本文主要是比较三种分布缓存负载均衡的方法,第一种是最简单的将 key的hash值对机器数取模算法,第二种是一致性哈希算法,第三种是淘宝开源的缓存解决方案tair的均衡算法。下面来分析下这三种算法的优缺点。
第一种:传统的数据分布方法,将key的hash值对机器数取模
这个算法的实现非常简单,计算hash(key)/n,n为机器数,得到的值就是该key需要路由到的服务器编号了。
优点:实现简单
缺点:在服务器数量发生变化的时候,缓存会大量失效。
第二种:一致性hash
试想下如果使用传统取模算法。如果有一个key要存到缓存中,根据hash(key)/n (n表示有n台缓存服务器),可以计算出缓存所在的服务器id。这个时候有一台服务器挂掉了,剩下n-1台服务器。这时候,同样一个key,根据hash(key)/(n-1) ,这个时候就命中不了缓存了,基本所有的缓存都会失效,这个情况在线上可能是灾难性的。 一致性hash可以解决部分问题。
通常可以考虑[0,(2^32-1)]为hash值的取值范围。我们可以把取值范围想象成一个闭环,2^32-1 和 0 相连接。如下图所示。
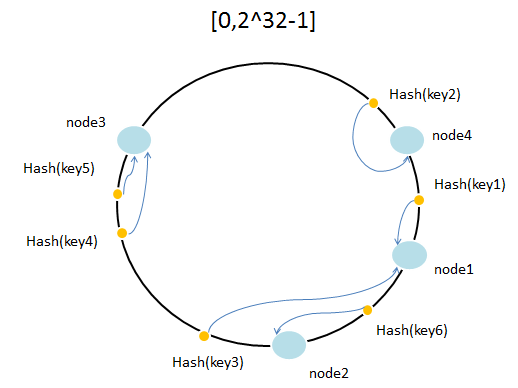
这个时候假设我们有4个缓存服务器节点。(node1~node4) 首先计算这四个值的hash值,并且这四个点占据了闭环的四个位置,如上图所示,这个时候需要根据key来路由缓存服务器,首先计算hash(key)值(这个hash算法需要保证hash(key)的值落在在区间[0,2^32-1]中)。然后我们可以想象这个hash(key)值位于闭环的其中一个点,然后用这个hash(key)依次加一,直到命中其中一个node为止,命中的node就是key需要路由的服务器,如上图,需要找到key2的缓存值所在的服务器,首先计算hash(key2),落在如图的闭环中,然后顺时针找到离这个hash值最近的node,可以看到是node1。key2对应的缓存值就存在node1中。
如果这个时候如果增加了节点node5如下图:
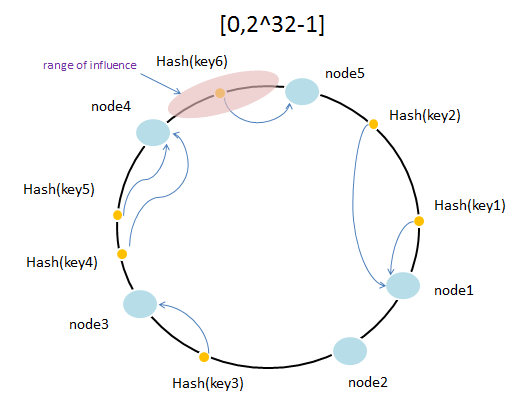
看下缓存失效的情况,如上图,只有hash(key)落在node4~node5之间的key才会有影响,在未增加node5之前落在这个范围的key最终路由到node1,增加node5之后路由到node5了,缓存失效了。除此之外,落在其他范围的hash值就不受影响。如上图,增加node5之后key6原来会路由到node1的,现在路由到node5。而key1不受影响,还是路由到node1。
同理,如果少掉一个节点,还是上图为例,假如这个时候node5失效了,node5失效之前落在node4~node5之间的hash值,会路由到node5,失效之后会路由到node1,也就是原本落在node4~node5之间的hash值失效了。由此可见一致性hash能在节点变动的时候减少缓存失效的比例。
还有一种情况,当cache的数量很少的或者缓存服务器很少的时候,会导致缓存分布不均衡。如下图所示:
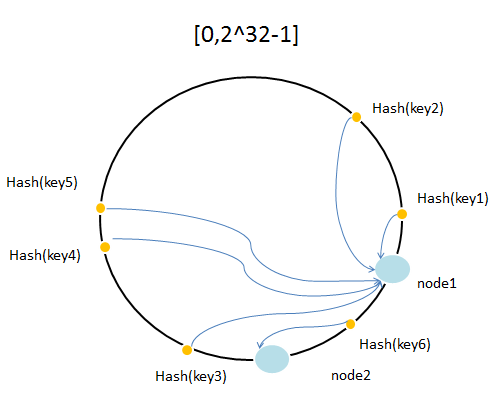
当只有很少节点的时候,例如上图的两个,这个时候就会分配得很不均衡。上图中node1明显承受了较多的压力。这个时候引入一个叫虚拟节点的概念,原理就是增加更多的虚拟节点,让每个节点承受的压力尽量均衡。这些增加的节点并不是真正新增的服务器节点,而是由原来的节点”复制“出来的。例如下图,”复制“了两个新节点,node3,node4。实际上,落到node3,node4的key最终访问的服务器是node2,node1.
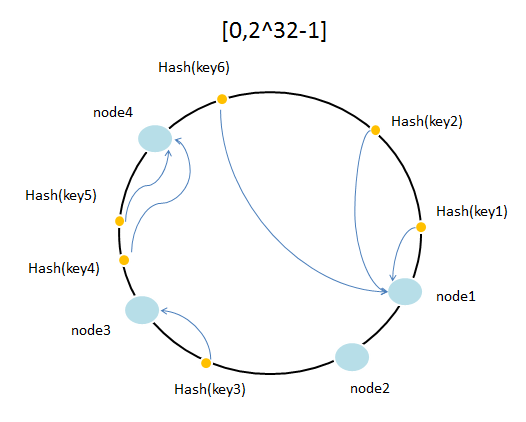
这样就可以把压力尽量分配到各个机器上。另外需要维护一张表格,用来记录虚拟节点指向的真正节点。
优点:相比简单的对机器数取模算法,当节点变动的时候只有相对较少的key失效,实现也相对简单。不需要进行数据迁移,每个服务器是独立的。
缺点:还是会有部分的key失效,如果访问量非常大的时候,如果访问到失效的key的时候,就会直接访问到数据源上面去了,可能会导致数据源直接压挂。
第三种:tair负载均衡算法,构造一张对照表
首先看下如何构建一张对照表。
tair中数据的存储是以bucket为单位的,一个bucket对应一个dateServer,一个dateServer中会有多个bucket。bucket的数目是固定的,这里假设bucket的数量为1024个,并且每个bucket有属于自己的id,依次从0到1023。如下图:

可以看到对key进行hash之后首先会路由到某个bucket然后根据对应关系,再路由到对应的dataServer。
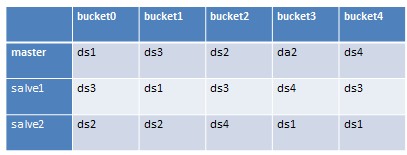
在tair中,你可以设置同一个bucket的备份数目,我们称其中一个bucket为master,其他的备份称为slave。configServer启动的时候会构造三张bucket和dataServer的对照表,分别是hash_table, m_hash_table, d_hash_table,这三张对照表在初始构建的时候都是一样的,但是在dataServer发生增加的时候会暂时不一样,但是最终会趋向一致,三张表分别有什么用处下面会讲到。configServer在构建对照表的时候有两种模式,一种是均衡模式,这种模式会尽量保证每个节点的bucket数目差不多。一种是安全模式,这种模式会尽量保证一份数据以及它的备份分配在不同的区域的服务器上。client通过configServer获取对照表(hash_table)之后,根据(hash(key)%bucket的总数)算出bucket的id并且参照对照表,就能知道这个key对应的dataServer了。对照表的结构大概如下(这里为了简化,一共只有5个bucket,4个dataServer(ds1,ds2,ds3,ds4),这个是初始时的对照表,hash_table, m_hash_table, d_hash_table的内容都是一样的)。
可以看到对key进行hash之后首先会路由到某个bucket然后根据对应关系,再路由到对应的dataServer。
在tair中,你可以设置同一个bucket的备份数目,我们称其中一个bucket为master,其他的备份称为slave。configServer启动的时候会构造三张bucket和dataServer的对照表,分别是hash_table, m_hash_table, d_hash_table,这三张对照表在初始构建的时候都是一样的,但是在dataServer发生增加的时候会暂时不一样,但是最终会趋向一致,三张表分别有什么用处下面会讲到。configServer在构建对照表的时候有两种模式,一种是均衡模式,这种模式会尽量保证每个节点的bucket数目差不多。一种是安全模式,这种模式会尽量保证一份数据以及它的备份分配在不同的区域的服务器上。client通过configServer获取对照表(hash_table)之后,根据(hash(key)%bucket的总数)算出bucket的id并且参照对照表,就能知道这个key对应的dataServer了。对照表的结构大概如下(这里为了简化,一共只有5个bucket,4个dataServer(ds1,ds2,ds3,ds4),这个是初始时的对照表,hash_table, m_hash_table, d_hash_table的内容都是一样的)。
当服务器变化之后configserver是如何重构对照表的?重构对照表的时候,数据是怎么迁移的?
configServer会定时发送心跳包给dataServer,用来检测dataServer是否还存活,如果没有存活的话就会重新构造对照表。或者如果有新加dataServer的话也会重新构造对照表。
当有一个dataServer当机之后,这个机器 上的存储的bucket数据都会丢失,如果是master bucket丢失之后其中一个slave bucket会补上成为master bucket。至于选择哪个slave bucket成为master bucket的是根据slave 上负载的master bucket有没有超标,并且总bucket数有没有超标等标准。举个例子,上图中当ds2失效之后,hash_table, m_hash_table, d_hash_table三个表分别是这样子的。
hash_table :
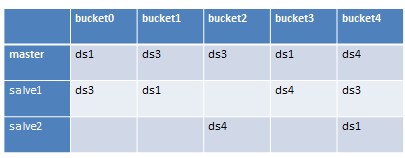
m_hash_table:
d_hash_table:
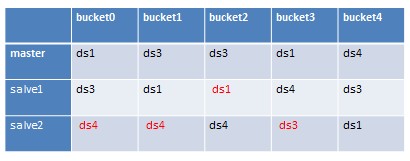
hash_table发送给client,client不至于不能工作,m_hash_table和d_hash_table发送到dataServer,dataServer根据这两张表就可以知道自己是否需要迁移数据和迁移到哪里了。例如这里第一列,第三排,对比两表,可以知道,ds1需要把数据迁移到ds4。
如果是要增加新的dataServer,原理就差不多了,configServer新建对照表,然后把对照表发送到dateServer,然后dataServer再根据新对照表来做数据迁移,完成之后,client就可以使用新的对照表了。
优点:当需要增加机器的时候,不会有key失效。
缺点:实现比较复杂,需要进行数据的迁移。