
前言
本觉 CopyOnWriteArrayList 过于简单,寻思看名字就能知道内部的实现逻辑,所以没有写这篇文章的想法,最近又仔细看了下 CopyOnWriteArrayList 的源码实现,大体逻辑没有意外,不过还是发现很多有意思的地方,固留此篇文章分享之。
看完这篇文章你会了解到:
- CopyOnWriteArrayList 的实现原理,扩容机制。
- CopyOnWriteArrayList 的读写分离,弱一致性。
- CopyOnWriteArrayList 的性能如何。
- CopyOnWriteArrayList 修改元素时,为什么相同值也要重新赋值(作者 Doug Lea 这么写都是有道理的)。
- CopyOnWriteArrayList 在高版本 JDK 的实现有什么不同,为什么。
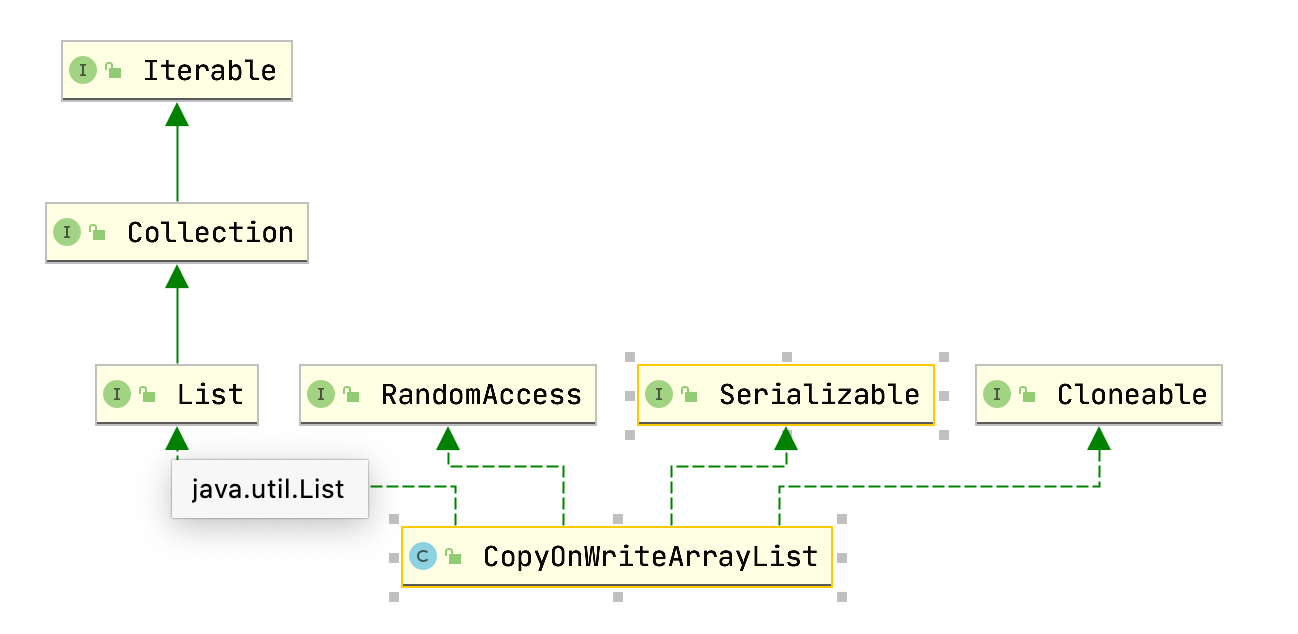
线程安全 List
在 Java 中,线程安全的 List 不止一个,除了今天的主角 CopyOnWriteArrayList 之外,还有 Vector 类和 SynchronizedList 类,它们都是线程安全的 List 集合。在介绍 CopyOnWriteArrayList 之前,先简单介绍下另外两个。
如果你尝试你查看它们的源码,你会发现有点不对头,并发集合不都是在 java.util.concurrent 包中嘛,为什么Vector 类和 SynchronizedList 类 这两个是在 java.util 包里呢?
确实是这样的,这两个线程安全的 List 和线程安全的 HashTable 是一样的,都是比较简单粗暴的实现方式,直接方法上增加 synchronized 关键字实现的,而且不管增删改查,统统加上,即使是 get 方法也不例外,没错,就是这么粗暴。
Vector 类的 get 方法:
// Vector 中的 get 操作添加了 synchronized
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
SynchronizedList 类的 ge t 方法:
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
同学不妨思考一下,其实在 get 方法上添加同步机制也是有原因的,虽然降低了效率,但是可以让写入的数据立即可以被查询到,这也保证了数据的强一致性。另外上面关于 synchronized 简单粗暴的描述也是不够准确的,因为在高版本的 JDK 中,synchronized 已经可以根据运行时情况,自动调整锁的粒度,后面介绍 CopyOnWriteArrayList 时会再次讲到。
CopyOnWriteArrayList
在 JDK 并发包中,目前关于 List 的并发集合,只有 CopyOnWriteArrayList 一个。上面简单介绍了 Vector 和 SynchronizdList 的粗暴实现,既然还有 CopyOnWriteArrayList,那么它一定是和上面两种是有区别的,作为唯一的并发 List,它有什么不同呢?
在探究 CopyOnWriteArrayList 的实现之前,我们不妨先思考一下,如果是你,你会怎么来实现一个线程安全的 List。
- 并发读写时该怎么保证线程安全呢?
- 数据要保证强一致性吗?数据读写更新后是否立刻体现?
- 初始化和扩容时容量给多少呢?
- 遍历时要不要保证数据的一致性呢?需要引入 Fail-Fast 机制吗?
通过类名我们大致可以猜测到 CopyOnWriteArrayList 类的实现思路:Copy-On-Write, 也就是写时复制策略;末尾的 ArrayList 表示数据存放在一个数组里。在对元素进行增删改时,先把现有的数据数组拷贝一份,然后增删改都在这个拷贝数组上进行,操作完成后再把原有的数据数组替换成新数组。这样就完成了更新操作。
但是这种写入时复制的方式必定会有一个问题,因为每次更新都是用一个新数组替换掉老的数组,如果不巧在更新时有一个线程正在读取数据,那么读取到的就是老数组中的老数据。其实这也是读写分离的思想,放弃数据的强一致性来换取性能的提升。
分析源码 ( JDK8 )
上面已经说了,CopyOnWriteArrayList 的思想是写时复制,读写分离,它的内部维护着一个使用 volatile 修饰的数组,用来存放元素数据。
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
CopyOnWriteArrayList 类中方法很多,这里不会一一介绍,下面会分析其中的几个常用的方法,这几个方法理解后基本就可以掌握 CopyOnWriteArrayList 的实现原理。
构造函数
CopyOnWriteArrayList 的构造函数一共有三个,一个是无参构造,直接初始化数组长度为0;另外两个传入一个集合或者数组作为参数,然后会把集合或者数组中的元素直接提取出来赋值给 CopyOnWriteArrayList 内部维护的数组。
// 直接初始化一个长度为 0 的数组
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
// 传入一个集合,提取集合中的元素赋值到 CopyOnWriteArrayList 数组
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] es;
if (c.getClass() == CopyOnWriteArrayList.class)
es = ((CopyOnWriteArrayList<?>)c).getArray();
else {
es = c.toArray();
if (c.getClass() != java.util.ArrayList.class)
es = Arrays.copyOf(es, es.length, Object[].class);
}
setArray(es);
}
// 传入一个数组,数组元素提取后赋值到 CopyOnWriteArrayList 数组
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
构造函数是实例创建时调用的,没有线程安全问题,所以构造方法都是简单的赋值操作,没有特殊的逻辑处理。
新增元素
元素新增根据入参的不同有好几个,但是原理都是一样的,所以下面只贴出了 add(E e ) 的实现方式,是通过一个 ReentrantLock 锁保证线程安全的。
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁
try {
Object[] elements = getArray(); // 获取数据数组
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); // 拷贝一个数据数组,长度+1
newElements[len] = e; // 加入新元素
setArray(newElements); // 用新数组替换掉老数组
return true;
} finally {
lock.unlock();
}
}
具体步骤:
- 加锁,获取目前的数据数组开始操作(加锁保证了同一时刻只有一个线程进行增加/删除/修改操作)。
- 拷贝目前的数据数组,且长度增加一。
- 新数组中放入新的元素。
- 用新数组替换掉老的数组。
- finally 释放锁。
由于每次 add 时容量只增加了1,所以每次增加时都要创建新的数组进行数据复制,操作完成后再替换掉老的数据,这必然会降低数据新增时候的性能。下面通过一个简单的例子测试 CopyOnWriteArrayList 、Vector、ArrayList 的新增和查询性能。
public static void main(String[] args) {
CopyOnWriteArrayList<Object> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
Vector vector = new Vector<>();
ArrayList arrayList = new ArrayList();
add(copyOnWriteArrayList);
add(vector);
add(arrayList);
get(copyOnWriteArrayList);
get(vector);
get(arrayList);
}
public static void add(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
list.add(i);
}
long end = System.currentTimeMillis();
System.out.println(list.getClass().getName() + ".size=" + list.size() + ",add耗时:" + (end - start) + "ms");
}
public static void get(List list) {
long start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
Object object = list.get(i);
}
long end = System.currentTimeMillis();
System.out.println(list.getClass().getName() + ".size=" + list.size() + ",get耗时:" + (end - start) + "ms");
}
从测得的结果中可以看到 CopyOnWriteArrayList 的新增耗时最久,其次是加锁的 Vector(Vector 的扩容默认是两倍)。而在获取时最快的是线程不安全的 ArrayList,其次是 CopyOnWriteArrayList,而 Vector 因为 Get 时加锁,性能最低。
java.util.concurrent.CopyOnWriteArrayList.size=100000,add耗时:2756ms
java.util.Vector.size=100000,add耗时:4ms
java.util.ArrayList.size=100000,add耗时:3ms
java.util.concurrent.CopyOnWriteArrayList.size=100000,get耗时:4ms
java.util.Vector.size=100000,get耗时:5ms
java.util.ArrayList.size=100000,get耗时:2ms
修改元素
修改元素和新增元素的思想是一致的,通过 ReentrantLock 锁保证线程安全性,实现代码也比较简单,本来不准备写进来的,但是在看源码时发现一个非常有意思的地方,看下面的代码。
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock(); //加锁
try {
Object[] elements = getArray(); // 获取老数组
E oldValue = get(elements, index); // 获取指定位置元素
if (oldValue != element) { // 新老元素是否相等,不相等
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len); // 复制老数组
newElements[index] = element; // 指定位置赋新值
setArray(newElements); // 替换掉老数组
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements); // 有意思的地方来了
}
return oldValue;
} finally {
lock.unlock();
}
}
通过源码可以看到在修改元素前会先比较修改前后的值是否相等,而在相等的情况下,依旧 setArray(elements); 这就很奇妙了,到底是为什么呢?想了解其中的原因需要了解下 volatile 的特殊作用,通过下面这个代码例子说明。
// initial conditions
int nonVolatileField = 0;
CopyOnWriteArrayList<String> list = /* a single String */
// Thread 1
nonVolatileField = 1; // (1)
list.set(0, "x"); // (2)
// Thread 2
String s = list.get(0); // (3)
if (s == "x") {
int localVar = nonVolatileField; // (4)
}
// 例子来自:https://stackoverflow.com/questions/28772539/why-setarray-method-call-required-in-copyonwritearraylist
要想理解例子中的特殊之处,首先你要知道 volatile 可以防止指令重排,其次要了解 happens-before 机制。说简单点就是它们可以保证代码的执行前后顺序。
比如上面例子中的代码,1 会在 2 之前执行,3 会在 4 之前执行,这都没有疑问。还有一条是 volatile 修饰的属性写会在读之前执行,所以 2会在 3 之前执行。而执行顺序还存在传递性。所以最终 1 会在 4 之前执行。这样 4 获取到的值就是步骤 1 为 nonVolatileField 赋的值。如果 CopyOnWriteArrayList 中的 set 方法内没有为相同的值进行 setArray,那么上面说的这些就都不存在了。
删除元素
remove 删除元素方法一共有三个,这里只看public E remove(int index) 方法,原理都是类似的。
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock(); // 加锁
try {
Object[] elements = getArray(); // 获取数据数组
int len = elements.length;
E oldValue = get(elements, index); // 获取要删除的元素
int numMoved = len - index - 1;
if (numMoved == 0) // 是否末尾
setArray(Arrays.copyOf(elements, len - 1)); // 数据数组减去末尾元素
else {
Object[] newElements = new Object[len - 1]; // 把要删除的数据的前后元素分别拷贝到新数组
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements); // 使用新数组替换老数组
}
return oldValue;
} finally {
lock.unlock(); // 解锁
}
}
代码还是很简单的,使用 ReentrantLock 独占锁保证操作的线程安全性,然后使用删除元素后的剩余数组元素拷贝到新数组,使用新数组替换老数组完成元素删除,最后释放锁返回。
获取元素
获取下标为 index 的元素,如果元素不存在,会抛出IndexOutOfBoundsException 异常。
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
首先看到这里是没有任何的加锁操作的,而获取指定位置的元素又分为了两个步骤:
- getArray() 获取数据数组。
- get(Object[] a, int index) 返回指定位置的元素。
很有可能在第一步执行完成之后,步骤二执行之前,有线程对数组进行了更新操作。通过上面的分析我们知道更新会生成一个新的数组,而我们第一步已经获取了老数组,所以我们在进行 get 时依旧在老数组上进行,也就是说另一个线程的更新结果没有对我们的本次 get 生效。这也是上面提到的弱一致性问题。
迭代器的弱一致性
List<String> list = new CopyOnWriteArrayList<>();
list.add("www.wdbyte.com");
list.add("未读代码");
Iterator<String> iterator = list.iterator();
list.add("java");
while (iterator.hasNext()) {
String next = iterator.next();
System.out.println(next);
}
现在 List 中添加了元素 www.wdbyte.com 和 未读代码,在拿到迭代器对象后,又添加了新元素 java ,可以看到遍历的结果没有报错也没有输出 java 。也就是说拿到迭代器对象后,元素的更新不可见。
www.wdbyte.com
未读代码
这是为什么呢?要先从CopyOnWriteArrayList 的 iterator() 方法的实现看起。
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
static final class COWIterator<E> implements ListIterator<E> {
/** Snapshot of the array */
private final Object[] snapshot;
/** Index of element to be returned by subsequent call to next. */
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
......
可以看到在获取迭代器时,先 getArray() 拿到了数据数组 然后传入到 COWIterator 构造器中,接着赋值给了COWIterator 中的 snapshot 属性,结合上面的分析结果,可以知道每次更新都会产生新的数组,而这里使用的依旧是老数组,所以更新操作不可见,也就是上面多次提到的弱一致性。
新版变化
上面的源码分析都是基于 JDK 8 进行的。写文章时顺便看了下新版的实现方式有没有变化,还真的有挺大的改变,主要体现在加锁的方式上,或许是因为 JVM 后来引入了 synchronized 锁升级策略,让 synchronized 性能有了不少提升,所以用了 synchronized 锁替换了老的 ReentrantLock 锁。
新增:
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1);
es[len] = e;
setArray(es);
return true;
}
}
修改:
public E set(int index, E element) {
synchronized (lock) {
Object[] es = getArray();
E oldValue = elementAt(es, index);
if (oldValue != element) {
es = es.clone();
es[index] = element;
}
// Ensure volatile write semantics even when oldvalue == element
setArray(es);
return oldValue;
}
}
总结
通过上面的分析,得到下面几点关于 CopyOnWriteArrayList 的总结。
- CopyOnWriteArrayList 采用读写分离,写时复制方式实现线程安全,具有弱一致性。
- CopyOnWriteArrayList 因为每次写入时都要扩容复制数组,写入性能不佳。
- CopyOnWriteArrayList 在修改元素时,为了保证 volatile 语义,即使元素没有任何变化也会重新赋值,
- 在高版 JDK 中,得益于 synchronized 锁升级策略, CopyOnWriteArrayList 的加锁方式采用了 synchronized。
参考:
- Why setArray() method call required in CopyOnWriteArrayList.
- What does volatile do?
http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html#volatile
JDK 源码分析系列文章
- 集合 - 最通俗易懂的 HashMap 源码分析解读
- 集合 - 还不懂 ConcurrentHashMap ?这份源码分析了解一下
- 集合 - ArrayList和LinkedList如何实现的?我看你还有机会!
最后的话
文章已经收录在 Github.com/niumoo/JavaNotes ,欢迎Star和指教。更有一线大厂面试点,Java程序员需要掌握的核心知识等文章,也整理了很多我的文字,欢迎 Star 和完善,希望我们一起变得优秀。
文章有帮助可以点个「赞」或「分享」,都是支持,我都喜欢!
文章每周持续更新,要实时关注我更新的文章以及分享的干货,可以关注「 未读代码 」公众号或者我的博客。
