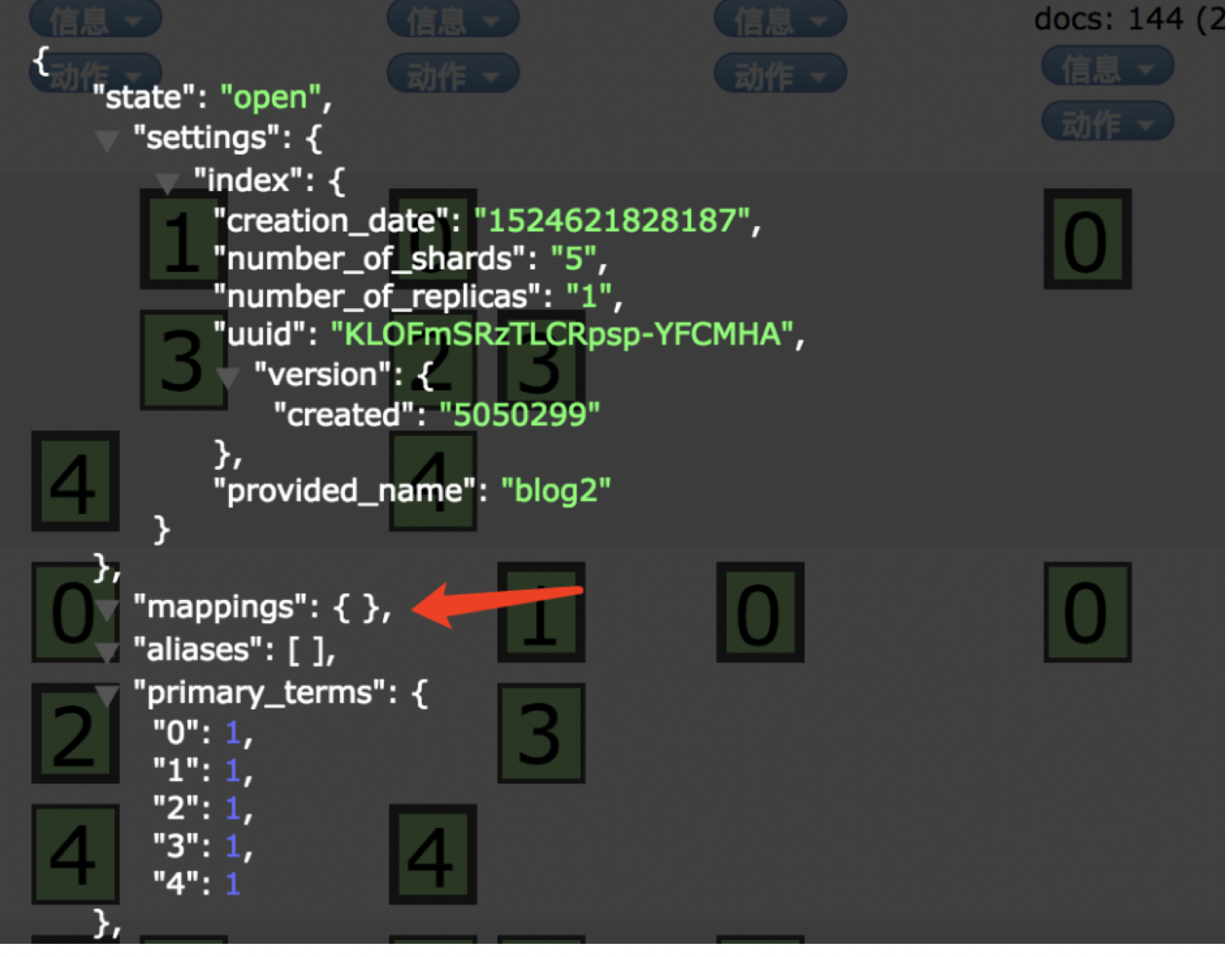
/** * 创建索引 * */ @Test public void createIndex(){ // 创建索引 CreateIndexResponse blog2 = client.admin().indices().prepareCreate("blog2").get(); System.out.println(blog2.toString()); }
默认创建好索引,mappings为空
1.7.2: 删除索引
/** * 删除索引 * */ @Test public void deleteIndex(){ // 删除索引 client.admin().indices().prepareDelete("blog2").get(); }
为什么要进行手动的映射?
在实际生产中经常会出现精度损失的现象,往往就是因为没有进行正确的索引映射或者压根就没进行索引映射
Elasticsearch最开始索引文档A,其中的一个字段是一个数字,是整数;通过自动类型猜测,并设置类型为整型(integer)或者长整型;
然后在索引另一个文档B,B文档在同一个字段中存储的是浮点型;那么这个时候elasticsearch就会把B文档中的小数删除,保留整数部分;
这样就会导致数据的不准确!
如果你习惯SQL数据库,或许知道,在存入数据前,需要创建模式来描述数据(schmal);尽管elasticsearch是一个无模式的搜索引擎,可以即时算出数据结构;
但是我们仍然认为由自己控制并定义结构是更好的;而且在实际的生产中,我们也是自己创建映射;
注意:注意创建mapping的时候,索引必须提前存在

{ "settings":{ "nshards":3, "number_of_repli umber_of_cas":1 }, "mappings":{ "dahan":{ "dynamic":"strict", "properties":{ "studentNo":{"type": "string", "store": true}, "name":{"type": "string","store": true,"index" : "analyzed","analyzer": "ik_max_word"}, "male":{"type": "string","store": true}, "age":{"type": "integer","store": true}, "birthday":{"type": "string","store": true}, "classNo":{"type": "string","store": true}, "address":{"type": "string","store": true,"index" : "analyzed","analyzer": "ik_max_word"}, "isLeader": {"type": "boolean", "index": "not_analyzed"} } } }
/**
* 创建索引
* */
2):通过代码创建索引配置信息(有错的情况)
/**
* Created by angel;
*/
public class CreateMappings {
public static void main(String[] args) throws UnknownHostException {
TransportClient client = null;
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("number_of_shards", 3);
map.put("number_of_replicas", 1);
Settings settings = Settings.builder()
.put("cluster.name", "cluster")
.build();
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("hadoop01"), 9300));
System.out.println("========连接成功=============");
XContentBuilder builder = null;
try {
builder = jsonBuilder()
.startObject()
.startObject("dahan").field("dynamic", "true")
.startObject("properties")
.startObject("studentNo").field("type", "string").field("store", "yes").endObject()
.startObject("name").field("type", "string").field("store", "yes").field("analyzer", "ik_max_word").endObject()//.field("analyzer", "ik")
.startObject("male").field("type", "string").field("store", "yes").endObject()//.field("analyzer", "ik")
.startObject("age").field("type", "integer").field("store", "yes").endObject()
.startObject("birthday").field("type", "string").field("store", "yes").endObject()
.startObject("classNo").field("type", "string").field("store", "yes").endObject()
.startObject("address").field("type", "string").field("store", "yes").field("analyzer", "ik_max_word").endObject()
.startObject("isLeader").field("type", "boolean").field("store", "yes").field("index", "not_analyzed").endObject()
.endObject()
.endObject()
.endObject();
PutMappingRequest mapping = Requests.putMappingRequest("sanguo")
.type("dahan")
.source(builder);
UpdateSettingsRequest updateSettingsRequest = new UpdateSettingsRequest();
updateSettingsRequest.settings(map);
client.admin().indices().updateSettings(updateSettingsRequest).actionGet();
client.admin().indices().putMapping(mapping).get();
} catch (Exception e) {
e.printStackTrace();