搜索老郭的单口相声,打开检查模式,刷新
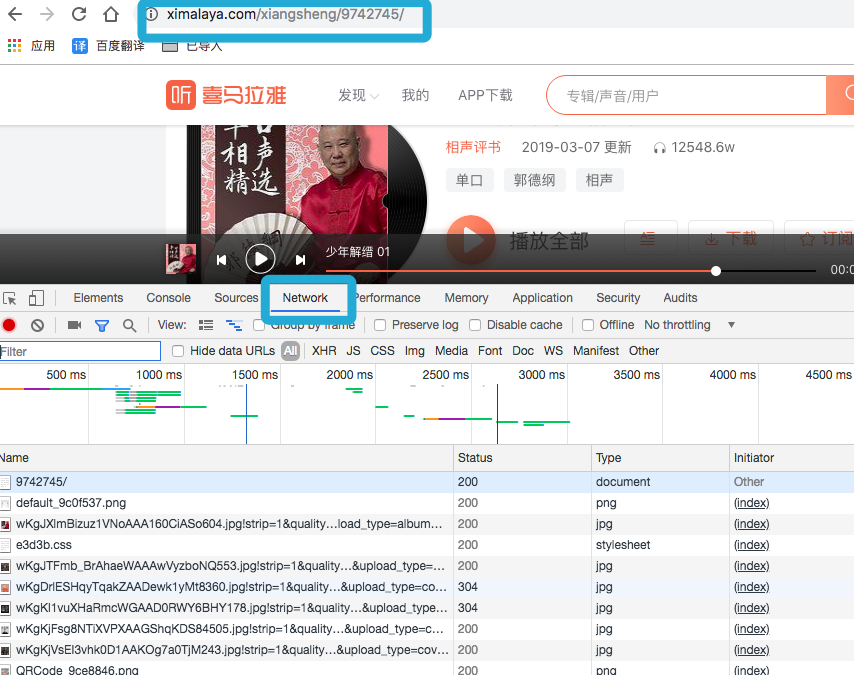
没有什么有价值的东东, 不过....清掉内容, 点击一个相声,再看看有些什么
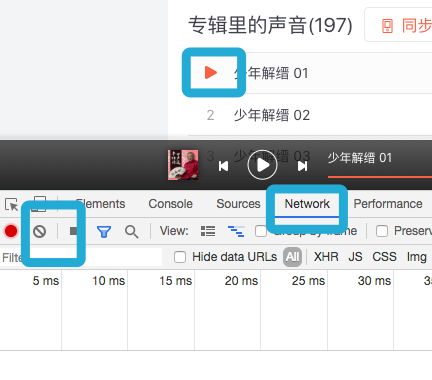
是不是发现了些什么
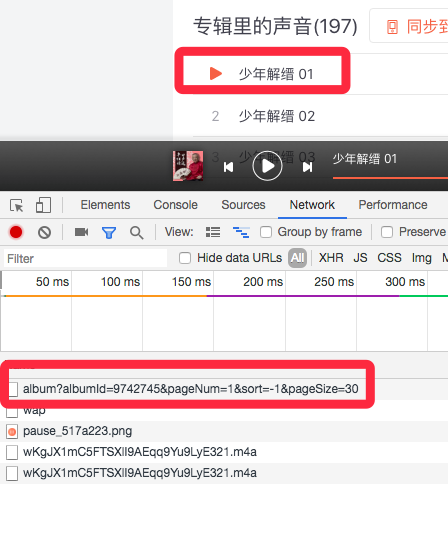
我们来点击这个看看, 首先看一下headers, 这个url是不是看起来很顺眼
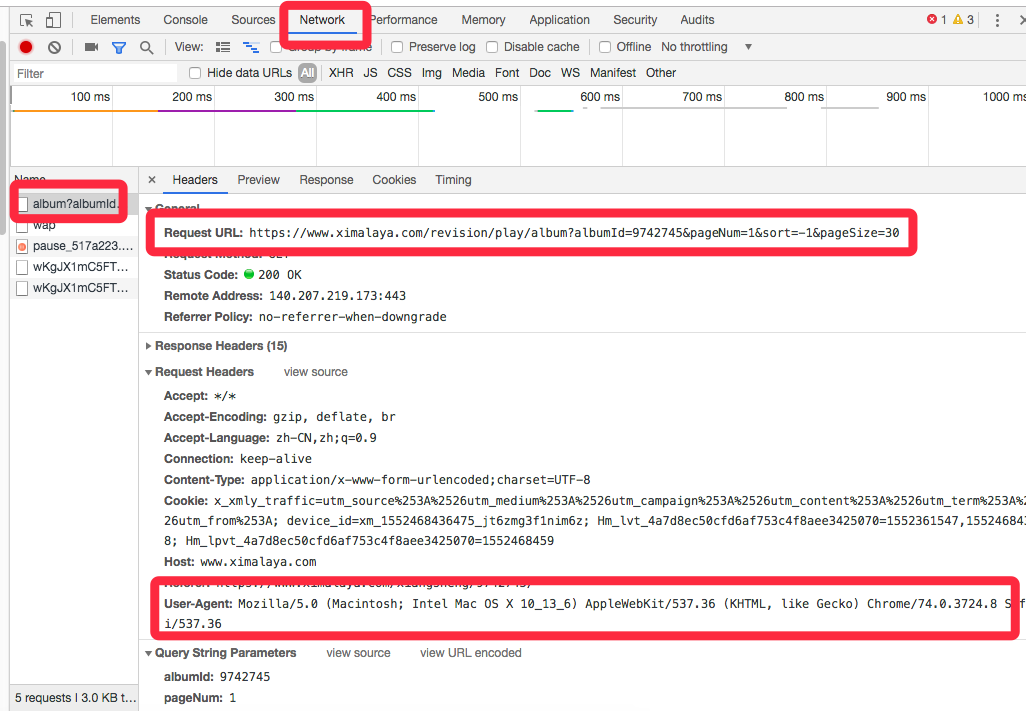
再来preview, 或者打开那个Request URL
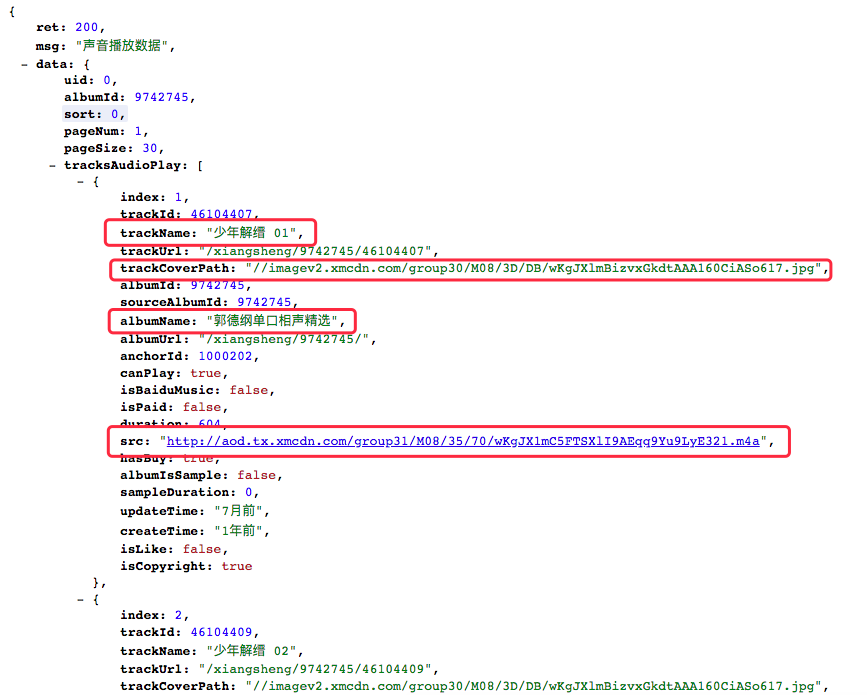
怎么样,这个就是网站提供的数据接口了,有了这个接口,我们获取文件就相当方便了
# -*- coding:utf-8 -*- # Author : Niuli # Data : 2019-03-13 16:08 import requests,os # 数据来源 URL = 'https://www.ximalaya.com/revision/play/album?albumId=9742745&pageNum=1&sort=-1&pageSize=30' # 伪造请求头 XMLY_HEADER = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36'} res = requests.get(URL,headers=XMLY_HEADER) res_json = res.json() play_list = res_json['data']['tracksAudioPlay'] ALL_PATH = play_list[0]['albumName'] # 创建本地专辑文件夹 os.system(f'mkdir -p {ALL_PATH}/MUSIC') os.system(f'mkdir -p {ALL_PATH}/COVER') MUSIC_PATH = ALL_PATH + '/MUSIC' COVER_PATH = ALL_PATH + '/COVER' for i in play_list: # print(i['trackName']) # print(i['trackCoverPath']) # print(i['src']) # 获取文件信息 (标题 音乐路径 图片路径) url_title = i['trackName'] url_music_path = i['src'] url_cover_path = 'https:' + i['trackCoverPath'] # 下载保存音乐文件 music_file = requests.get(url_music_path) # 下载文件 local_music_path = os.path.join(MUSIC_PATH,f'{url_title}.mp3') # 保存路径+文件名+后缀 # 写入音乐文件 with open(local_music_path,'wb') as f: f.write(music_file.content) # 下载保存图片信息 cover_file = requests.get(url_cover_path) # 下载文件 local_cover_path = os.path.join(COVER_PATH,f'{url_title}.jpg') # 保存路径+文件名+后缀 # 写入图片文件 with open(local_cover_path, 'wb') as f: f.write(cover_file.content)
同理可以获取其他音频咯