Zipkin是一种分布式跟踪系统。 它有助于收集解决微服务架构中的延迟问题所需的时序数据。 它管理这些数据的收集和查找。 Zipkin的设计基于Google Dapper论文。
应用程序用于向Zipkin报告时序数据。 Zipkin UI还提供了一个依赖关系图,显示了每个应用程序通过的跟踪请求数。 如果要解决延迟问题或错误,可以根据应用程序,跟踪长度,注释或时间戳对所有跟踪进行筛选或排序。 选择跟踪后,您可以看到每个跨度所需的总跟踪时间百分比,从而可以识别问题应用程序。
Zipkin最初是为了在Cassandra上存储数据而构建的,因为Cassandra是可扩展的,具有灵活的模式,并且在Twitter中大量使用。 但是,我们使这个组件可插拔。 除了Cassandra,我们原生支持ElasticSearch和MySQL。 其他后端可能会作为第三方扩展提供。
无论您如何启动Zipkin,请浏览http:// ip:9411以查找跟踪!(ZipkinServer默认端口为9411)
ZipkinServer
zipkinserver是将数据存储到内存中的。重启或发生崩溃就会导致历史数据丢失.(这种只适合快速入门和演示)
https://cloud.spring.io/spring-cloud-static/Dalston.SR4/multi/multi__span_data_as_messages.html#_zipkin_consumer 基于消息和mysql存储的,后面也会介绍
1.Maven
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>919.spring-cloud-zipkin-server</groupId> <artifactId>service-provide</artifactId> <packaging>jar</packaging> <version>0.0.1-SNAPSHOT</version> <name>spring-cloud Maven Webapp</name> <url>http://maven.apache.org</url> <!--springboot采用1.5.x 对应springcloud版本为 Dalston --> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.2.RELEASE</version> <relativePath /> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> <spring-cloud.version>Dalston.RELEASE</spring-cloud.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!-- 修改后立即生效,热部署 --> <dependency> <groupId>org.springframework</groupId> <artifactId>springloaded</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> </dependency> <!--zipkin相关依赖 --> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <!-- 这样变成可执行的jar --> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
2.启动类
3.application.properties
server.port=9411
#注册中心地址
eureka.client.serviceUrl.defaultZone=http://testhost:8000/eureka/,http://testhost2:8001/eureka/
#把客户端的检测检测交给actuator来完成
eureka.client.healthcheck.enabled=true
spring.application.name=zipkin-server
![]()
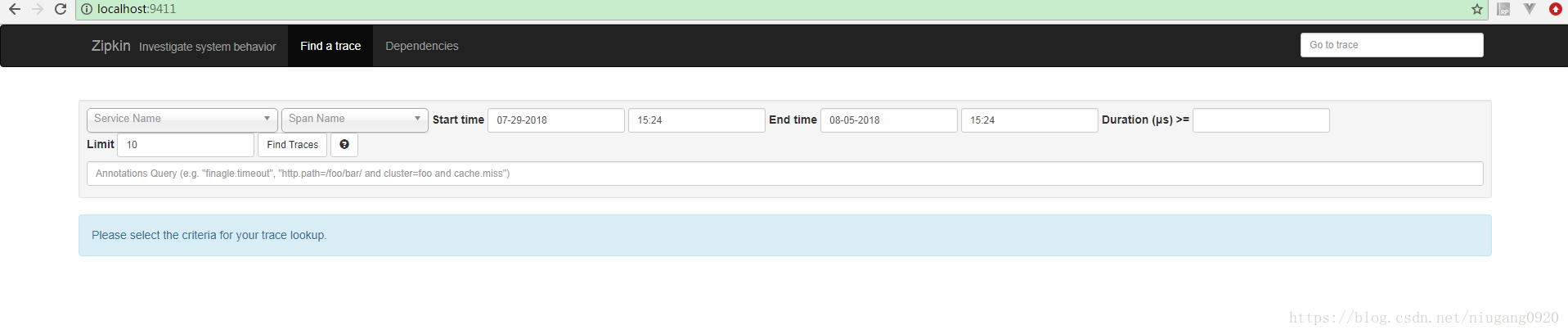
Zipkin整合微服务
1.maven
<!-- zipkin在微服务中 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
2.application.properties
spring.zipkin.base-url=http://localhost:9411/ spring.sleuth.sampler.percentage=1.0
spring.zipkin.base-url:指定zipkin的地址
spring.sleuth.sampler.percentage:指定徐采集的请求百分百,默认值是0.1,即10%。这是因为分布式系统中,数据量可能会非常大,因此采样非常重要。
![]()
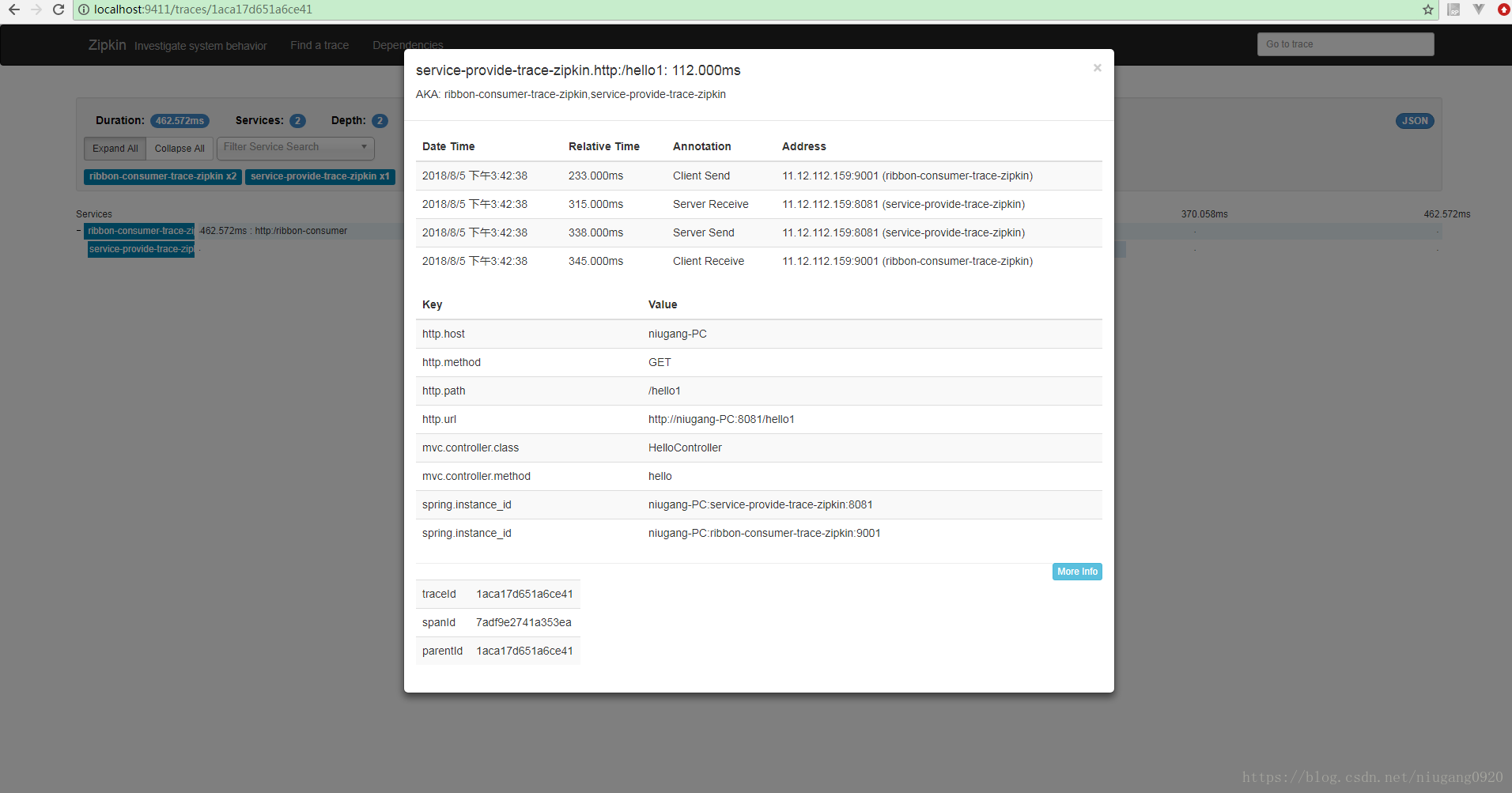
Zipkin还有主语分析微服务间的依赖关系。
![]()

微信公众号
