1:为什么大批量数据集写入Hbase中,需要使用bulkload
- BulkLoad不会写WAL,也不会产生flush以及split。
- 如果我们大量调用PUT接口插入数据,可能会导致大量的GC操作。除了影响性能之外,严重时甚至可能会对HBase节点的稳定性造成影响。但是采用BulkLoad就不会有这个顾虑。
- 过程中没有大量的接口调用消耗性能
- 可以利用spark 强大的计算能力
上面是一个总的执行流程图, 数据生成,HFile转换以及HFile加载, 下面是HFile 的格式, 就是个key value 存储结构,
key 是由行健column family 和限定符指定, 然后再加上key的索引

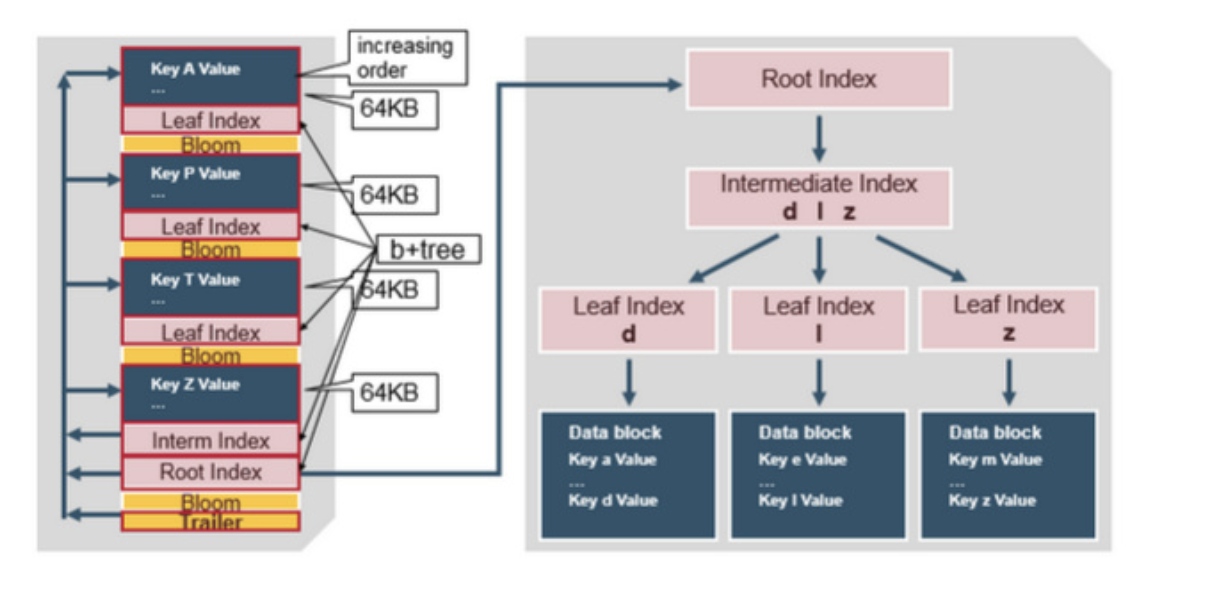

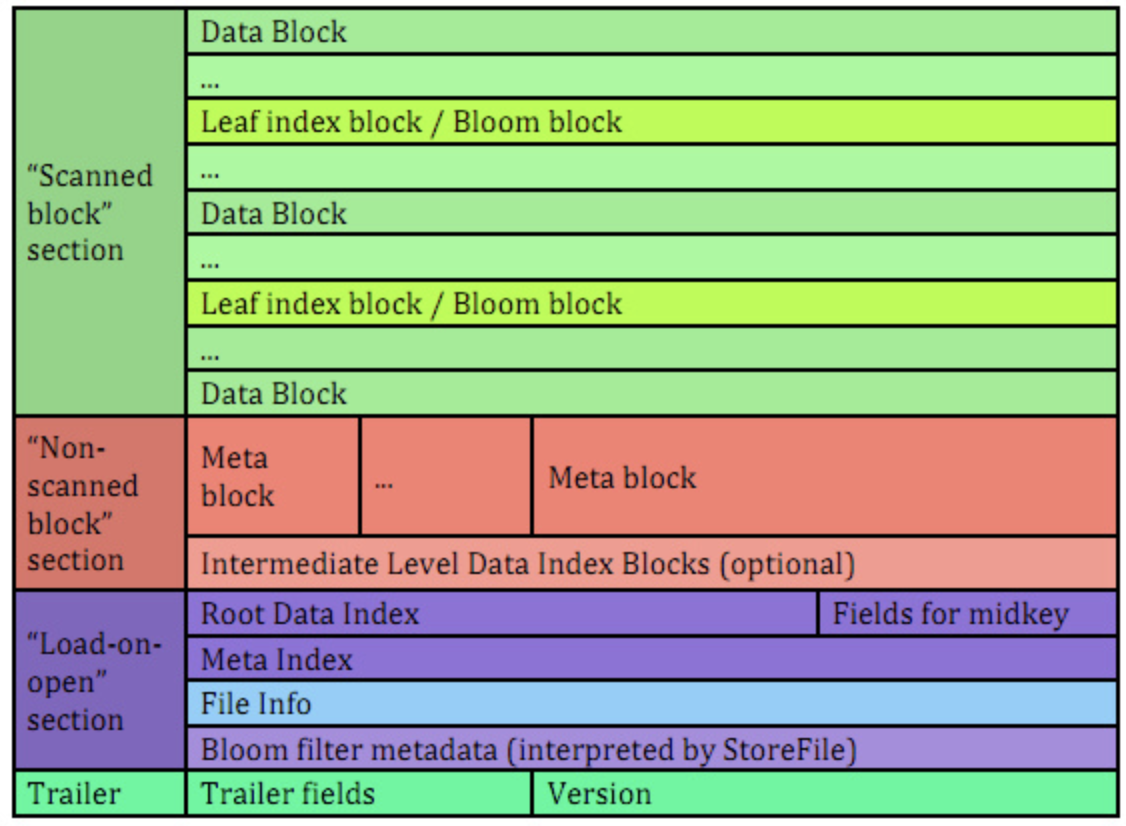
注意:
生成HFile要求Key有序。开始是以为只要行键有序,即map之后,sortByKey就ok,后来HFileOutputFormat一直报后值比前值小(即未排序)。翻了很多鬼佬网站,才发现,这里的行键有序,是要求rowKey+列族+列名整体有序!!!
package hbaseLoad.CommonLoad import java.io.IOException import java.sql.Date import java.util import java.util.concurrent.{Executors, ScheduledExecutorService, TimeUnit} import org.apache.hadoop.fs.Path import org.apache.hadoop.hbase.client._ import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.{HFileOutputFormat2, LoadIncrementalHFiles} import org.apache.hadoop.hbase.{HBaseConfiguration, HColumnDescriptor, HTableDescriptor, KeyValue, TableName} import org.apache.hadoop.hbase.util.Bytes import org.apache.hadoop.mapreduce.Job import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * Created by angel; */ object Hfile { val zkCluster = "hadoop01,hadoop02,hadoop03" val hbasePort = "2181" val tableName = TableName.valueOf("hfile") val columnFamily = Bytes.toBytes("info") def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("Hfile").setMaster("local[*]") conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer"); conf.registerKryoClasses(Array(classOf[D_class])) val sc = new SparkContext(conf) val fileData: RDD[String] = sc.textFile("data") val rdd = fileData.map{ line => val dataArray = line.split("@") val rowkey = dataArray(0)+dataArray(1) val ik = new ImmutableBytesWritable(Bytes.toBytes(rowkey)) val kv = new KeyValue(Bytes.toBytes(rowkey) , columnFamily , Bytes.toBytes("info") , Bytes.toBytes(dataArray(2)+":"+dataArray(3)+":"+dataArray(4)+":"+dataArray(5))) (ik , kv) } // val scheduledThreadPool = Executors.newScheduledThreadPool(4); // scheduledThreadPool.scheduleWithFixedDelay(new Runnable() { // override def run(): Unit = { // println("=====================================") // } // // }, 1, 3, TimeUnit.SECONDS); hfile_load(rdd) } def hfile_load(rdd:RDD[Tuple2[ImmutableBytesWritable , KeyValue]]): Unit ={ val hconf = HBaseConfiguration.create() hconf.set("hbase.zookeeper.quorum", zkCluster); hconf.set("hbase.master", "hadoop01:60000"); hconf.set("hbase.zookeeper.property.clientPort", hbasePort); hconf.setInt("hbase.rpc.timeout", 20000); hconf.setInt("hbase.client.operation.timeout", 30000); hconf.setInt("hbase.client.scanner.timeout.period", 200000); //声明表的信息 var table: Table = null var connection: Connection = null try{ val startTime = System.currentTimeMillis() println(s"开始时间:-------->${startTime}") //生成的HFile的临时保存路径 val stagingFolder = "hdfs://hadoop01:9000/hfile" //将日志保存到指定目录 rdd.saveAsNewAPIHadoopFile(stagingFolder, classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat2], hconf) //开始即那个HFile导入到Hbase,此处都是hbase的api操作 val load = new LoadIncrementalHFiles(hconf) //创建hbase的链接,利用默认的配置文件,实际上读取的hbase的master地址 connection = ConnectionFactory.createConnection(hconf) //根据表名获取表 table = connection.getTable(tableName) val admin = connection.getAdmin //构造表描述器 val hTableDescriptor = new HTableDescriptor(tableName) //构造列族描述器 val hColumnDescriptor = new HColumnDescriptor(columnFamily) hTableDescriptor.addFamily(hColumnDescriptor) //如果表不存在,则创建表 if(!admin.tableExists(tableName)){ admin.createTable(hTableDescriptor) } //获取hbase表的region分布 val regionLocator = connection.getRegionLocator(tableName) //创建一个hadoop的mapreduce的job val job = Job.getInstance(hconf) //设置job名称 job.setJobName("DumpFile") //此处最重要,需要设置文件输出的key,因为我们要生成HFile,所以outkey要用ImmutableBytesWritable job.setMapOutputKeyClass(classOf[ImmutableBytesWritable]) //输出文件的内容KeyValue job.setMapOutputValueClass(classOf[KeyValue]) //配置HFileOutputFormat2的信息 HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator) //开始导入 load.doBulkLoad(new Path(stagingFolder), table.asInstanceOf[HTable]) val endTime = System.currentTimeMillis() println(s"结束时间:-------->${endTime}") println(s"花费的时间:----------------->${(endTime - startTime)}") }catch{ case e:IOException => e.printStackTrace() }finally { if (table != null) { try { // 关闭HTable对象 table.close(); } catch { case e: IOException => e.printStackTrace(); } } if (connection != null) { try { //关闭hbase连接. connection.close(); } catch { case e: IOException => e.printStackTrace(); } } } } }